







原计划用cygwin来运行linux的脚本,进行测试。但是在实际运行过程中,出现java -cp x.jar class,总是失败的问题,一直没有解决,因而,直接用windows版本的scala及spark,其中scala有单独的window版本的MSI文件,下载后直接安装即可。spark下载编译好的二进制文件,解压缩即可,不需要安装。
开头提到的问题,最终在帖子cygwin下java类库的使用中解决
目前电脑中软件配置: java1.8 ;scala 2.10.5 ;spark 1.5.0 & spark1.5.1
配置spark-1.5.0-bin-hadoop2.6\conf\spark-env.sh 中的内容(此文件在linux下使用。windows下用.cmd版本)
spark-defaults.conf 文件的内容为: 主要修改了中间结果目录,默认目录在c盘的隐藏目录。此外,本来想开启log功能,但启动时,总是报错,主要是windows下log.dir 配置,其目录结构应该如何填写,此问题未解决。
spark.master local
#spark.eventLog.enabled true
spark.driver.memory 300m
#spark.eventLog.dir file:///f://log
spark.local.dir f://temp
1. 启动shell的命令
E:\cygwin\home\Administrator\spark-1.5.0-bin-hadoop2.6\bin>spark-shell --master local
其中参数master的参数如下所述,描述了选用哪种cluster mode。

local模式启动后。
问题:启动的对象是下图左边的部分,还是下图整个部分都运行起来了?
答: 经过查看下面 SparkPi的日志信息,在配置为local mode时,左边的Driver Program和右边的Executor 及Task都被创建了!另外有一些block manger \mem manger,不清楚是否可以看做中间的Cluster Manager

启动后,通过IE工具可以看到当前信息:
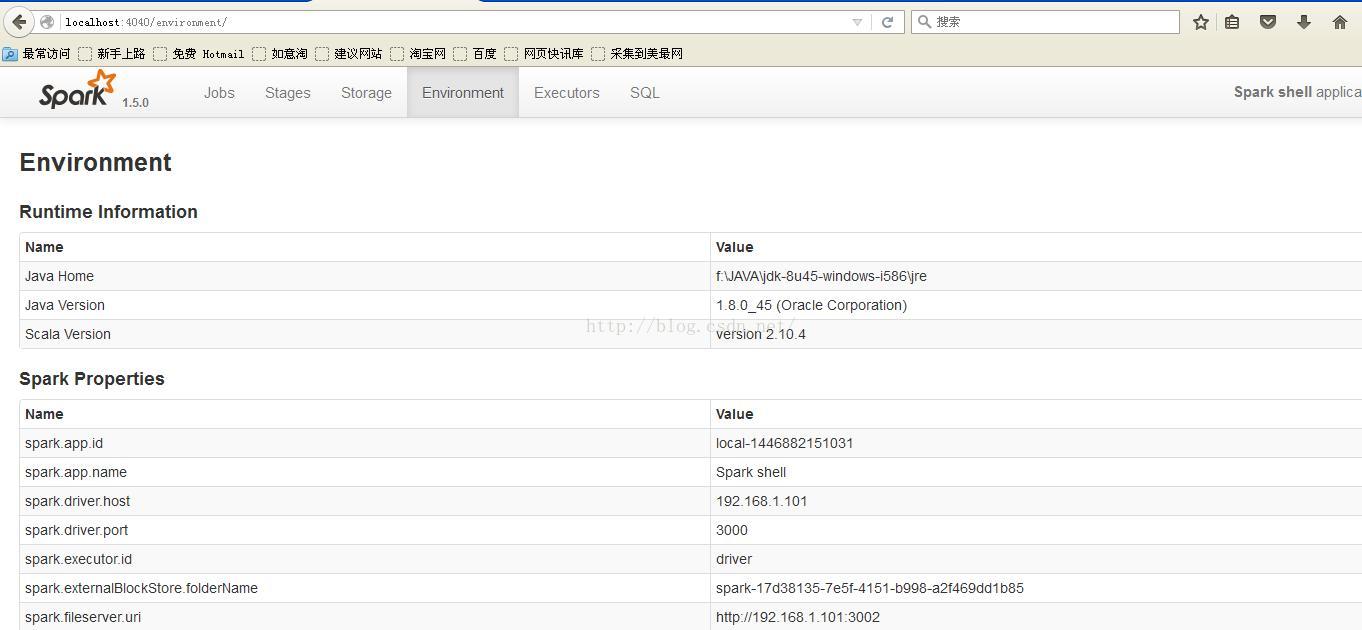
运行spark自带的测试用例:运行记录如下
E:\cygwin\home\Administrator\spark-1.5.0-bin-hadoop2.6\bin>run-example SparkPi 10
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/11/07 13:18:12 INFO SparkContext: Running Spark version 1.5.0 (1) sparkContext 被创建
15/11/07 13:18:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/11/07 13:18:13 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:363)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:104)
at org.apache.hadoop.security.Groups.<init>(Groups.java:86)
at org.apache.hadoop.security.Groups.<init>(Groups.java:66)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:280)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:271)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:248)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:763)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:748)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:621)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2084)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:310)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:29)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:672)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
