









SQL执行计划是经过优化器决策,产生的SQL在数据库内部执行的访问路径计划;
由如下语法得到:
explain select col1,col2 from t1..;
desc select col1,col2 from t1..;理解输出各个列的含义

- id:每个select子句的标识id
- select_type:select语句的类型
- table:当前表名
- 显示查询将访问的分区,如果你的查询是基于分区表
- type:当前表内访问方式
- possible_keys:可能使用到的索引
- key:经过优化器评估最终使用的索引
- key_length:使用到的索引长度
- ref:引用到的上一个表的列
- rows:rows_examined,要得到最终记录索要扫描经过的记录数
- filtered:表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
- Extra:额外的信息说明
接下来主要针对extra字段进行详细解释,EXPLAIN输出的Extra列包含有关MySQL如何解析查询的其他信息。此字段能够给出让我们深入理解执行计划进一步的细节信息,比如是否使用ICP,MRR等。
首先说明下在extra字段进行测试过程中使用到的表和MySQL版本:
CREATE TABLE `test_extra1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`emp_number` int(11) NOT NULL,
`name` varchar(30) NOT NULL DEFAULT '',
`age` int(11) DEFAULT NULL,
`address` varchar(50) DEFAULT NULL,
`region` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_empnumber` (`emp_number`),
KEY `idx_region` (`region`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `test_extra2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) NOT NULL DEFAULT '',
`emp_number` int(11) NOT NULL,
`salary` decimal(10,2) NOT NULL DEFAULT '0.00',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_empnumber` (`emp_number`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysql> select @@version;
+-----------+
| @@version |
+-----------+
| 5.7.14 |
+-----------+
1 row in set (0.00 sec)extra字段详细解释说明:
const row not found
For a query such as SELECT … FROM tbl_name, the table was empty.(类似于select …. from tbl_name,而表记录为空)Deleting all rows
