







-
在集群中安装Spark
这一步和之前的“01: Spark的安装与配置” 是一样的,所以那一步完成后就不必再做了。 -
配置环境变量
在master节点终端配置环境变量:
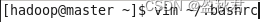
在.bashrc文件中增加:
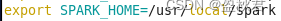

保存退出后,运行source命令使得配置生效:
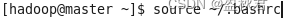
-
Spark配置
(1)在master节点上配置slaves文件
copy模板

在salves文件中设置Spark集群的Worker节点
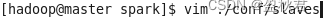
在文件中修改默认内容localhost为:

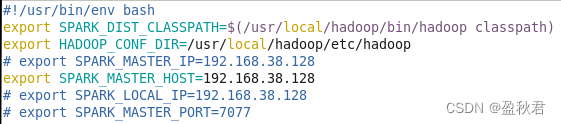
(2)在master节点配置spark-env.sh文件
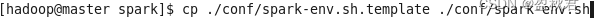
编辑
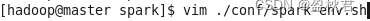
添加内容:
(3)配置slave节点
启动slave01和slave02节点,然后,在master节点执行如下命令,将master节点的/usr/local/spark文件夹复制到各个slave节点:

在slave01和slave02节点上分别执行如下命令(下面以slave01为例):


上一步如果出现没有使用sudo命令权限的提示,说明在配置Hadoop的Slave节点时漏掉了步骤,具体参考https://blog.csdn.net/lijun05/article/details/117935732,按照这个博客的第一步,配置Slave节点,然后就可以使用sudo命令了。

