







1.安装环境说明
- VMware 12
- ubuntukylin-15.10-desktop-amd64
- jdk1.8.0_73
- scala-2.10.5
- hadoop-2.6.0
- spark-1.6.0-bin-hadoop2.6
2.安装VMware
(略)
3.安装ubuntu
安装过程(略)
配置ubuntu
安装好一个后复制三个,分别为 work1,work2,work3
其中 work1为master,work2,work3为 slave
vim /etc/hosts
192.168.44.138 work1
192.168.44.139 work2
192.168.44.137 work3
为方便操作,修改每台机的名字分别为 work1 work2 work3
vim /etc/hostname
4.配置ssh无需密码登录
5.安装jdk
(安装过程略)
设置环境变量
vim /etc/profile
export JAVA_HOME=/usr/local/spark/jdk1.8.0_73
export PATH=
PATH:
{SCALA_HOME}/bin:
6.安装scala
(安装过程略)
vim /etc/profile
export SCALA_HOME=/usr/local/spark/scala-2.10.5
export PATH=
PATH:
{SCALA_HOME}/bin:
7.安装hadoop
(安装过程略)
vim /etc/profile
export HADOOP_HOME=/usr/local/spark/hadoop-2.6.0
export PATH=
PATH:
{HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
8.安装spark
(安装过程略)
vim /etc/profile
export SPARK_HOME=/usr/local/spark/spark-1.6.0-bin-hadoop2.6
export PATH=
PATH:
{SPARK_HOME}/bin:${SPARK_HOME}/sbin
7.配置hadoop集群
(1)配置etc/hadoop/hadoop-env.sh
设置java和hadoop的路径到环境变量中
export JAVA_HOME=/usr/local/spark/jdk1.8.0_73
export HADOOP_PREFIX=/usr/local/spark/hadoop-2.6.0
(2)配置etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://work1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/spark/hadoop-2.6.0/tmp</value>
</property>
</configuration>
(3)配置etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>work1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/spark/hadoop-2.6.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/spark/hadoop-2.6.0/dfs/data</value>
</property>
<property>
(4)配置etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6)配置etc/hadoop/yarn-env.sh
设置java路径
export JAVA_HOME=/usr/local/spark/jdk1.8.0_73
(7)配置etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>work1</value>
</property>
</configuration>
(8)配置slaves
work1
work2
work38.启动hadoop集群
格式化文件系统
启动 NameNode 和 DateNode
启动 ResourceManager 和 NodeManager
9.安装spark
配置环境变量
配置spark-env.sh
配置slaves
10.启动spark
启动 Master 节点
运行
start-master.sh
启动所有 Worker 节点
start-slaves.sh浏览器查看 Spark 集群信息
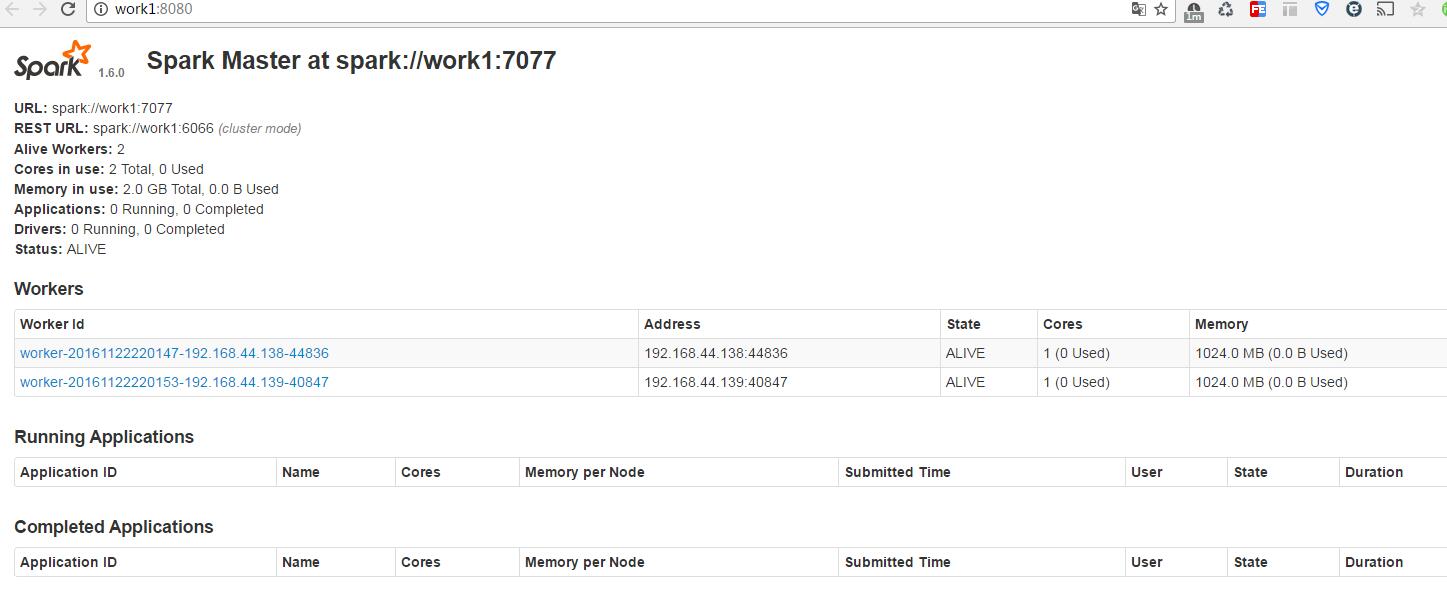
./start-history-server.sh
运行自带的例子
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://work1:7077 ./lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000wgyw
./bin/spark-submit \
–class
–master \
–deploy-mode \
–conf = \
… # other options
\
[application-arguments]
11.停止spark集群
停止 Master 节点
stop-master.sh 停止 Worker 节点
stop-slaves.sh停止 Hadoop 集群















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









