









HashMap
jdk8以后他的逻辑结构发生了一点变化:
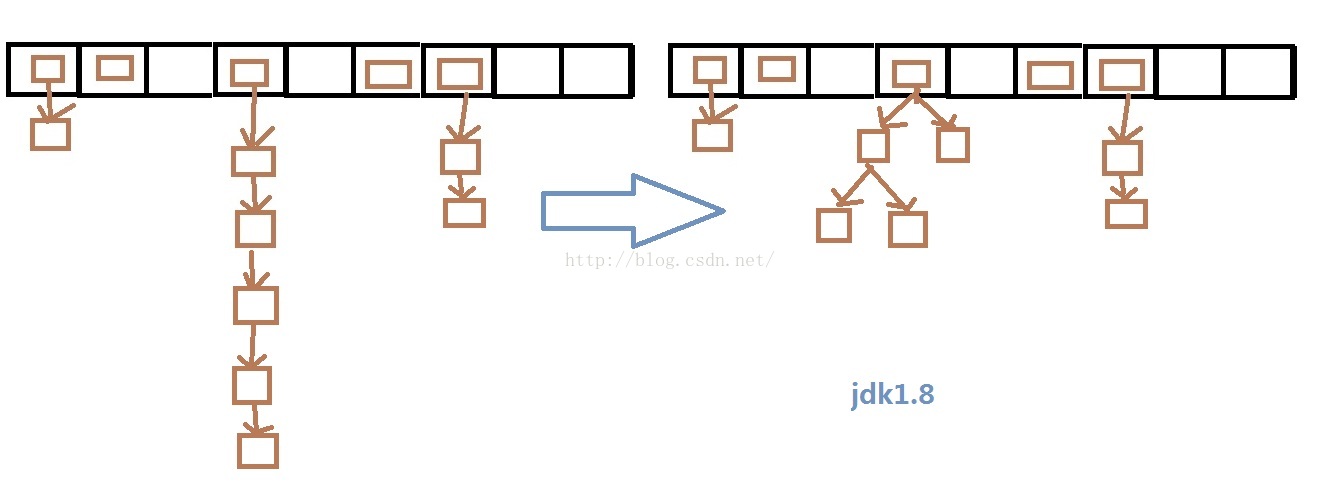
大概就是这个意思:
当某一个点上的元素数量打到一定的阈值的时候,链表会变成一颗树,这样在极端情况下(所有的元素都在一个点上,整个就以链表),一些操作的时间复杂度有O(n)变成了O(logn)。
分析源代码;
一.还是先看下put方法,证明一下上面的图基本是对的:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果当前map中无数据,执行resize方法。并且返回n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上就完事了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//否则的话,说明这上面有元素
else {
Node<K,V> e; K k;
//如果这个元素的key与要插入的一样,那么就替换一下,也完事。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//1.如果当前节点是TreeNode类型的数据,执行putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//还是遍历这条链子上的数据,跟jdk6没什么区别
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //true || --
e.value = value;
//3.
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断阈值,决定是否扩容
if (++size > threshold)
resize();
//4.
afterNodeInsertion(evict);
return null;
}
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }3.4点:
这2个方法是空的,注释上写着这是为LinkedHashMap(HashMap的子类)留的回调函数。方便LinkedHashMao的可开发,所以不管他。
2. if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
这个方法就是判断一下当前走到的这个地方(链表位置),长度是否达到阈值,需要把链表换成树的形式
也就是执行treeifyBIn方法,当然这里要是换成树的形式的话,里面的元素肯定也要换成TreeNode类型的
1. if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
所以说这里就很好理解了,看下你是不是树结构的,如果是数结构就以树的形式去处理,而不是以之前的单链表的形式,傻傻的去一个个遍历
可以看到。put方法与jdk6相比,多出了有关treeNode的处理,同时也少了key为null的判断,记得1.6中的key==null是首先判断并且给他找位置的。
这个多亏了hash方法,他的传入参数从原先的int值的hashCode变成了对象,支持null的传入,所以null传进去得到0的hashCode也能当做普通值一般化处理了
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
二.TreeNode
简单的说,不管方法,里面就包含4个属性。
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;三.treeifyBin
这个方法就是将容器中的node变成treeNode。
方法的参数是Node[] ,int hash,指定需要tree化的是哪个数组,对应的哪个下角标所连出来的链表。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index;
Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
//Node e=tab[该hash对应的角标],e就是这个角标下的第一个元素。
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
//replacementTreeNode == new TreeNode(),就是包装了一个TreeNode对象
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
//遍历链表上的第一个元素的时候,t1==null,将p赋值给hd
//也就是先记录一下,方便后面的元素记录pre,next
hd = p;
else {
//现在p是个tree了,pre记录上一个元素
p.prev = tl;
//顺便把自己的引用在上一个元素上做记录
tl.next = p;
}
//将当前操作的元素的引用传递给t1
tl = p;
//遍历整个链表,直到没有元素。
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
//遍历完了,再执行hd.treeify方法
//hd=p是在t1==null时执行,也就是只有在第一个元素的时候执行了一次
//所以hd代表的是这个树的根。
hd.treeify(tab);
}
}














 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