For DELETE, some storage engines (such as MyISAM) support a handler method that removes all table rows in a simple and fast way. This Extra value is displayed if the engine uses this optimization. (对于DELETE,一些存储引擎(如MyISAM)支持一种处理方法,可以简单而快速地删除所有的表行。 如果引擎使用此优化,则会显示此额外值)
Distinct
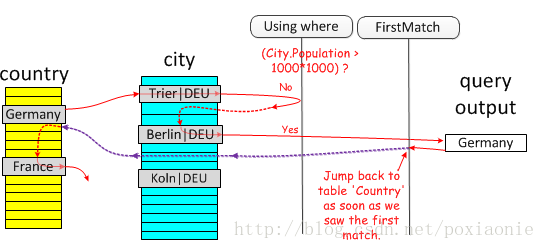
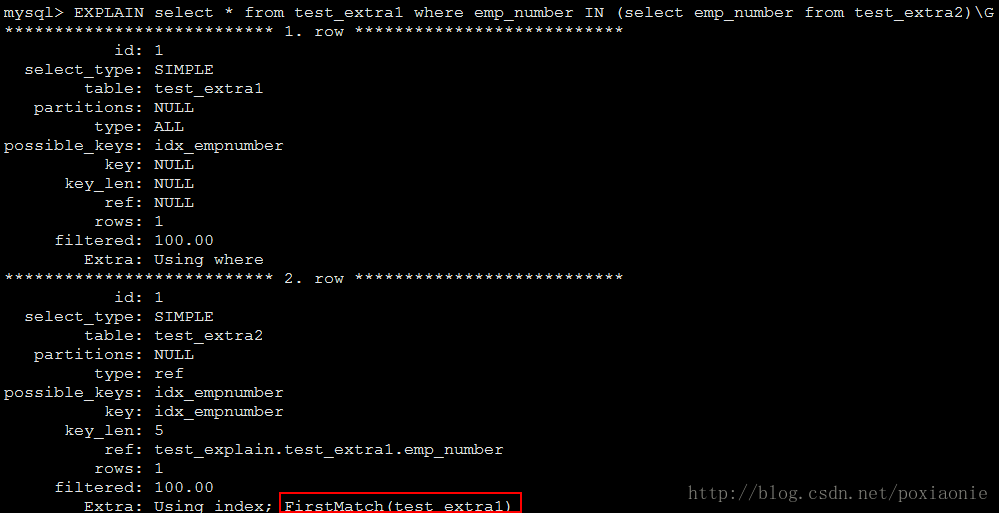
MySQL is looking for distinct values, so it stops searching for more rows for the current row combination after it has found the first matching row.(MySQL正在寻找不同的值,因此在找到第一个匹配行后,它将停止搜索当前行组合的更多行)FirstMatch
The semi-join FirstMatch join shortcutting strategy is used for tbl_name. (半连接去重执行优化策略,当匹配了第一个值之后立即放弃之后记录的搜索。这为表扫描提供了一个早期退出机制而且还消除了不必要记录的产生);如下图所示:
注:半连接: 当一张表在另一张表找到匹配的记录之后,半连接(semi-jion)返回第一张表中的记录。与条件连接相反,即使在右节点中找到几条匹配的记录,左节点的表也只会返回一条记录。另外,右节点的表一条记录也不会返回。半连接通常使用IN或EXISTS 作为连接条件。
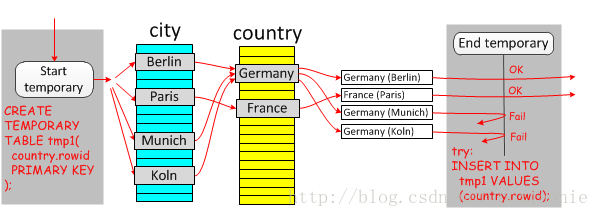
Start temporary, End temporary
表示半连接中使用了DuplicateWeedout策略的临时表,具体实现过程如下图所示:
Full scan on NULL key
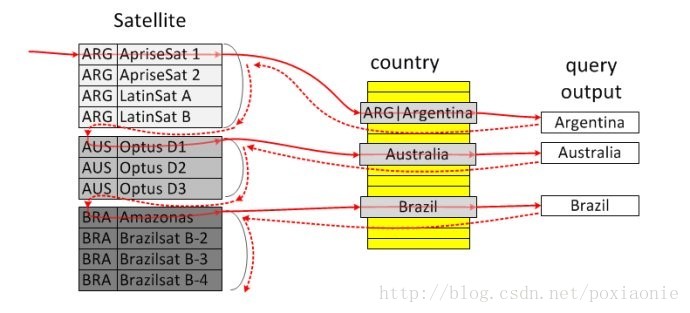
This occurs for subquery optimization as a fallback strategy when the optimizer cannot use an index-lookup access method.(子查询中的一种优化方式,主要在遇到无法通过索引访问null值的使用)LooseScan(m..n)
The semi-join LooseScan strategy is used. m and n are key part numbers. 利用索引来扫描一个子查询表可以从每个子查询的值群组中选出一个单一的值。松散扫描(LooseScan)策略采用了分组,子查询中的字段作为一个索引且外部SELECT语句可以可以与很多的内部SELECT记录相匹配。如此便会有通过索引对记录进行分组的效果。
如下图所示:
Impossible HAVING
The HAVING clause is always false and cannot select any rows.(HAVING子句总是为false,不能选择任何行)
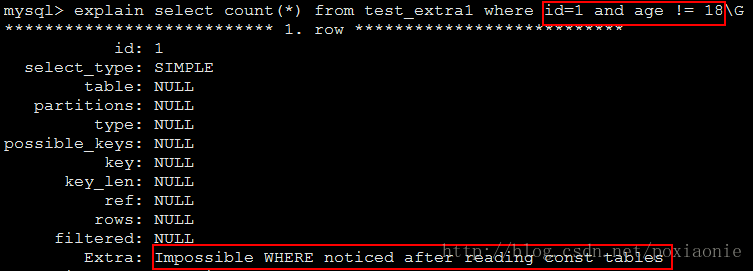
Impossible WHERE
The WHERE clause is always false and cannot select any rows.(WHERE子句始终为false,不能选择任何行)
