 GPU革命与CUDA硬件解析
GPU革命与CUDA硬件解析








 本文探讨了GPU作为并行计算资源的革命性意义,并详细分析了NVIDIA GPU的硬件架构,包括Multiprocessor、SIMD架构及内存布局等关键组成部分。
本文探讨了GPU作为并行计算资源的革命性意义,并详细分析了NVIDIA GPU的硬件架构,包括Multiprocessor、SIMD架构及内存布局等关键组成部分。
CUDA硬件实现分析(一)------安营扎寨
------GPU的革命
序言:有个不会写计算机程序的朋友看了blog,问我,这个GPU也能当故事写吗?我觉得或许GPU真的算是一场革命吧,他的发展或许在酝酿中,不过到08年底,09年初,一定会有一场轰轰烈烈的竞争。那个时候或许从OS层面都会给人带来震撼。如果把CPU的多core看成由几个特种兵组成的,每个特种兵都手里面都拿着8杆枪(SSE)。那么GPU可以看成农民起义……一上来就是成百上千的人,虽然单兵作战能力比不上CPU的单个core,但是毕竟人数众多。就现在GPU的性能,在并行运算上如果不考虑double硬件的成本,已经早早超过CPU的并行运算能力。这或许就是一场革命,这次革命不知是简简单单的GPU和CPU的转变,而是并行算法和串行算法的竞争。并行算法虽然研究到现在已经有很多年,但是真正的实际运用,离我们普通大众还是差很远。但是GPU,并行计算的出现,一下子把我们和并行计算的距离拉近了好多。现在在学校里面学习计算机的时候都是从串行算法开始,养成了很多固定的串行思维。当遇到问题并行划分的时候,就还带着串行的思想,那就不好了:)
正文:前面我们已经说到线程的一些概念,但是这些概念都是软环节的。我们常常会听到某某单位说他们的软硬件配置如何如何的好。软件再好,每个士兵都是可造之才,但是如果硬件条件跟不上,也没他们的勇武之地。就像国内做过一些跳槽原因的统计,很多人已经跳槽都是为了高工资,但实际统计结果表明,很多人都觉得在以前那个公司里面学不到东西,或者说得不到发挥自己长处的地方。那就得看公司有没有这样的机会让你发挥你的能力了。看到这里,扯远了~很多人都看得不耐烦了……书接上回《 CUDA 线程执行模型分析(二)大军未动粮草先行------GPU的革命》。已经讲到CUDA在线程模型是一个什么样子,经过几天的吸收,也应该在脑子里面有一些印象了。但是你会问一个问题,我们是不是可以开无数个线程来执行啦?或许招兵的人都想找到很多很多的人,但是你得也考虑一下你的粮食有多少,军营有多大。在这么我们得讨论一下现在的支持CUDA的nvidia的显卡现在的硬件情况。
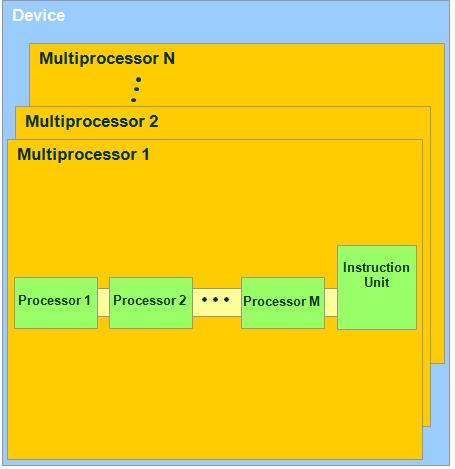 空洞的讲解或许还是没怎么又说服力,下面以G80为例子。
空洞的讲解或许还是没怎么又说服力,下面以G80为例子。
1. G80里面有16个Multiprocessor.
2. 每个Multiprocessor都有一组(G80里面是8个)32位的Processor(每个Processor都是SIMD架构,什么叫SIMD架构:军训的时候,大家都到了食堂,不是像在学校里面,每个人那自己的碗筷就三三俩俩的去吃饭,那可要讲究纪律,啥叫纪律,一群人站在桌子面前,连长没发话,谁也不敢坐下来……连长一声令下:“坐下”。所有的人才按照敢坐下来,也是同时坐下来- -!要是谁没有同步坐下来,那就惨了- -!再来一次,一定要是同步坐下去的,都能听到声的,咵!恨不得把板凳给坐碎了------还是部队的东西结实,兄弟们怎么坐到军训结束只有坐坏屁股的,没有听说凳子坐坏的- -!所以啊,爱惜公物就是爱惜自己。记住了吧,这就是SIMD:Single Instruction Multiple Data 。 )还有共用的Instruction Unit(这玩儿就不用翻译是啥了吧~看SIMD,自己理解去)。在G80里面有两个SFU模块。
3. 每一个时钟周期内,按照warp(这玩儿咋翻译啦?就理解为运行的时候,一个block里面一起运行的thread,例如block里面有512个thread,但是每次只有32个thread在运行,那么这32个thread就是一个运行的warp组- -! 还好不是rap- -!俺就真没法解释了)
4. 每一个warp里面包含的thread数量是有限的,现在的规定是32个。将来不知道会不会有变化?不知道,这个只有CUDA开发人员知道了。
我们还是按照我们的既定方式学习吧~看图说话- -!接下来又是一张图:
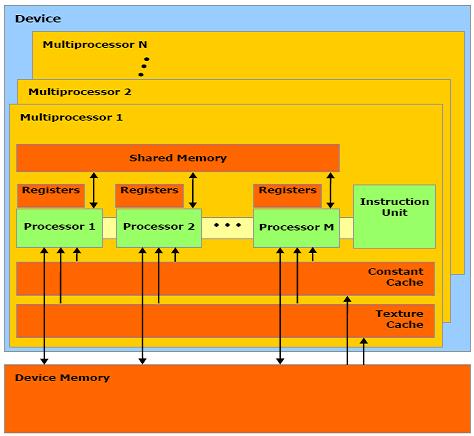
刚才我们已经说到了硬件上的处理器的模型,现在我们来看看内存吧。前面的章节我们已经讲到了内存的register,local,shared,constant,texture,global,现在看到对应的硬件的位置了吧?哦,对了,有人会问,local和global跑那里去了,你看看,是不是多了一个Device Memory嘛。Local和Global 都是在Device Memory上的。只是在线程模型运行的时候,为了方便说明线程的模型,把它单独划分出来好说明。其实Constant和Texture都是在Device Memory里面的,但是人家是只读的Cache,所以比Global和local要快一些。不过Cache和shared Memory比起来,又显得慢一些了。