-
启动Spark
(1)启动master,slave01,slave02虚拟机,在master节点启动Hadoop集群
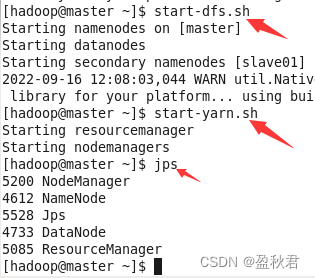
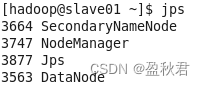
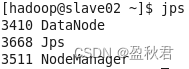
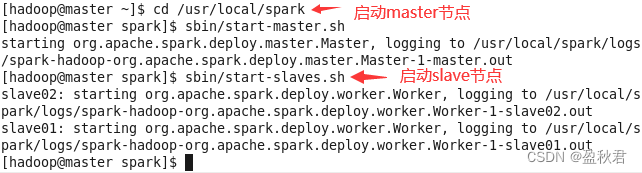
(2)在master节点上启动Spark集群
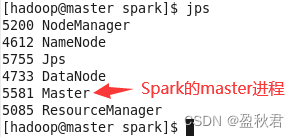
jps查看进程,可以看到启动的master和worker进程
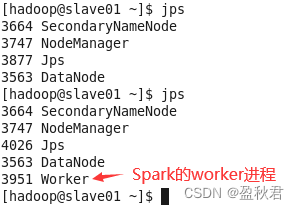
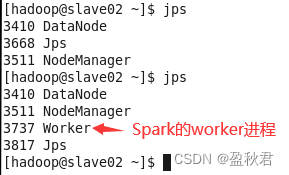
(3)在master节点上,通过浏览器查看集群信息有两个worker
http://master:8080
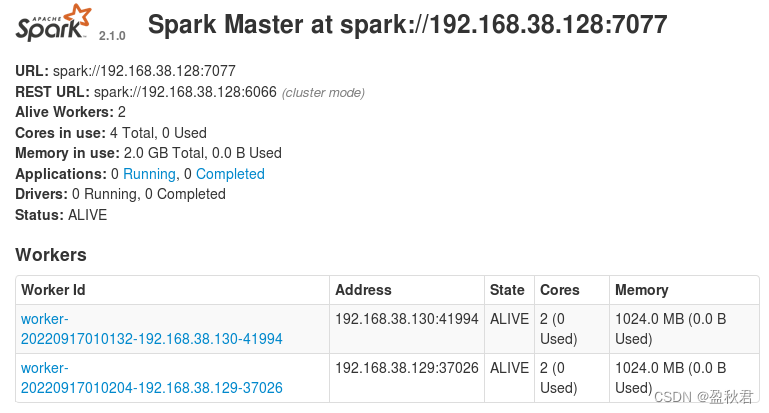
目前没有应用在运行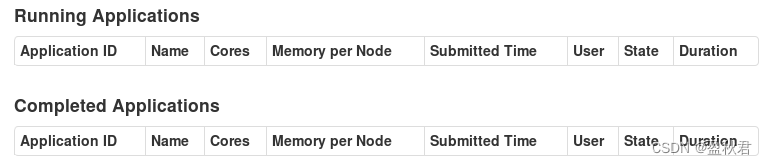
如果UI界面没有worker信息,查看slave节点的日志文件,会发现以下信息,这是因为网络防火墙没有关闭造成的。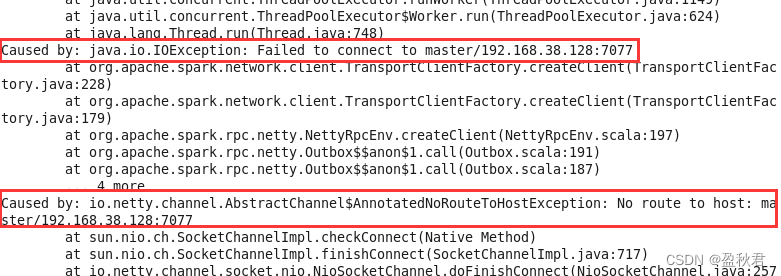
检查网络防火墙,发现都是打开状态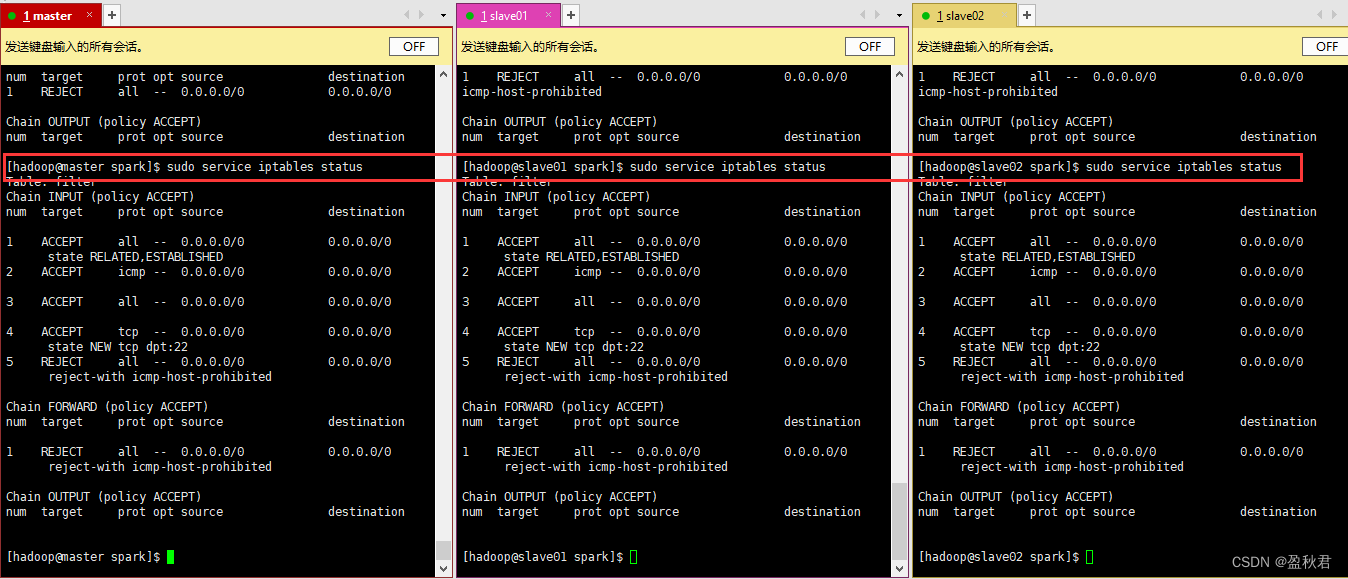 关闭防火墙之后,再次在master节点上,通过浏览器查看集群信息,可以看到worker信息
关闭防火墙之后,再次在master节点上,通过浏览器查看集群信息,可以看到worker信息
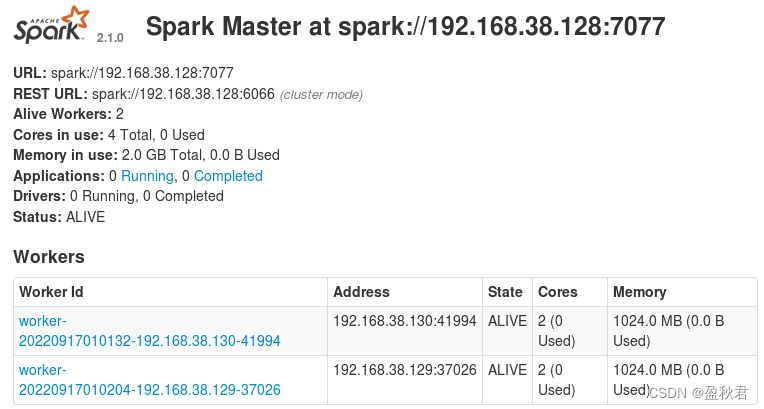
5. 关闭Spark
stop-master.sh
stop-slaves.sh
stop-yarn.sh
stop-dfs.sh














 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









