









hadoop版本:
Apache Hadoop 2.6.0
instance的role type主要有3个,namenode,secondary namenode和data node;其他的还有balancer,backup node等
1.HDFS存储在本地操作系统磁盘的目录结构
NameNode:
/data/dfs/nn/current
-rw-r--r-- 1 hdfs hdfs 322K Apr 17 08:41 edits_0000000000007093753-0000000000007096223
-rw-r--r-- 1 hdfs hdfs 338K Apr 17 09:41 edits_0000000000007096224-0000000000007098803
-rw-r--r-- 1 hdfs hdfs 361K Apr 17 10:41 edits_0000000000007098804-0000000000007101548
-rw-r--r-- 1 hdfs hdfs 1.0M Apr 17 11:13 edits_inprogress_0000000000007101549
-rw-r--r-- 1 hdfs hdfs 53M Apr 17 09:41 fsimage_0000000000007098803
-rw-r--r-- 1 hdfs hdfs 62 Apr 17 09:41 fsimage_0000000000007098803.md5
-rw-r--r-- 1 hdfs hdfs 53M Apr 17 10:41 fsimage_0000000000007101548
-rw-r--r-- 1 hdfs hdfs 62 Apr 17 10:41 fsimage_0000000000007101548.md5
-rw-r--r-- 1 hdfs hdfs 8 Apr 17 10:41 seen_txid
-rw-r--r-- 1 hdfs hdfs 173 Nov 13 12:05 VERSION
Secondary NameNode:
/data1/dfs/snn/current
-rw-r--r-- 1 hdfs hdfs 322K Apr 17 08:41 edits_0000000000007093753-0000000000007096223
-rw-r--r-- 1 hdfs hdfs 338K Apr 17 09:41 edits_0000000000007096224-0000000000007098803
-rw-r--r-- 1 hdfs hdfs 361K Apr 17 10:41 edits_0000000000007098804-0000000000007101548
-rw-r--r-- 1 hdfs hdfs 53M Apr 17 09:41 fsimage_0000000000007098803
-rw-r--r-- 1 hdfs hdfs 62 Apr 17 09:41 fsimage_0000000000007098803.md5
-rw-r--r-- 1 hdfs hdfs 53M Apr 17 10:41 fsimage_0000000000007101548
-rw-r--r-- 1 hdfs hdfs 62 Apr 17 10:41 fsimage_0000000000007101548.md5
-rw-r--r-- 1 hdfs hdfs 173 Apr 17 10:41 VERSION
2.NameNode中一共有4种文件:
edits_{x}_{y}:和fsimage已经merger过的
transaction记录文件,x为起始transaction记号,y为截止号
edits_inprogress_{y}:尚未和fsimage merger过的
transaction记录文件,
y为
transaction
截止号
fsimage_{y}:namenode的namespace存在本地的checkpoint文件,存储了y为
transaction
截止号;一般会有两个,文件生成时间间隔为设置的checkpoint生成间隔时间;
*NameNode上只有在启动时才会合并最新的fsimage_{y}和edits_inprogress_{y}文件
NameNode时序图:
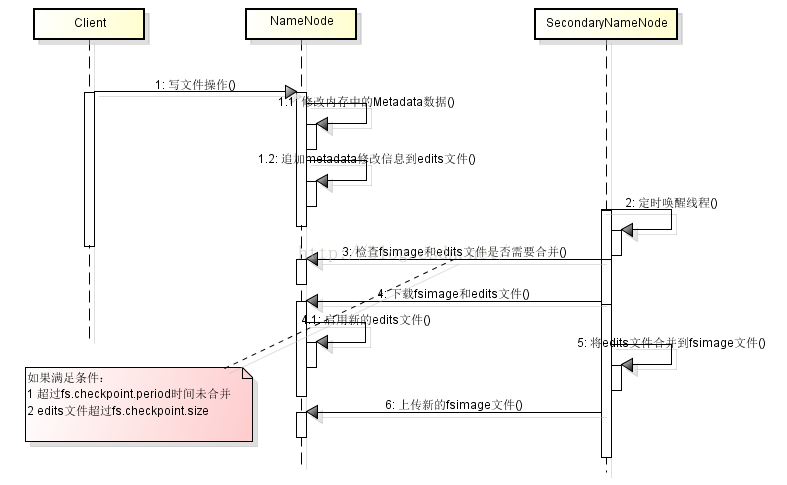
上图中第三步最新的配置为:
1.
fs.checkpoint.period, dfs.namenode.checkpoint.period:
The time between two periodic file system checkpoints.
2.
dfs.namenode.checkpoint.txns:
The number of transactions after which the NameNode or SecondaryNameNode will create a checkpoint of the namespace, regardless of whether the checkpoint period has expired.














 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