硬件的架构差不多就是这么多。如果还不是很清楚,我们再讲讲军营的生活。还是讲吃食堂吃饭吧(回想起大学的时候和几个好朋友一起成立了一个编程爱好者协会……结果后来变成了好吃协会- -!)。由于我们现在的连队人数众多,一个grid里面就可以有65535个thread,所以一下子让这么多人一起吃饭,是不可能的。我们有好多个grid怎么办?所以每次Device(就是显卡)只处理一个grid。但是每个grid里面又有那么多人。一来是咱们地方小,不能容纳那么多人一起吃饭,而来是也没必要再建立那么多食堂。大家可以轮流吃,早吃的早走,晚来的也晚不了多久。
这次是Grid1先到达食堂,然后他把士兵分成了几个block,(我们上次已经讲过的,block和grid的关系,应该还记得把)但是现在桌子还是少,为了大家不乱起来,每个block的人就指定到某一个multiprocessor(一个周期只能容纳32个人一起用餐)哪里。
这个block1的人就围着multiprocessor1这张桌子坐,但是这张桌子也不是太大,所以block里面的人又分成32个人一组(warp)来吃饭。那如果这个block没有32个人,就占不完这张桌子,所以一个multiprocessor又可以让别的block的thread一起来用餐。
因为一次就把所有的register和shared memory分配给了所有的block的所有的thread。所以怎么样合理的少用register和shared memory就可以同时让更多的thread得到处理。
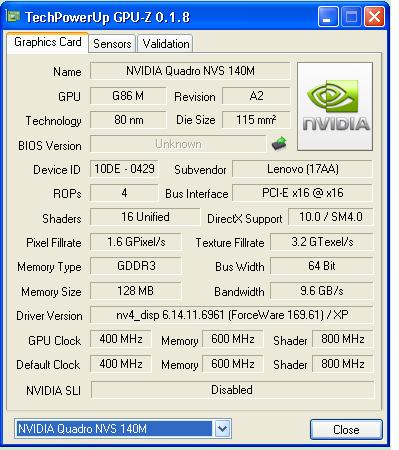
讲了这么多,怎么来看自己的显卡那片军营如何拉?下面给出两种方法,一种是用一个小软件,GPU-Z的工具,这个工具可以得到很多显卡的参数,这个可以上网搜索到。
第二种方法是用CUDA的命令,这个只是针对支持CUDA的显卡的,下面给一段代码:
/********************************************************************
* InitCUDA.cu
* This is a init CUDA of the CUDA program.
*********************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
/************************************************************************/
/* Init CUDA */
/************************************************************************/
bool InitCUDA(void)
{
int count = 0;
int i = 0;
cudaGetDeviceCount(&count);
if(count == 0) {
fprintf(stderr, "There is no device./n");
return false;
}
for(i = 0; i < count; i++) {
cudaDeviceProp prop;
if(cudaGetDeviceProperties(&prop, i) == cudaSuccess)
{
printf("name:%s/n", prop.name);
printf("totalGlobalMem:%u/n", prop.totalGlobalMem);
printf("sharedMemPerBlock:%u/n", prop.sharedMemPerBlock);
printf("regsPerBlock:%d/n", prop.regsPerBlock);
printf("warpSize:%d/n", prop.warpSize);
printf("memPitch:%u/n", prop.memPitch);
printf("maxThreadsPerBlock:%d/n", prop.maxThreadsPerBlock);
printf("maxThreadsDim:x %d, y %d, z %d/n", prop.maxThreadsDim[0],prop.maxThreadsDim[1],prop.maxThreadsDim[2]);
printf("maxGridSize:x %d, y %d, z %d/n", prop.maxGridSize[0],prop.maxGridSize[0],prop.maxGridSize[0]);
printf("totalConstMem:%u/n", prop.totalConstMem);
printf("major:%d/n", prop.major);
printf("minor:%d/n", prop.minor);
printf("clockRate:%d/n", prop.clockRate);
printf("textureAlignment:%u/n", prop.textureAlignment);
if(prop.major >= 1) {
break;
}
}
}
if(i == count) {
fprintf(stderr, "There is no device supporting CUDA 1.x./n");
return false;
}
cudaSetDevice(i);
printf("CUDA initialized./n");
return true;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