Impossible WHERE noticed after reading const tables
MySQL has read all const (and system) tables and notice that the WHERE clause is always false.(MySQL读取了所有的const和system表,并注意到WHERE子句总是为false)
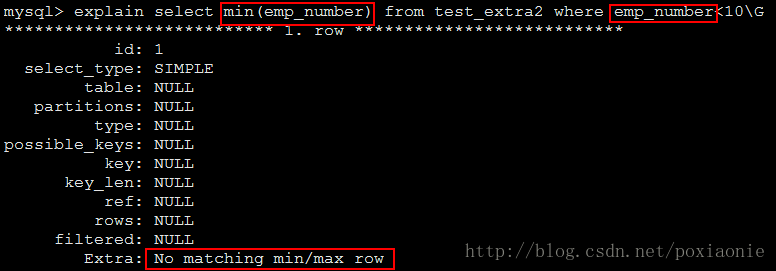
No matching min/max row
No row satisfies the condition for a query such as SELECT MIN(…) FROM … WHERE condition.(没有满足SELECT MIN(…)FROM … WHERE查询条件的行)
示例中,emp_number最小值为1001,没有满足条件的行:
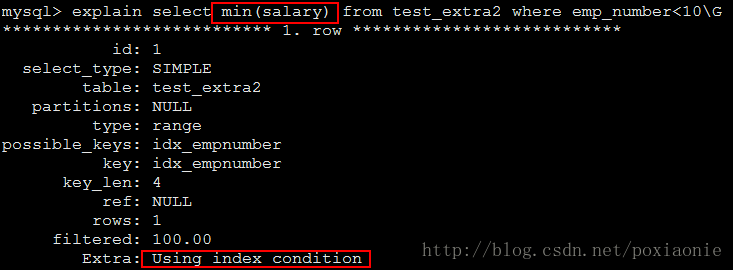
如果此时将select字段改为其他字段,比如salary,则extra如下显示,使用到ICP优化机制(ICP机制见https://dev.mysql.com/doc/refman/5.7/en/index-condition-pushdown-optimization.html)
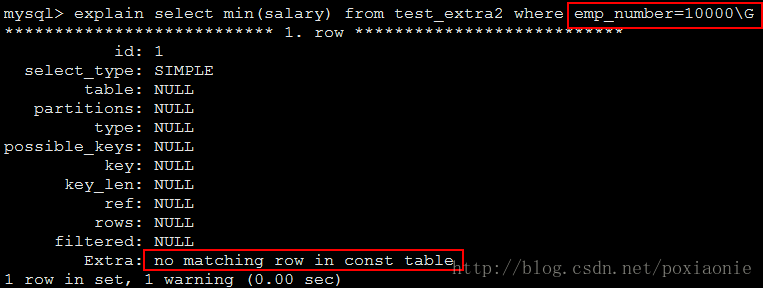
no matching row in const table
For a query with a join, there was an empty table or a table with no rows satisfying a unique index condition.(表为空或者表中根据唯一键查询时没有匹配的行)
No matching rows after partition pruning
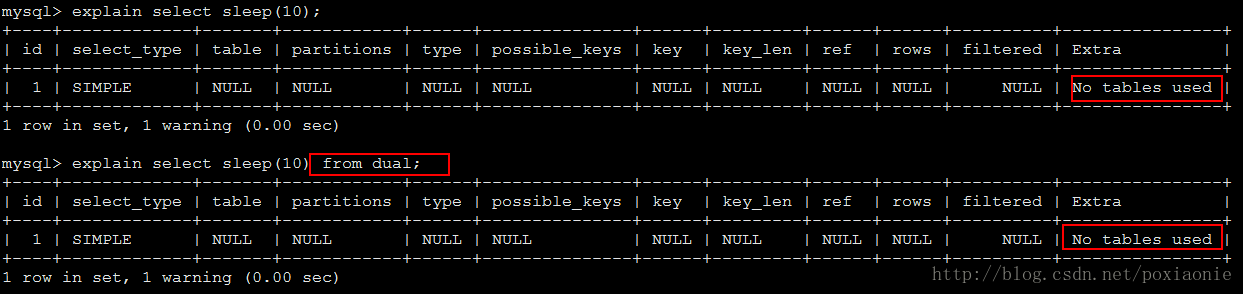
For DELETE or UPDATE, the optimizer found nothing to delete or update after partition pruning. It is similar in meaning to Impossible WHERE for SELECT statements.(对于DELETE或UPDATE,优化器在分区修剪后没有发现任何删除或更新。 对于SELECT语句,它与Impossible WHERE的含义相似)No tables used
The query has no FROM clause, or has a FROM DUAL clause.(没有FROM子句或者使用DUAL虚拟表)
.注:DUAL虚拟表纯粹是为了方便那些要求所有SELECT语句应该有FROM和可能的其他子句的人。 MySQL可能会忽略这些条款。 如果没有引用表,MySQL不需要FROM DUAL(https://dev.mysql.com/doc/refman/5.7/en/select.html)Not exists
MySQL能够对查询执行LEFT JOIN优化,并且在找到与LEFT JOIN条件匹配的一行后,不会在上一行组合中检查此表中的更多行。例如:
SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id
WHERE t2.id IS NULL;
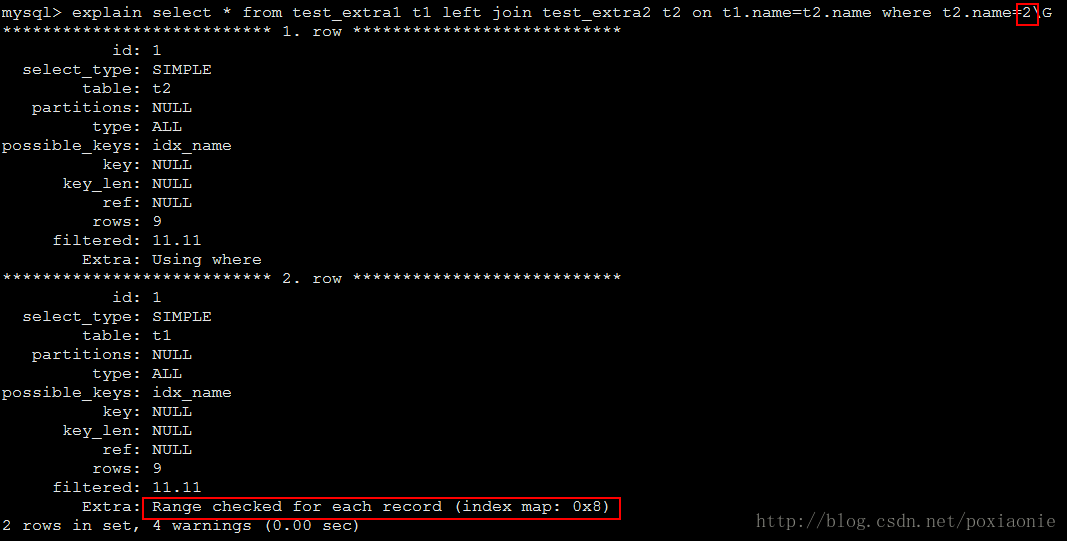