15/11/07 13:18:13 WARN Utils: Your hostname, localhost resolves to a loopback address: 127.0.0.1; using 192.168.1.101 instead (on interface eth0)
15/11/07 13:18:13 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/11/07 13:18:13 INFO SecurityManager: Changing view acls to: Administrator (2)
15/11/07 13:18:13 INFO SecurityManager: Changing modify acls to: Administrator
15/11/07 13:18:13 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Administrator); u
sers with modify permissions: Set(Administrator)
15/11/07 13:18:14 INFO Slf4jLogger: Slf4jLogger started
15/11/07 13:18:14 INFO Remoting: Starting remoting
15/11/07 13:18:14 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.1.101:3797]
15/11/07 13:18:14 INFO Utils: Successfully started service 'sparkDriver' on port 3797.(3) spark Driver被启动
15/11/07 13:18:14 INFO SparkEnv: Registering MapOutputTracker
15/11/07 13:18:14 INFO SparkEnv: Registering BlockManagerMaster (4)磁盘管理
15/11/07 13:18:14 INFO DiskBlockManager: Created local directory at C:\Documents and Settings\Administrator\Local Settings\Temp\blockmgr-fb2674e4-efce
-4117-9e5b-4d6ee364fd49
15/11/07 13:18:14 INFO MemoryStore: MemoryStore started with capacity 534.5 MB
15/11/07 13:18:14 INFO HttpFileServer: HTTP File server directory isC:\Documents and Settings\Administrator\Local Settings\Temp\spark-8b948801-bcd3-4
092-a3b7-ed45c37da60f\httpd-445b6b1d-c29b-433e-bb0c-7678f38a8025 此处Block和Http 的临时目录,可以通过配置变量 spark.local.dir f://temp来修改(windows下的目录设置)。
15/11/07 13:18:14 INFO HttpServer: Starting HTTP Server
15/11/07 13:18:15 INFO Utils: Successfully started service 'HTTP file server' on port 3798. (5)启动一个HTTP server
15/11/07 13:18:15 INFO SparkEnv: Registering OutputCommitCoordinator
15/11/07 13:18:15 INFO Utils: Successfully started service 'SparkUI' on port 4040. (6)启动SparkUI
15/11/07 13:18:15 INFO SparkUI: Started SparkUI at http://192.168.1.101:4040
15/11/07 13:18:16 INFO SparkContext: Added JAR file:/E:/cygwin/home/Administrator/spark-1.5.0-bin-hadoop2.6/bin/../lib/spark-examples-1.5.0-hadoop2.6.
