







网上关于hdfs的一些初步总结不大好找,搞得初步了解hdfs花了比较多时间。现在准备写点初步学习总结以便能加深记忆,顺便为网上多添点资料。
以下就从5大方面进行初步总结:
1. 整体框架:
总体来说,hdfs的大体框架是比较简单的,作为分布式文件系统,相比普通的文件系统有很多类似之处。主要分成两大类型节点,一个是NameNode,另一个是DataNode,前者承担着文件系统的元信息的管理职责(比如datanode的信息,各个block的位置信息,文件名和其访问权限信息等),某种程度而言类似一个存储元信息的内存数据库,所有客户端要跟读写hdfs,首先访问NameNode,读取或写入相关的元信息,然后根据元信息(包括路由信息)去和DateNode节点交互。后者承担着真正的文件数据存储能力,更多就是类似磁盘的功能,一般有多份副本,分别存储在不同的DataNode节点上。从总体来看是典型的master-slave模式(NameNode是master, DataNode是slave),所以也存在该模式master单点故障的问题,为了解决这个问题,hdfs引入了备份master,也就是secondary NameNode,以便在active NameNode出现故障时,能承担起NameNode的职责。整个体系结构大致如下图:
读步骤:
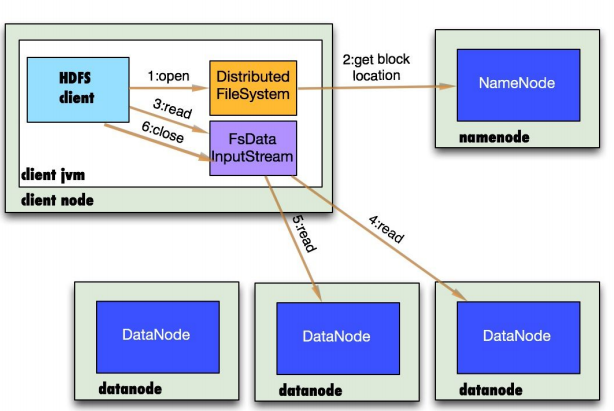
写步骤:
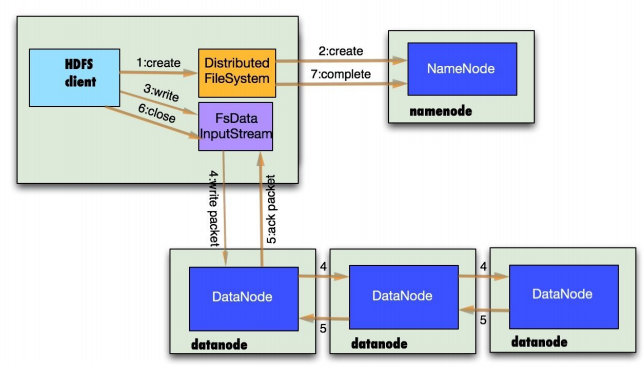
2. 目录结构
NameNode数据持久化的目录结构和文件如下:
├── current
│ ├── VERSION
│ ├──edits_0000000000000000001-0000000000000000007
│ ├──edits_0000000000000000008-0000000000000000015
│ ├──edits_0000000000000000016-0000000000000000022
│ ├── edits_0000000000000000023-0000000000000000029
│ ├──edits_0000000000000000030-0000000000000000030
│ ├──edits_0000000000000000031-0000000000000000031
│ ├──edits_inprogress_0000000000000000032
│ ├──fsimage_0000000000000000030
│ ├──fsimage_0000000000000000030.md5
│ ├──fsimage_0000000000000000031
│ ├──fsimage_0000000000000000031.md5
│ └── seen_txid
└── in_use.lock
in_use.lock是防止同台主机启动多份NameNode进程。
edits文件是增量命令操作记录文件,类似Oracle的redo log
fsimage 文件是某个checkpoint瞬间的内存快照文件,另外对应一份md5的校验文件
VERSION文件保存hdfs的一些版本信息和namespaceID,clusterID,blockpoolID,storageType等信息。
seen_txid 文件存储着最新的edits_inprogress的id
DataNode数据持久化的目录结构和文件如下:
├── current
│ ├──BP-1079595417-192.168.2.45-1412613236271
│ │ ├── current
│ │ │ ├── VERSION
│ │ │ ├── finalized
│ │ │ │ └── subdir0
│ │ │ │ └── subdir1
│ │ │ │ ├──blk_1073741825
│ │ │ │ └──blk_1073741825_1001.meta
│ │ │ │── lazyPersist
│ │ │ └── rbw
│ │ ├──dncp_block_verification.log.curr
│ │ ├──dncp_block_verification.log.prev
│ │ └── tmp
│ └── VERSION
└── in_use.lock
BP-1079595417-192.168.2.45-1412613236271 目录名就是NameNode中VERSION保存的blockpoolID
Finalized/ rbw 存放的是真正的文件数据block文件如blk_1073741825,对应一份.meta文件,存储blk_1073741825的checksum信息
dncp_block_verification.log 存放每个block最后修改后的checksum信息
in_use.lock 类似NameNode
3. 配置文件
核心配置文件有两个:core-site.xml和hdfs-site.xml存放在conf目录下
hdfs-site.xml:
dfs.namenode.http-address :namenode的http服务端口
dfs.namenode.rpc-address.cs1.nn1:namenode 的rpc访问端口
dfs.datanode.http.address:datanode的http服务端口
dfs.replication:默认备份数
dfs.datanode.data.dir:datanode的持久化目录
dfs.namenode.name.dir:namenode持久化目录
dfs.blocksize:block的最大大小
dfs.namenode.checkpoint.period:namenodecheckpoint快照(生成新的fsimage文件)的时间间隔
core-site.xml:
fs.defaultFS:active namenode的ip和端口
---由于xml 比较多,加上又没亲自进行安装,所以对xml的配置内容大概了解如上
4. 进程说明
用jps察看,大概有以下六大主要进程:
(1)NameNode :namenode服务进程
(2)DataNode:datanode 服务进程
(3)JournalNode:依赖于zookeeper,namenode的每条edit记录都要发送给大部分的JournalNode集群节点,以便secondary namenode从该集群中读取变更操作信息,保持active namenode和secondary namenode的数据一致性。要求节点数大于3并且为奇数。
(4)DFSZKFailoverController:依赖于zookeeper,当所在节点的activenamenode进程出现错误时向zookeeper发送信息,secondary namenode所在节点的DFSZKFailoverController进程会读取改信息,以便转成新的activenamenode,和JournalNode进程一起实现hdfs的HA(高可用)功能。所以一般只在active namenode和secondary namenode主机节上启动。
(5)NodeManager:NodeManager是运行在单个节点上的代理,它管理Hadoop集群中单个计算节点,功能包括与ResourceManager保持通信,管理Container的生命周期、监控每个Container的资源使用(内存、CPU等)情况、追踪节点健康状况、管理日志和不同应用程序用到的附属服务等。
(6)ResourceManager:ResourceManager负责集群中所有资源的统一管理和分配
--其实对NodeManager和ResourceManager进程的作用我也不是很理解,好像涉及到YARN概念和hadoop计算那块。
5. 其他细节
hdfs系统自带监控web服务功能,可以通过浏览器进行查看,如图
namenode节点:

Datanode节点:
















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