假设t2.id被定义为NOT NULL。 在这种情况下,MySQL会扫描t1,并使用t1.id的值查找t2中的行。 如果MySQL在t2中找到一个匹配的行,它会知道t2.id永远不会为NULL,并且不扫描t2中具有相同id值的其余行。 换句话说,对于t1中的每一行,MySQL只需要在t2中只执行一次查找,而不考虑在t2中实际匹配的行数。Range checked for each record (index map: N)
MySQL发现没有使用好的索引,但是发现在前面的表的列值已知之后,可能会使用一些索引。 对于上表中的每一行组合,MySQL检查是否可以使用range或index_merge访问方法来检索行。 这不是很快,但比执行没有索引的连接更快。
index map N索引的编号从1开始,按照与表的SHOW INDEX所示相同的顺序。 索引映射值N是指示哪些索引是候选的位掩码值。 例如,0x19(二进制11001)的值意味着将考虑索引1,4和5。
其中name属性为varchar类型;但是条件给出整数型,涉及到隐式转换。
图中t2也没有用到索引,是因为查询之前我将t2中name字段排序规则改为utf8_bin导致的链接字段排序规则不匹配。
Select tables optimized away
当我们使用某些聚合函数来访问存在索引的某个字段时,优化器会通过索引直接一次定位到所需要的数据行完成整个查询。在使用某些聚合函数如min, max的query,直接访问存储结构(B树或者B+树)的最左侧叶子节点或者最右侧叶子节点即可,这些可以通过index解决。Select count(*) from table(不包含where等子句),MyISAM保存了记录的总数,可以直接返回结果,而Innodb需要全表扫描。Query中不能有group by操作;Skip_open_table, Open_frm_only, Open_full_table
这些值表示适用于INFORMATION_SCHEMA表查询的文件打开优化;
Skip_open_table:表文件不需要打开。信息已经通过扫描数据库目录在查询中实现可用。
Open_frm_only:只需要打开表的.frm文件。
Open_full_table:未优化的信息查找。必须打开.frm,.MYD和.MYI文件。unique row not found
对于诸如SELECT … FROM tbl_name的查询,没有行满足表上的UNIQUE索引或PRIMARY KEY的条件。Using filesort
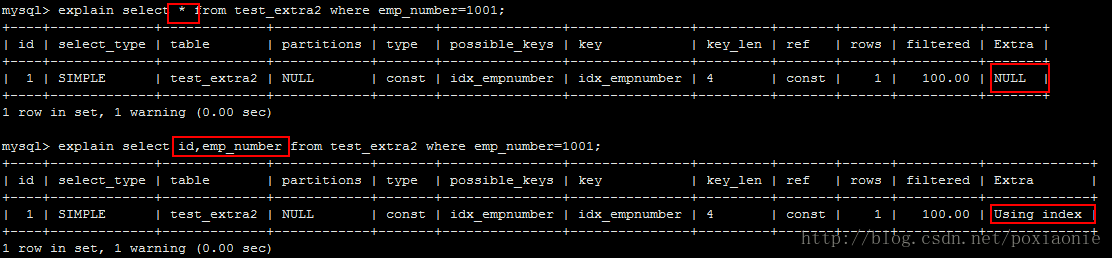
当Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Explain不会显示的告诉客户端用哪种排序。官方解释:“MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行”Using index
仅使用索引树中的信息从表中检索列信息,而不需要进行附加搜索来读取实际行(使用二级覆盖索引即可获取数据)。 当查询仅使用作为单个索引的一部分的列时,可以使用此策略。
示例中第一个查询所有数据时,无法通过emp_number的覆盖索引来获取整行数据,所以需要根据主键id回表查询表数据。
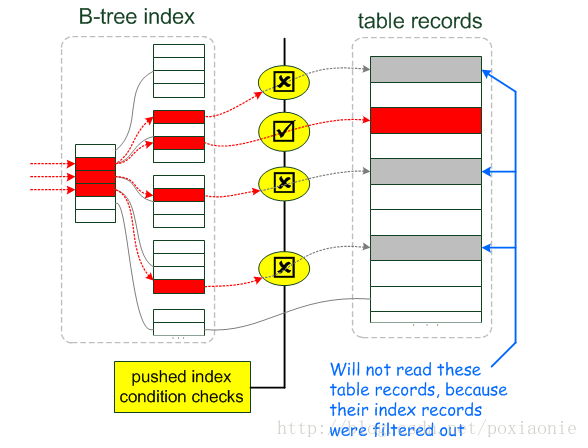
Using index condition
Using index condition 会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