0.jar at http://192.168.1.101:3798/jars/spark-examples-1.5.0-hadoop2.6.0.jar with timestamp 1446873496968
15/11/07 13:18:17 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set. (7)设置DAG调度策略
15/11/07 13:18:17 INFO Executor: Starting executor ID driver on host localhost (8) 启动一个executor
15/11/07 13:18:17 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService'on port 3809.
15/11/07 13:18:17 INFO NettyBlockTransferService: Server created on 3809
15/11/07 13:18:17 INFO BlockManagerMaster: Trying to register BlockManager
15/11/07 13:18:17 INFO BlockManagerMasterEndpoint: Registering block manager localhost:3809 with 534.5 MBRAM, BlockManagerId(driver, localhost, 3809)
15/11/07 13:18:17 INFO BlockManagerMaster: Registered BlockManager
15/11/07 13:18:17 INFO SparkContext: Starting job: reduce at SparkPi.scala:36 (9) 开始干活
15/11/07 13:18:17 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:36) with 10 output partitions (9.1) RDD被分成10个partitions!
15/11/07 13:18:17 INFO DAGScheduler: Final stage: ResultStage 0(reduce at SparkPi.scala:36)
15/11/07 13:18:17 INFO DAGScheduler: Parents of final stage: List()
15/11/07 13:18:17 INFO DAGScheduler: Missing parents: List()
15/11/07 13:18:17 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32), which has no missing parents(9,2)遇到action(spark.parallelize)开始提交计算
15/11/07 13:18:18 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
15/11/07 13:18:18 INFO MemoryStore: ensureFreeSpace(1888) called with curMem=0, maxMem=560497950
15/11/07 13:18:18 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1888.0 B, free 534.5 MB)
15/11/07 13:18:18 INFO MemoryStore: ensureFreeSpace(1202) called with curMem=1888, maxMem=560497950
15/11/07 13:18:18 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1202.0 B, free 534.5 MB)
15/11/07 13:18:18 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:3809 (size: 1202.0 B, free: 534.5 MB)
15/11/07 13:18:18 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:861
15/11/07 13:18:18 INFO DAGScheduler: Submitting 10 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32)
15/11/07 13:18:18 INFO TaskSchedulerImpl: Adding task set 0.0 with 10 tasks
15/11/07 13:18:18 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 2162 bytes)
15/11/07 13:18:18 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, PROCESS_LOCAL, 2162 bytes)
15/11/07 13:18:18 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
15/11/07 13:18:18 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
15/11/07 13:18:18 INFO Executor: Fetching http://192.168.1.101:3798/jars/spark-examples-1.5.0-hadoop2.6.0.jar with timestamp 1446873496968
15/11/07 13:18:18 INFO Utils: Fetching http://192.168.1.101:3798/jars/spark-examples-1.5.0-hadoop2.6.0.jar to C:\Documents and Settings\Administrator\ (9.3) ??这一步意图为何??
