







 本文深入探讨了Kafka的逻辑和物理数据模型、分发策略、持久化存储、查找数据的方法以及数据一致性策略。Kafka采用hash分发算法,通过Segment存储和索引文件实现高效查找。其独特的持久化策略利用操作系统pagecache,避免额外的内存拷贝,提高性能。同时,Kafka通过选举leader保证数据一致性,并依赖Zookeeper进行负载均衡。
本文深入探讨了Kafka的逻辑和物理数据模型、分发策略、持久化存储、查找数据的方法以及数据一致性策略。Kafka采用hash分发算法,通过Segment存储和索引文件实现高效查找。其独特的持久化策略利用操作系统pagecache,避免额外的内存拷贝,提高性能。同时,Kafka通过选举leader保证数据一致性,并依赖Zookeeper进行负载均衡。
最近在测试kafka的读写性能,所以借这个机会了解了kafka的一些设计原理,既然作为分布式系统,我们还是按照分布式的套路进行分析。
Kafka的逻辑数据模型:
生产者发送数据给服务端时,构造的是ProducerRecord<Integer, String>(String topic, Integer key,String value)对象并发送,从这个构造函数可以看到,kafka的表面逻辑数据模型是key-value。当然api再发送前还会在这个基础上加入若干校验信息,不过这个对用户而言是透明的。
Kafka的分发策略:
跟很多分布式多备份系统类似,kafka的基本网络结构如下:
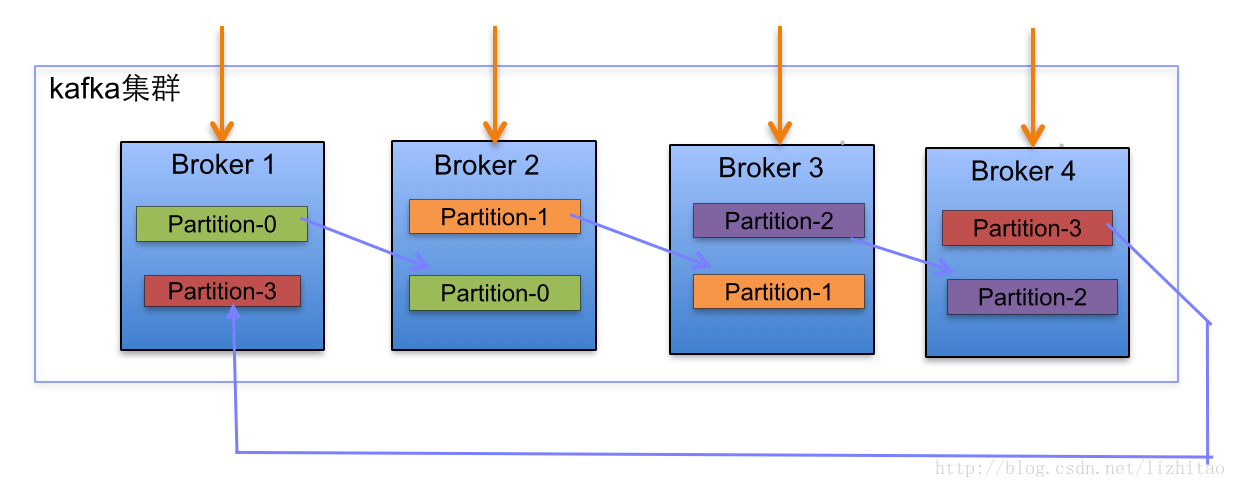
一个节点(Broker)中存有不同partition的备份,一个parittion存在多份备份保存在不同节点上并且选举出一个作为leader跟客户端交互,一个topic拥有多个parittion。
默认的kafka分发算法是hash(key)%numPartitions,简单来就是哈希再取模。当然这个算法可以自定义,只要重写相关接口。如上图在一个四台主机上创建了一个有两个备份,四个分区partion的话题topic,但生产者需要发送某个key-value对象到消息队列里面时,创建连接时通过访问z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









