







最近在开发新的MapReduce程序时,经常要打jar包上传到服务器,然后运行hadoop jar balaba。。。。。。
看到网上都是在Eclipse下调试hadoop集群中MapReduce程序,而且描述的都是模模糊糊,有些根本就是错的,实在不忍心直视,其中有一篇关于idea下调试hadoop集群程序的博客,被疯狂转载,可是仔细看看,根本没用,因为他的平台是Linux。
使用Intellij IDEA+maven的开发hadoop的同学,如果想在本地直接运行,不去上传jar包,可以静下心来看看。
转载请注明出处:http://blog.csdn.net/qingmu0803/article/details/42124571
(1)确保你运行idea的用户和线上hadoop集群的用户一直,不然会报错。也可以在线上hdfs-site.xml中直接修改hdfs的权限,不建议这么做,不安全。
在你的idea安装目录下,新建一个批处理命令.bat文件,内容如下:
runas /user:你线上hadoop集群的用户名 /savecred idea.exe
解释以下 /savecred 这句是运行一次可以保存密码的命令
(2)使用maven打jar包,maven配置如下
<span style="font-family:Microsoft YaHei;font-size:14px;"><profile>
<id>test</id>
<properties>
<env>test</env>
<packing-type>jar</packing-type>
</properties>
<build>
<resources>
<resource>
<directory>src/main/config/${env}</directory>
</resource>
</resources>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2.2</version>
<executions> <!--执行器 mvn assembly:assembly-->
<execution>
<id>make-zip</id><!--名字任意 -->
<phase>package</phase><!-- 绑定到package生命周期阶段上 -->