因为MySQL的架构原因,分成了server层和引擎层,才有所谓的“下推”的说法。所以ICP其实就是实现了index filter技术,将原来的在server层进行的table filter中可以进行index filter的部分,在引擎层面使用index filter进行处理,不再需要回表进行table filter(参考http://www.2cto.com/database/201511/451391.html)。
如下图描述:
Using index for group-by
数据访问和 Using index 一样,所需数据只须要读取索引,当Query 中使用GROUP BY或DISTINCT 子句时,如果分组字段也在索引中,Extra中的信息就会是 Using index for group-by。注:和Using index一样,只需读取覆盖索引
Using join buffer (Block Nested Loop), Using join buffer (Batched Key Access)
*注:
Block Nested-Loop Join算法:将外层循环的行/结果集存入join buffer, 内层循环的每一行与整个buffer中的记录做比较,从而减少内层循环的次数。优化器管理参数optimizer_switch中中的block_nested_loop参数控制着BNL是否被用于优化器。默认条件下是开启,若果设置为off,优化器在选择 join方式的时候会选择NLJ(Nested Loop Join)算法。
Batched Key Access原理:对于多表join语句,当MySQL使用索引访问第二个join表的时候,使用一个join buffer来收集第一个操作对象生成的相关列值。BKA构建好key后,批量传给引擎层做索引查找。key是通过MRR接口提交给引擎的(mrr目的是较为顺序)MRR使得查询更有效率,要使用BKA,必须调整系统参数optimizer_switch的值,batched_key_access设置为on,因为BKA使用了MRR,因此也要打开MRR (参考http://www.cnblogs.com/chenpingzhao/p/6720531.html)。*
Using MRR
使用MRR策略优化表数据读取,仅仅针对二级索引的范围扫描和 使用二级索引进行 join 的情况;
过程:先根据where条件中的辅助索引获取辅助索引与主键的集合,再将结果集放在buffer(read_rnd_buffer_size 直到buffer满了),然后对结果集按照pk_column排序,得到有序的结果集rest_sort。最后利用已经排序过的结果集,访问表中的数据,此时是顺序IO。即MySQL 将根据辅助索引获取的结果集根据主键进行排序,将无序化为有序,可以用主键顺序访问基表,将随机读转化为顺序读,多页数据记录可一次性读入或根据此次的主键范围分次读入,减少IO操作,提高查询效率。
注:MRR原理:Multi-Range Read Optimization,是优化器将随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销的一种手段,这对IO-bound类型的SQL语句性能带来极大的提升,适用于range ref eq_ref类型的查询;Using sort_union(…), Using union(…), Using intersect(…)
这些指示索引扫描如何合并为index_merge连接类型。
(参考https://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html)
索引合并交叉口访问算法(The Index Merge Intersection Access Algorithm):
