







问题描述:
有字符串S = “s1,s2,s3…”和T = “t1,t2,t3,…”,查找T在S中出现的位置 (这里只找第一次出现的位置,若查找所有出现的位置,方法同)。T称为模式串。
如:S = “ABABCDABDEABCDAAAB”和T = “ABCD”,则T在S中出现,出现的位置是【2,10】
BF算法:
算法思想:从S开头开始匹配,一旦有不匹配的字符,就回退到最开始匹配的下一位。
- 从T的开头开始匹配,直至出现不匹配的字符:
T后移一位,继续步骤1
直至全部匹配
若要查找T在S中出现的所有位置,只需将T后移一位,继续步骤1。
BF代码:


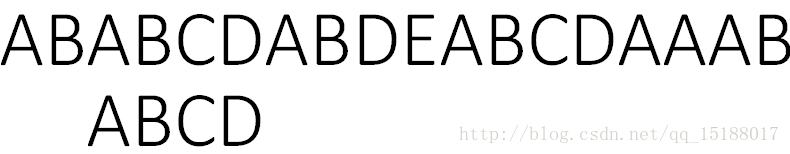
#include<iostream>
#include<string>
using namespace std;
int brute_force(string source, string pattern){
int result = -1;
auto len_source = source.size(),len_pattern = pattern.size();
size_t i,j;
for(i = 0, j = 0; i< len_source && j < len_pattern;){
if(source[i] == pattern[j]){
++i;
++j;
}
else{
i = i - j + 1;
j = 0;
//一旦开始从pattern头开始比较的时候,source后面待匹配的长度应该至少大于pattern的长度
if(i > len_source - len_pattern)
break;
}
}
if(j = len_pattern)
result = i-j;
return result;
}
int main(){
string s = "ABCDABABHNABA";
string p = "ABAB";
cout<<brute_force(s,p)<<endl;
return 0;
}KMP算法:
算法思想:在暴力法中,当遇到不匹配的字符时,T每次都是向右移动一位;在KMP算法中是,将T中已经匹配的部分的前缀移到相同的后缀处,若前缀和后缀没有相同的,则T的开头移到当前不匹配的字符位置。这个前缀和后缀的匹配关系,保存在数组next中。(移动的位数 = 已匹配的位数 - next数组中最后一个匹配的字符对应的值 -1)
下面我们先看一下什么是前缀和后缀:
对于串“ABCDEF”,前缀:{A,AB,ABC,ABCD,ABCDE}; 后缀:{F,EF,DEF,CDEF,BCDEF}
- 对于模式串T,建立一个数组:“ABCABE”的数组:
next[i]:T[i]及其之前的子串的前缀和后缀最长的共有元素的长度
如:
next[3]之所以为1,是因为T[3]之前(包括T[3])的子串“ABCAA”的最长的公共前后缀(“A”)的长度是1。
next[4]之所以是2,是因为T[4]之前的子串“ABCAB”的最长公共前后缀(“AB”)的长度是2。
当T的i位失配,就取next[i]计算出右移的位数:当i==1,右移位数=1;当i!=1,右移位数=i-next[i-1]。
next[0]之所以为0,是因为1个字母没有前后缀 S[0] !=T[0], T右移位数 = 1;
3.右移后,此时S[2]!=T[1];T右移位数:1 - next[0] = 1位
4.此时S[7]!=T[5];T右移位数:5 - next[4] = 3位;
5.此时S[7]!= T[2];T右移:2 - next[1] = 2位
6. 至此全部匹配,返回7。

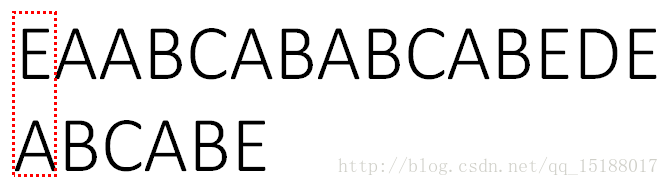
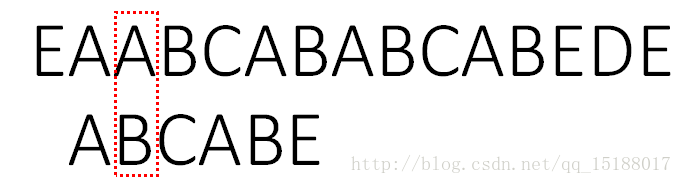


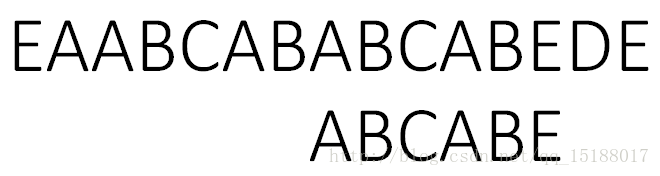
kmp算法C++代码实现:
#include<iostream>
#include<string>
#include<vector>
using namespace std;
void get_next(vector<int>& next,string pattern,size_t len_pattern){
//next的下标从0开始
size_t i,j;
next[0] = 0;
for(i = 1;i<len_pattern;++i){
j = next[i-1];//与pattern[i]进行比较的下标
while(j != 0 && pattern[i]!=pattern[j]){
j = next[j-1];//往前寻找可能匹配的子串
}
if(pattern[i] == pattern[j])
next[i] = j+1;
else
next[i] = 0;
}
}
int kmp(string source, string pattern){
auto len_source = source.size(),len_pattern = pattern.size();
vector<int> next(len_pattern);
get_next(next,pattern,len_pattern);
int i,j;
for(i = 0, j = 0; (i< len_source) && (j < len_pattern);){
if(source[i] == pattern[j]){
++j;
++i;
continue;
}
if(j!=0){
j = next[j-1];
}
else{
++i;
if(i> len_source - len_pattern)
break;
}
}
if(j==len_pattern)
return i-j;
else
return -1;
}
int main(){
int result = kmp("EAABCABABCABEDE","BCABED");
if(result == -1)
cout<<"匹配失败"<<endl;
else
cout<<"匹配成功,开始下标是:"<<result<<endl;
return 0;
}














 1721
1721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









