







最近入坑上道了,跟着周志华老师的《机器学习》,先搞个课后题练练手。
我电脑是Win10的,硬件配置不输Mac Pro,但是之前跑Kaggle上的泰坦尼克,装python的各种package装的我心累,于是这次我直接用VMware开了个Ubuntu在电脑里,给分配了4G的内存,平时就用Ubuntu了,通常遇到什么包没装上,用terminal就可以搞定了。然后我在Ubuntu里装了个pycharm,开发环境就是这样。
第一步:导入数据集,并进行可视化展示
数据集就是西瓜书89页的那个,我挂在我的git上了:https://github.com/qdbszsj/Machine-Learning-test-3.3.git
import numpy as np # for matrix calculation
import matplotlib.pyplot as plt
# load the CSV file as a numpy matrix
#separate the data with " "(blank,\t)
dataset = np.loadtxt('/home/parker/watermelonData/watermelon3_0a.csv', delimiter="\t")
# separate the data from the target attributes
X = dataset[:, 1:3]
y = dataset[:, 3]
goodData=dataset[:8]
badData=dataset[8:]
#return the size
m, n = np.shape(X)
print(m,n)#17,2
# draw scatter diagram to show the raw data
#https://matplotlib.org/api/pyplot_summary.html
f1 = plt.figure(1)
plt.title('watermelon_3a')
plt.xlabel('density')
plt.ylabel('ratio_sugar')
"""
plt.scatter(X[y == 0, 0], X[y == 0, 1], marker='o', color='b', s=100, label='bad')
"""
plt.scatter(goodData[:,1], goodData[:,2], marker='o', color='g', s=100, label='good')
plt.scatter(X[y == 0, 0], X[y == 0, 1], marker='o', color='k', s=100, label='bad')
plt.legend(loc='upper right')然后X就是函数输入的那两列,y就是结果,然后这里绘制一下散点图
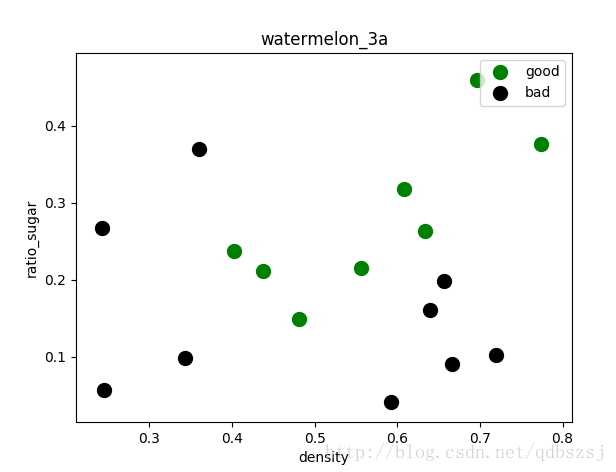
然后这里先用偷懒的方法,用sklear
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2320
2320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