index intersect merge就是多个索引条件扫描得到的结果进行交集运算。显然在多个索引提交之间是 AND 运算时,才会出现 index intersect merge. 下面两种where条件或者它们的组合时会进行 index intersect merge:
1) 条件使用到复合索引中的所有字段或者左前缀字段;
2) 主键上的任何范围条件。
intersect merge运行方式:多个索引同时扫描,然后结果取交集。如果所有条件字段都是索引字段,使用索引覆盖扫描,无需回表
示例:






SELECT * FROM innodb_table WHERE primary_key < 10 AND key_col1=20;
SELECT * FROM tbl_name WHERE (key1_part1=1 AND key1_part2=2) AND key2=2;索引合并联合访问算法(The Index Merge Union Access Algorithm):
index uion merge就是多个索引条件扫描,对得到的结果进行并集运算,显然是多个条件之间进行的是 OR 运算。以下几种可能会使用到index merge union: 1) 条件使用到复合索引中的所有字段或者左前缀字段(对单字段索引也适用);2) 主键上的任何范围条件;3) 任何符合 index intersect merge 的where条件;
示例:
SELECT * FROM t1 WHERE key1=1 OR key2=2 OR key3=3;
SELECT * FROM innodb_table WHERE (key1=1 AND key2=2) OR (key3='foo' AND key4='bar') AND key5=5;索引合并排序联合访问算法(The Index Merge Sort-Union Access Algorithm):
多个条件扫描进行 OR 运算,但是不符合 index union merge算法的,此时可能会使用 sort_union算法;
SELECT * FROM tbl_name WHERE key_col1 < 10 OR key_col2 < 20;
SELECT * FROM tbl_name
WHERE (key_col1 > 10 OR key_col2 = 20) AND nonkey_col=30;Using temporary
要解决查询,MySQL需要创建一个临时表来保存结果。 如果查询包含不同列的GROUP BY和ORDER BY子句,则通常会发生这种情况。官方解释:”为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。很明显就是通过where条件一次性检索出来的结果集太大了,内存放不下了,只能通过家里临时表来辅助处理;
Using where
表示Mysql将对storage engine提取的结果进行过滤,过滤条件字段无索引;
Using where with pushed condition
仅用在ndb上。Mysql Cluster用Condition Pushdown优化改善非索引字段和常量之间的直接比较。condition被pushed down到cluster的数据节点,并在所有数据节点同时估算,把不合条件的列剔除避免网络传输


参考:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html














 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