Local Settings\Temp\spark-8b948801-bcd3-4092-a3b7-ed45c37da60f\userFiles-653a0c8f-b72e-4efc-8869-debf959d2d10\fetchFileTemp1531247146457856155.tmp
15/11/07 13:18:22 INFO Executor: Fetching http://192.168.1.101:3798/jars/spark-examples-1.5.0-hadoop2.6.0.jar with timestamp 1446873496968
15/11/07 13:18:22 ERROR Executor: Exception in task 1.0 in stage 0.0 (TID 1)
java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:873)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:853)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:381)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:405)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:397)
at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:772)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:226)
at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:39)
at scala.collection.mutable.HashMap.foreach(HashMap.scala:98)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:771)
at org.apache.spark.executor.Executor.org$apache$spark$executor$Executor$$updateDependencies(Executor.scala:397)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:193)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
15/11/07 13:18:22 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, PROCESS_LOCAL, 2162 bytes)
15/11/07 13:18:22 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
15/11/07 13:18:22 INFO Utils: Fetching http://192.168.1.101:3798/jars/spark-examples-1.5.0-hadoop2.6.0.jar to C:\Documents and Settings\Administrator\
Local Settings\Temp\spark-8b948801-bcd3-4092-a3b7-ed45c37da60f\userFiles-653a0c8f-b72e-4efc-8869-debf959d2d10\fetchFileTemp8741881623838500599.tmp
15/11/07 13:18:22 WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, localhost): java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:873)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:853)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:381)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:405)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:397)
at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:772)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:226)
at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:39)
at scala.collection.mutable.HashMap.foreach(HashMap.scala:98)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:771)
at org.apache.spark.executor.Executor.org$apache$spark$executor$Executor$$updateDependencies(Executor.scala:397)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:193)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
15/11/07 13:18:22 ERROR TaskSetManager: Task 1 in stage 0.0 failed 1 times; aborting job
15/11/07 13:18:22 INFO TaskSchedulerImpl: Cancelling stage 0
15/11/07 13:18:22 INFO TaskSchedulerImpl: Stage 0 was cancelled
15/11/07 13:18:22 INFO Executor: Executor is trying to kill task 0.0 in stage 0.0 (TID 0)
15/11/07 13:18:22 INFO Executor: Executor is trying to kill task 2.0 in stage 0.0 (TID 2)
15/11/07 13:18:22 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) failed in 4.312 s
15/11/07 13:18:22 INFO DAGScheduler: Job 0 failed: reduce at SparkPi.scala:36, took 4.599165 s (10)返回结果,失败了。Executor失败。
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 1 times, most recent failure:
Lost task 1.0 in stage 0.0 (TID 1, localhost): java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:873)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:853)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:381)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:405)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:397)
at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:772)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:226)
at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:39)
at scala.collection.mutable.HashMap.foreach(HashMap.scala:98)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:771)
at org.apache.spark.executor.Executor.org$apache$spark$executor$Executor$$updateDependencies(Executor.scala:397)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:193)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1280)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1268)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1267)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1267)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:697)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:697)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:697)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1493)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1455)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1444)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:567)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1813)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1933)
at org.apache.spark.rdd.RDD$$anonfun$reduce$1.apply(RDD.scala:1003)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:147)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:108)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:306)
at org.apache.spark.rdd.RDD.reduce(RDD.scala:985)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:36)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:672)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:873)
at org.apache.hadoop.fs.FileUtil.chmod(FileUtil.java:853)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:381)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:405)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:397)
