







计算密集型应用(CPU密集)
顾名思义就是应用需要非常多的CPU计算资源,I/O在很短的时间就可以完成,而 CPU 还有许多运算要处理。
在计算密集型应用中,线程池的大小应该等同于主机中 CPU 的数量。再添加更多线程将会打断请求的处理,因为线程的上下文切换也会延迟响应时间。非阻塞型 IO 应用将会是 CPU 密集型的,因为在请求得到处理的时候没有线程等待时间。
**结论:**对于CPU密集情况,当线程池大小为N+1时,通常能实现最优的利用率,(当计算密集型任务偶尔由于页缺失故障或者其他原因而暂停时,这个额外的线程也能够确保CPU的时钟周期不会被浪费)
IO等待应用(IO密集)
决定 IO 等待应用的线程池大小会由于依赖于下游系统的响应时间而变得更加复杂,因为一个线程在其他系统响应之前始终是阻塞的。我们不得不去增加线程的数量以提高 CPU 利用率。
对于IO密集型的应用,就很好理解了,我们现在做的开发大部分涉及到大量的网络传输,不仅如此,与数据库,与缓存间的交互也涉及到IO,一旦发生IO,线程就会处于等待状态,当IO结束,数据准备好后,线程才会继续执行。
**结论:**对于IO密集型的应用,我们可以多设置一些线程池中线程的数量,这样就能让在等待IO的这段时间内,线程可以去做其它事,提高并发处理效率。
原则:线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
对于IO密集情况,虽然有一个利特尔法则,但是确定一个IO密集型应用的最佳线程池大小是一个十分困难的工作,通常需要很多次的实验才能得出结论
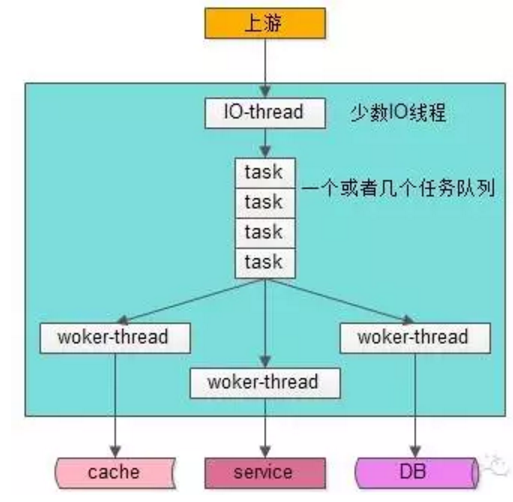
- 有少数几个IO线程监听上游发过来的请求,并进行收发包(生产者)。一般是主线程监听连接,并接收数据,拆包解包分配任务给工作线程。
- 有一个或者多个任务队列,作为IO线程与Worker线程异步解耦的数据传输通道数据缓冲(临界资源)
- 有多个工作线程构成线程池执行真正的任务(消费者),然后工作线程处理完通过数据缓冲通道给发送线程统一发送。
这个线程模型应用很广,符合大部分场景,这个线程模型的特点是,工作线程内部是同步阻塞执行任务的(比如查询Redis等待结果,比如操作MySQL等待结果),因此可以通过增加Worker线程数来增加并发能力,那么“该模型Worker线程数设置为多少能达到最大的并发”。可以看出来这里的影响因素,IO线程是生产者依赖的cpu计算速度拆包解包,通过数据缓冲交给线程池,线程池是消费者依赖的是Redis或者MySQL阻塞的时间,要平衡生产者的生产速度和消费者的消费速度,就得通过大量的实验来平衡充分的利用cpu。
那么我们可以大胆的猜想:
对于包含IO操作或者其他阻塞操作的任务,由于线程并不会一直执行,因此线程池的规模应该更大,要正确的设置线程池的大小,你必须估算出任务的等待时间和计算时间的比值。
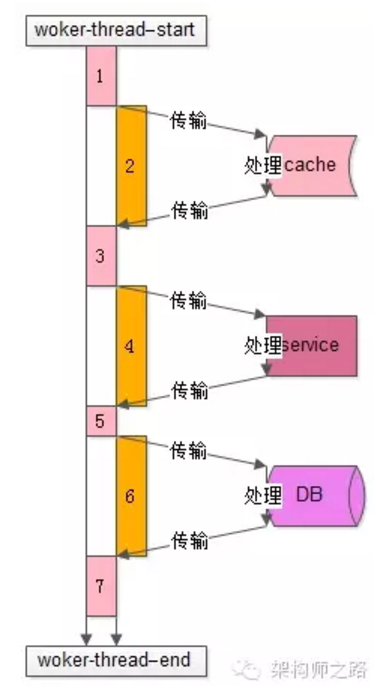
这是一个典型的工作线程的处理过程,从开始处理start到结束处理end,该任务的处理共有7个步骤: - 从工作队列里拿出任务,进行一些本地初始化计算,例如协议分析、参数解析、参数校验等
- 访问cache拿一些数据
- 拿到cache里的数据后,再进行一些本地计算,这些计算和业务逻辑相关
- 通过RPC调用下游service再拿一些数据,或者让下游service去处理一些相关的任务
- RPC调用结束后,再进行一些本地计算,怎么计算和业务逻辑相关
- 访问DB进行一些数据操作
- 操作完数据库之后做一些收尾工作,同样这些收尾工作也是本地计算,和业务逻辑相关
分析整个处理的时间轴,会发现: - 其中1,3,5,7步骤中【上图中粉色时间轴】,线程进行本地业务逻辑计算时需要占用CPU
- 而2,4,6步骤中【上图中橙色时间轴】,访问cache、service、DB过程中线程处于一个等待结果的状态,不需要占用CPU,进一步的分解,这个“等待结果”的时间共分为三部分:
2.1 请求在网络上传输到下游的cache、service、DB
2.2 下游cache、service、DB进行任务处理
2.3 cache、service、DB将报文在网络上传回工作线程
猜想:
N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,则工作线程数(线程池线程数)设置为 N*(x+y)/x+1,能让CPU的利用率最大化。
其实就是算出一个线程中,cpu时间(x)占整个线程工作时间(x+y)的比率(x/(x+y)),然后N核服务器为了N核都跑满100%那么就用N除以这个比率,最后加上1















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









