







小白一个,接触Python一个多月了,自己感觉最有趣的莫过于利用Python进行网络爬虫,原来都是看着别人的博客把代码抄一遍,今天时间稍微多一些,自己写了一个小爬虫,从分析网页源代码开始,一步步对代码进行设计与完善,捣腾了一中午,终于算是成功了,心情还是蛮激动。下面把代码跟大家分享一下。
豆瓣图书Top250网址:https://book.douban.com/top250
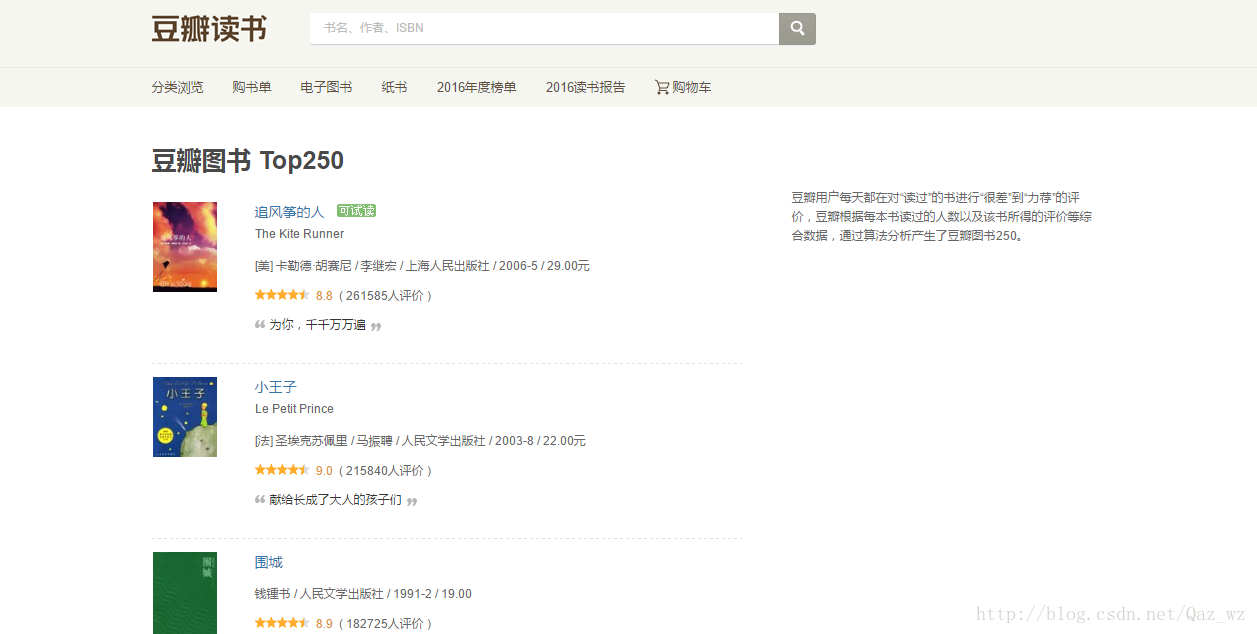
1、首先打开Google浏览器开发者模式(F12或者右键点击检查)
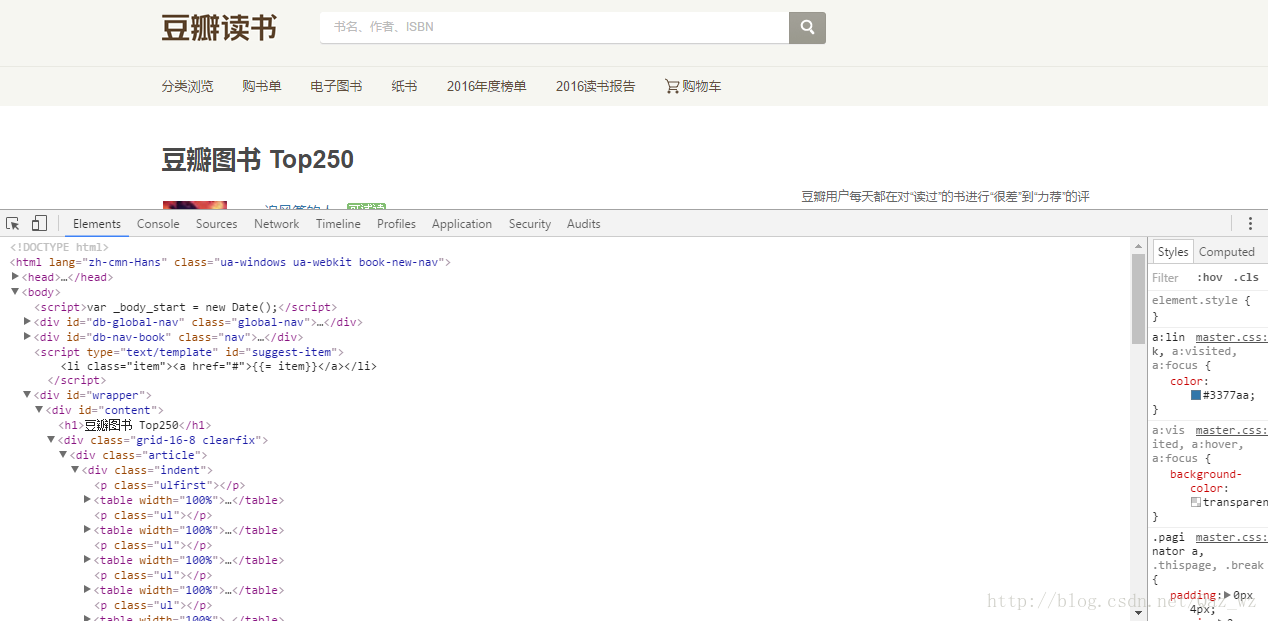
2、浏览网页,发现250本图书一共分成了10页,利用开发者工具找到每一页的url
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