at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:772)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:226)
at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:39)
at scala.collection.mutable.HashMap.foreach(HashMap.scala:98)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:771)
at org.apache.spark.executor.Executor.org$apache$spark$executor$Executor$$updateDependencies(Executor.scala:397)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:193)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
15/11/07 13:18:22 INFO SparkContext: Invoking stop() from shutdown hook
15/11/07 13:18:22 INFO SparkUI: Stopped Spark web UI at http://192.168.1.101:4040
15/11/07 13:18:22 INFO DAGScheduler: Stopping DAGScheduler (11)释放资源
15/11/07 13:18:22 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
org.apache.spark.SparkException: File C:\Documents and Settings\Administrator\Local Settings\Temp\spark-8b948801-bcd3-4092-a3b7-ed45c37da60f\userFiles
-653a0c8f-b72e-4efc-8869-debf959d2d10\spark-examples-1.5.0-hadoop2.6.0.jar exists and does not match contents of http://192.168.1.101:3798/jars/spark-
examples-1.5.0-hadoop2.6.0.jar
at org.apache.spark.util.Utils$.copyFile(Utils.scala:464)
at org.apache.spark.util.Utils$.downloadFile(Utils.scala:416)
at org.apache.spark.util.Utils$.doFetchFile(Utils.scala:557)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:369)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:405)
at org.apache.spark.executor.Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$5.apply(Executor.scala:397)
at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:772)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:98)
at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:226)
at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:39)
at scala.collection.mutable.HashMap.foreach(HashMap.scala:98)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:771)
at org.apache.spark.executor.Executor.org$apache$spark$executor$Executor$$updateDependencies(Executor.scala:397)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:193)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
15/11/07 13:18:22 INFO Executor: Fetching http://192.168.1.101:3798/jars/spark-examples-1.5.0-hadoop2.6.0.jar with timestamp 1446873496968
15/11/07 13:18:22 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
15/11/07 13:18:22 INFO MemoryStore: MemoryStore cleared
15/11/07 13:18:22 INFO BlockManager: BlockManager stopped
15/11/07 13:18:22 INFO BlockManagerMaster: BlockManagerMaster stopped
15/11/07 13:18:22 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
15/11/07 13:18:22 INFO SparkContext: Successfully stopped SparkContext
15/11/07 13:18:22 INFO ShutdownHookManager: Shutdown hook called
15/11/07 13:18:22 INFO ShutdownHookManager: Deleting directory C:\Documents and Settings\Administrator\Local Settings\Temp\spark-8b948801-bcd3-4092-a3
b7-ed45c37da60f
15/11/07 13:18:22 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
15/11/07 13:18:22 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
=======================================================================================
Python 版本的运行
E:\cygwin\home\Administrator\spark-1.5.1-bin-hadoop2.6\bin>spark-submit ..\examples\src\main\python\pi.py
15/11/08 20:57:19 INFO SparkContext: Running Spark version 1.5.1
15/11/08 20:57:20 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/11/08 20:57:20 WARN SparkConf: In Spark 1.0 and later spark.local.dir will be overridden by the value set by the cluster manager (via SPARK_LOCAL
RS in mesos/standalone and LOCAL_DIRS in YARN).
15/11/08 20:57:20 WARN Utils: Your hostname, localhost resolves to a loopback address: 127.0.0.1; using 192.168.1.101 instead (on interface eth0)
15/11/08 20:57:20 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/11/08 20:57:20 INFO SecurityManager: Changing view acls to: Administrator
15/11/08 20:57:20 INFO SecurityManager: Changing modify acls to: Administrator
15/11/08 20:57:20 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Administrator);
ers with modify permissions: Set(Administrator)
15/11/08 20:57:21 INFO Slf4jLogger: Slf4jLogger started
15/11/08 20:57:21 INFO Remoting: Starting remoting
15/11/08 20:57:21 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.1.101:3578]
15/11/08 20:57:21 INFO Utils: Successfully started service 'sparkDriver' on port 3578.
15/11/08 20:57:21 INFO SparkEnv: Registering MapOutputTracker
15/11/08 20:57:21 INFO SparkEnv: Registering BlockManagerMaster
15/11/08 20:57:21 INFO DiskBlockManager: Created local directory at F:\temp\blockmgr-97cf16d0-660f-4556-85f6-4025d1edf9b8
15/11/08 20:57:21 INFO MemoryStore: MemoryStore started with capacity 156.6 MB
15/11/08 20:57:21 INFO HttpFileServer: HTTP File server directory is F:\temp\spark-d8fa632f-f80b-4085-8e5c-bcffb6f4d8c6\httpd-624e3904-4ca6-4a37-b96
f24bf5721b4
15/11/08 20:57:21 INFO HttpServer: Starting HTTP Server
15/11/08 20:57:21 INFO Utils: Successfully started service 'HTTP file server' on port 3579.
15/11/08 20:57:21 INFO SparkEnv: Registering OutputCommitCoordinator
15/11/08 20:57:21 INFO Utils: Successfully started service 'SparkUI' on port 4040.
15/11/08 20:57:21 INFO SparkUI: Started SparkUI at http://192.168.1.101:4040
15/11/08 20:57:22 WARN : Your hostname, localhost resolves to a loopback/non-reachable address: 192.168.1.101, but we couldn't find any external IP
ress!
