






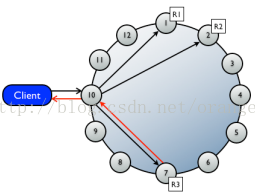
client connects to a node and issues a read or write request, that node serves as the coordinator for that
particular client operation.
The job of the coordinator is to act as a proxy between the client application and the nodes (or replicas)
that own the data being requested. The coordinator determines which nodes in the ring should get the
request based on the cluster configured partitioner and replica placement strategy.
About write requests
The coordinator sends a write request to all replicas that own the row being written. As long as all replica
nodes are up and available, they will get the write regardless of the consistency level specified by the
client. The write consistency level determines how many replica nodes must respond with a success
acknowledgment in order for the write to be considered successful. Success means that the data was
written to the commit log and the memtable as described in About writes.
For example, in a single data center 10 node cluster with a replication factor of 3, an incoming write will
go to all 3 nodes that own the requested row. If the write consistency level specified by the client is ONE,
the first node to complete the write responds back to the coordinator, which then proxies the success
message back to the client. A consistency level of ONE means that it is possible that 2 of the 3 replicas
could miss the write if they happened to be down at the time the request was made. If a replica misses
a write, Cassandra will make the row consistent later using one of its built-in repair mechanisms: hinted
handoff, read repair, or anti-entropy node repair.
That node forwards the write to all replicas of that row. It will respond back to the client once it receives a
write acknowledgment from the number of nodes specified by the consistency level. when a node writes
and responds, that means it has written to the commit log and puts the mutation into a memtable.
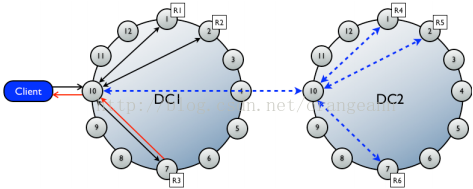
About multiple data center write requests
In multiple data center deployments, Cassandra optimizes write performance by choosing one
coordinator node in each remote data center to handle the requests to replicas within that data center.
The coordinator node contacted by the client application only needs to forward the write request to one
node in each remote data center.
If using a consistency level of ONE or LOCAL_QUORUM, only the nodes in the same data center as
the coordinator node must respond to the client request in order for the request to succeed. This way,
geographical latency does not impact client request response times.
About read requests
There are two types of read requests that a coordinator can send to a replica:
• A direct read request
• A background read repair request
The number of replicas contacted by a direct read request is determined by the consistency level
specified by the client. Background read repair requests are sent to any additional replicas that did not
receive a direct request. Read repair requests ensure that the requested row is made consistent on all
replicas.
Thus, the coordinator first contacts the replicas specified by the consistency level. The coordinator sends
these requests to the replicas that are currently responding the fastest. The nodes contacted respond
with the requested data; if multiple nodes are contacted, the rows from each replica are compared in
memory to see if they are consistent. If they are not, then the replica that has the most recent data (based
on the timestamp) is used by the coordinator to forward the result back to the client.
To ensure that all replicas have the most recent version of frequently-read data, the coordinator also
contacts and compares the data from all the remaining replicas that own the row in the background. If
the replicas are inconsistent, the coordinator issues writes to the out-of-date replicas to update the row
to the most recent values. This process is known as read repair. Read repair can be configured per table
(using read_repair_chance), and is enabled by default.
For example, in a cluster with a replication factor of 3, and a read consistency level of QUORUM, 2 of the 3
replicas for the given row are contacted to fulfill the read request. Supposing the contacted replicas had
different versions of the row, the replica with the most recent version would return the requested data.
In the background, the third replica is checked for consistency with the first two, and if needed, the most
recent replica issues a write to the out-of-date replicas.















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