<goals>
<goal>single</goal><!-- 只运行一次 -->
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
<mainClass>test.Test</mainClass><!-- 你的主类 -->
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<outputDirectory>./</outputDirectory><!-- 你的输出路径 -->
</configuration>
</plugin>
</plugins>
</build>
</profile></span><span style="font-family:Microsoft YaHei;font-size:14px;"> </span><span style="font-family:Microsoft YaHei;font-size:14px;"> conf.set("mapred.jar", "Test-1.0-SNAPSHOT-jar-with-dependencies.jar");
conf.set("fs.default.name", "hdfs://192.168.111.1:9000");//namenode的地址
conf.set("mapred.job.tracker", "192.168.111.1:9001");//namenode的地址</span>(4)配置运行的类
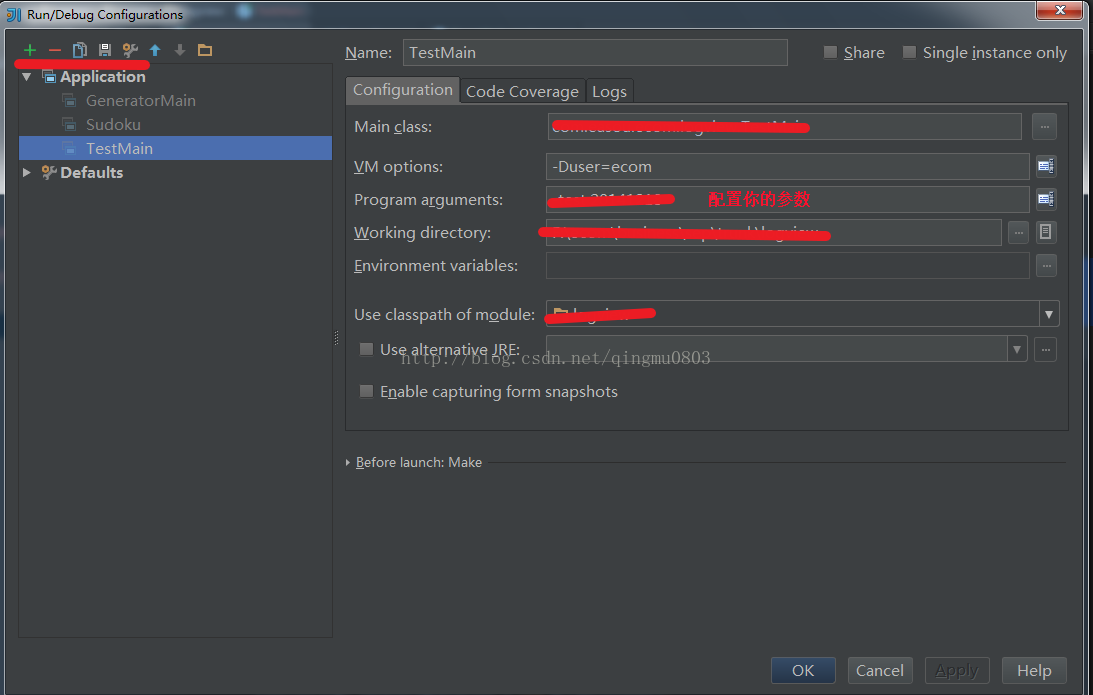
配置你的输入参数即可。
需要注意的事项有:
(1)你的windows下必须有一个和线上hadoop集群一样的用户名
(2)确保你的hadoop程序中的所有jar都是compile
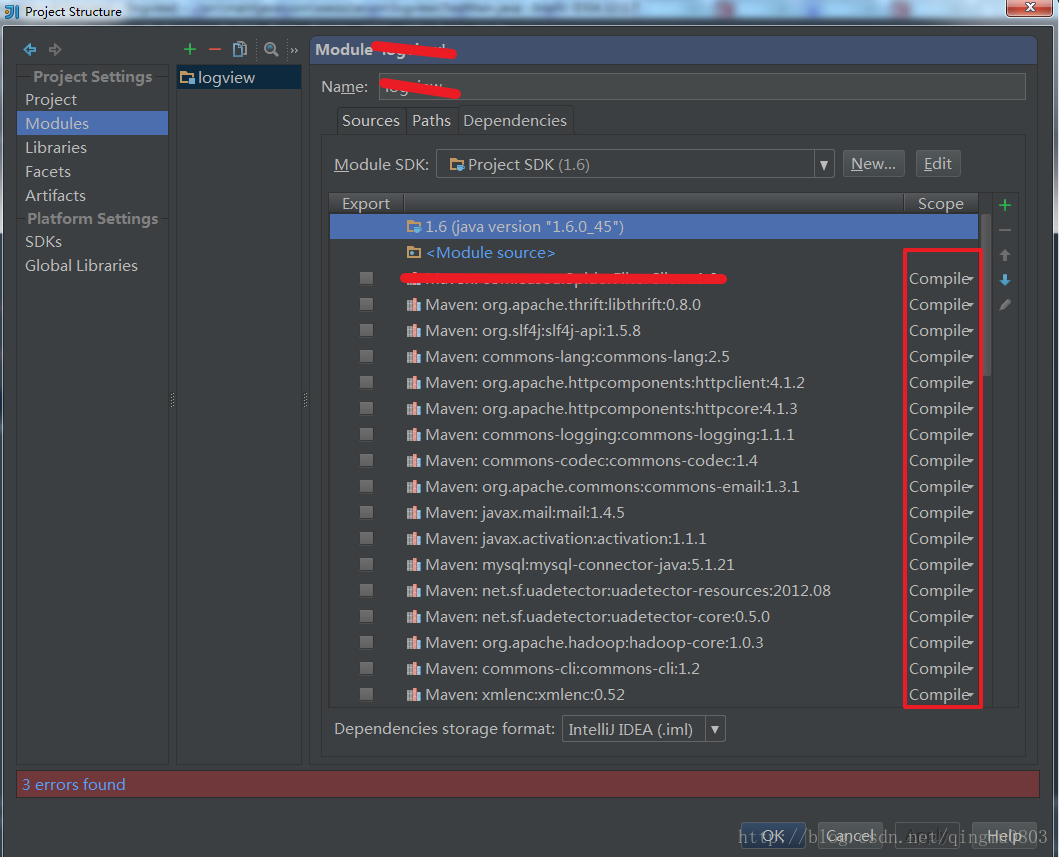
先使用maven将程序打包,然后运行你的程序即可
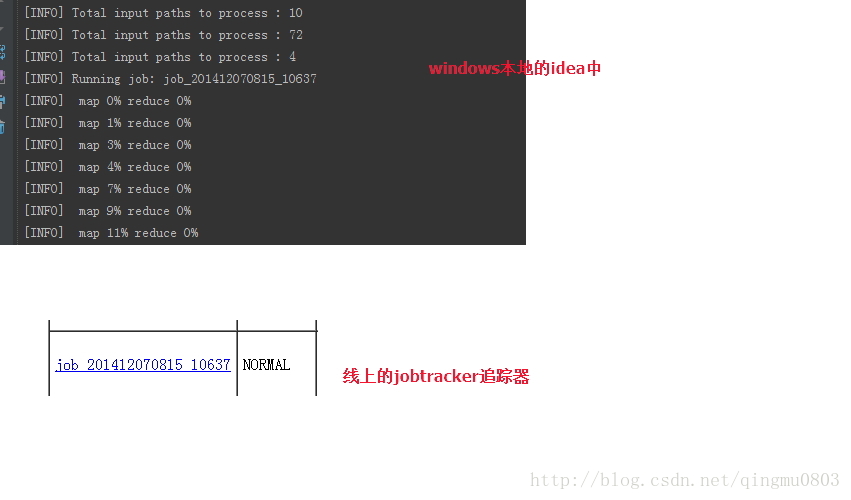
希望对大家的开发有所帮助














 1847
1847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