15/11/08 20:57:22 INFO Utils: Copying E:\cygwin\home\Administrator\spark-1.5.1-bin-hadoop2.6\bin\..\examples\src\main\python\pi.py to F:\temp\spark-
a632f-f80b-4085-8e5c-bcffb6f4d8c6\userFiles-841e8084-b720-41fc-9329-1612c997588f\pi.py (1) 将application拷贝到临时目录
15/11/08 20:57:22 INFO SparkContext: Added file file:/E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src/main/python/pi.py a
ile:/E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src/main/python/pi.py with timestamp 1446987442296
15/11/08 20:57:22 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
15/11/08 20:57:22 INFO Executor: Starting executor ID driver on host localhost (2) executor 被启动
15/11/08 20:57:22 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 3591.
15/11/08 20:57:22 INFO NettyBlockTransferService: Server created on 3591
15/11/08 20:57:22 INFO BlockManagerMaster: Trying to register BlockManager
15/11/08 20:57:22 INFO BlockManagerMasterEndpoint: Registering block manager localhost:3591 with 156.6 MB RAM, BlockManagerId(driver, localhost, 359
15/11/08 20:57:22 INFO BlockManagerMaster: Registered BlockManager
15/11/08 20:57:23 INFO SparkContext: Starting job: reduce at E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src/main/python/
py:39 ( count = sc.parallelize(range(1, n + 1), partitions).map(f).reduce(add)) (3) Job被启动
15/11/08 20:57:23 INFO DAGScheduler: Got job 0 (reduce at E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src/main/python/pi.
39) with 2 output partitions
15/11/08 20:57:23 INFO DAGScheduler: Final stage: ResultStage 0(reduce at E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src
in/python/pi.py:39)
15/11/08 20:57:23 INFO DAGScheduler: Parents of final stage: List()
15/11/08 20:57:23 INFO DAGScheduler: Missing parents: List()
15/11/08 20:57:23 INFO DAGScheduler: Submitting ResultStage 0 (PythonRDD[1] at reduce at E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/
examples/src/main/python/pi.py:39), which has no missing parents (4) Stage 被提交 stage 包含多个task,stage为Job的子集
15/11/08 20:57:23 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
15/11/08 20:57:23 INFO MemoryStore: ensureFreeSpace(4312) called with curMem=0, maxMem=164207001
15/11/08 20:57:23 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 4.2 KB, free 156.6 MB)
15/11/08 20:57:23 INFO MemoryStore: ensureFreeSpace(2823) called with curMem=4312, maxMem=164207001
15/11/08 20:57:23 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 2.8 KB, free 156.6 MB)
15/11/08 20:57:23 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:3591 (size: 2.8 KB, free: 156.6 MB)
15/11/08 20:57:23 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:861
15/11/08 20:57:23 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0(PythonRDD[1] at reduce at E:/cygwin/home/Administrator/spark-1.5
bin-hadoop2.6/bin/../examples/src/main/python/pi.py:39) (5) 提交task,此task包含在stage中
15/11/08 20:57:23 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
15/11/08 20:57:23 WARN TaskSetManager: Stage 0 contains a task of very large size (365 KB). The maximum recommended task size is 100 KB.
