







想尝试去写一个程序来实现登录后可以直接查询到我在学校的成绩,但是没做过这方面的东西,而且计算机网络这门课学一年多了,实在记得东西不多,当锻炼了吧。我想我一步知道应该抓取一个页面的数据,然后再通过fiddler抓包,来获取一些需要发送的东西,这里我尝试第一步:如何抓取一个页面的数据.
通过查询网上资料,见很多很多人使用URL抓取网页内容 ,使用正则表达式去除《div》等元素,第一次就先获取页面的全部数据。这里我准备获取w3.school的页面内容
Java代码:
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.*;
public class CatchData {
public static void main(String[] args) {
try {
catchDa("http://www.w3school.com.cn/");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
* 读取网页的全部内容
*/
public static void catchDa(String url) throws IOException{
InputStream in=null;
OutputStream out=null;
URL addURL=null;
try {
addURL=new URL(url);
in=addURL.openStream();
out=new FileOutputStream("a.txt",true);
byte[]c=new byte[1024];
int n=-1;
while((n=in.read(c, 0, 1024))!=-1){
out.write(c, 0, n);
}
} catch (Exception e) {
// TODO: handle exception
}finally{
if(in!=null){
in.close();
}
if(out!=null){
out.close();
}
}
}
}
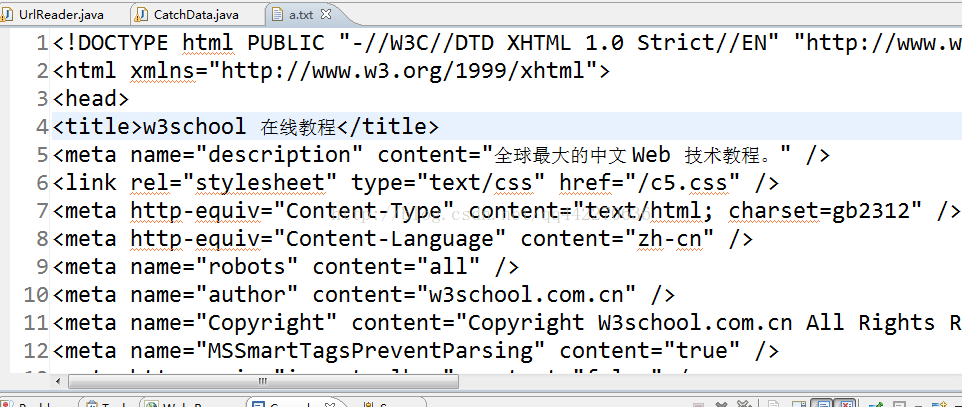
这里我们使用正则表达式去掉标签,并且只获取网页的一部分数据:
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.Writer;
import java.net.URL;
public class UrlReader {
public static String read(String url) throws IOException {
StringBuffer html = new StringBuffer();
InputStream openStream = null;
URL addrUrl = null;
//URLConnection urlConn = null;
BufferedReader br = null;
try {
addrUrl = new URL(url);
openStream = addrUrl.openStream();
br = new BufferedReader(
new InputStreamReader(openStream,"gbk"));
String buf = null;
while ((buf = br.readLine()) != null) {
html.append(buf + "\r\n");
}
} finally {
if (br != null) {
br.close();
}
}
return html.toString();
}
public static void main(String[] args) {
try {
String html=read("http://www.w3school.com.cn/");
int beginindex=html.indexOf("<div id=\"w3\">");
int endindex=html.indexOf("<p>");
String text=html.substring(beginindex, endindex);
text=text.replaceAll("<div id=\"w3\">", "");
text=text.replaceAll("<h2>", "");
text=text.replaceAll("</h2>", "");
OutputStream out=new FileOutputStream("a.txt",true);
out.write(text.getBytes());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}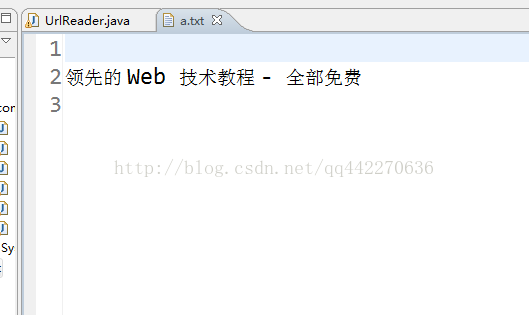
到此我们就实现了如何将网页的内容和需要的数据截取下来,初次尝试,有很多借鉴,希望以后能更熟悉。















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