15/11/08 20:57:23 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 374574 bytes)
15/11/08 20:57:23 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
15/11/08 20:57:23 INFO Executor: Fetching file:/E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src/main/python/pi.py with ti
tamp 1446987442296
15/11/08 20:57:23 INFO Utils: E:\cygwin\home\Administrator\spark-1.5.1-bin-hadoop2.6\bin\..\examples\src\main\python\pi.py has been previously copie
o F:\temp\spark-d8fa632f-f80b-4085-8e5c-bcffb6f4d8c6\userFiles-841e8084-b720-41fc-9329-1612c997588f\pi.py
15/11/08 20:57:25 INFO PythonRunner: Times: total = 1453, boot = 1250, init = 32, finish = 171
15/11/08 20:57:25 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 998 bytes result sent to driver (6) task0.0 数据结果被返回给driver
15/11/08 20:57:25 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, PROCESS_LOCAL, 502377 bytes)
15/11/08 20:57:25 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
15/11/08 20:57:25 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1734 ms on localhost (1/2)
15/11/08 20:57:26 INFO PythonRunner: Times: total = 1297, boot = 1125, init = 0, finish = 172
15/11/08 20:57:26 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 998 bytes result sent to driver(7) task1.0 数据结果被返回给driver
15/11/08 20:57:26 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 1344 ms on localhost (2/2)
15/11/08 20:57:26 INFO DAGScheduler: ResultStage 0 (reduce at E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src/main/python
.py:39) finished in 3.078 s
15/11/08 20:57:26 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/11/08 20:57:26 INFO DAGScheduler: Job 0 finished: reduce at E:/cygwin/home/Administrator/spark-1.5.1-bin-hadoop2.6/bin/../examples/src/main/pytho
i.py:39, took 3.367637 s
Pi is roughly 3.139880
15/11/08 20:57:27 INFO SparkUI: Stopped Spark web UI at http://192.168.1.101:4040
15/11/08 20:57:27 INFO DAGScheduler: Stopping DAGScheduler
15/11/08 20:57:27 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
15/11/08 20:57:27 INFO MemoryStore: MemoryStore cleared
15/11/08 20:57:27 INFO BlockManager: BlockManager stopped
15/11/08 20:57:27 INFO BlockManagerMaster: BlockManagerMaster stopped
15/11/08 20:57:27 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
15/11/08 20:57:27 INFO SparkContext: Successfully stopped SparkContext
15/11/08 20:57:27 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
15/11/08 20:57:27 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
15/11/08 20:57:27 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
15/11/08 20:57:27 INFO ShutdownHookManager: Shutdown hook called
15/11/08 20:57:27 INFO ShutdownHookManager: Deleting directory F:\temp\spark-d8fa632f-f80b-4085-8e5c-bcffb6f4d8c6\pyspark-a1f435b6-99e1-4a18-a613-d9
f88bfad
15/11/08 20:57:27 INFO ShutdownHookManager: Deleting directory F:\temp\spark-d8fa632f-f80b-4085-8e5c-bcffb6f4d8c6
E:\cygwin\home\Administrator\spark-1.5.1-bin-hadoop2.6\bin>
知识点:
1. Spark用于写中间数据的存储路径
正式集群应用中,此项配置在SSD等快速盘上,提高 性能
spark.local.dir | /tmp | Directory to use for "scratch" space in Spark, including map output files and RDDs that get stored on disk.This should be on a fast, local disk in your system.It can also be a comma-separated list of multiple directories on different disks. NOTE: In Spark 1.0 and later this will be overriden by SPARK_LOCAL_DIRS (Standalone, Mesos) or LOCAL_DIRS (YARN) environment variables set by the cluster manager. |
在本PC上运行,在spark-defaults.conf配置文件中,将此项修改为:spark.local.dir f://temp
2. spark 涉及的基本概念(官网资料)。driver executor task job stage这几个概念,在上述运行pi例程时均有所涉及
| Term | Meaning |
|---|---|
| Application | User program built on Spark. Consists of a driver program and executors on the cluster. |
| Application jar | A jar containing the user's Spark application. In some cases users will want to create an "uber jar" containing their application along with its dependencies. The user's jar should never include Hadoop or Spark libraries, however, these will be added at runtime. |
| Driver program | The process running the main() function of the application and creating the SparkContext |
| Cluster manager | An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
| Deploy mode | Distinguishes where the driver process runs. In "cluster" mode, the framework launches the driver inside of the cluster. In "client" mode, the submitter launches the driver outside of the cluster. |
| Worker node | Any node that can run application code in the cluster |
| Executor | A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. |
| Task | A unit of work that will be sent to one executor |
| Job | A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g.save,collect); you'll see this term used in the driver's logs. |
| Stage | Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you'll see this term used in the driver's logs. |
参考资料
2. spark入门介绍















 1437
1437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











