







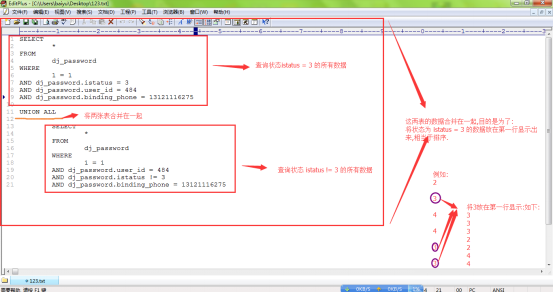
1、多表联级查询并分组
MySql数据库中
–1、查询重复数据–
select *, sum(1) as total from t_businessman group by longitude,latitude having total = 2;–2、根据id查询重复数据详细信息—-
select * from t_baiduapi where businessman_id = 1406;–3、 –先去除重复,去除后的数据将重新插入新表中,即就得到了没有重复后的数据了—-
INSERT INTO t_baiduapi select distinct * from table2 GROUP BY longitude,latitude;–4、 –通过distinct关键字去除重复数据—-
select distinct * from t_businessman; where longitude = '39.808475' and latitude = '116.49746';PS:distinct关键字儿在MySql好像是不起作用,所以只能用分组去除重复数据( Group by )!
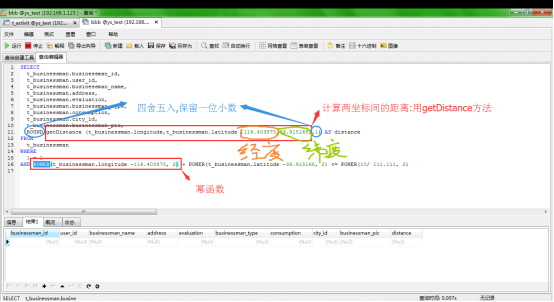
–5、 –经纬度计算(来算出两地的距离)(荐)—-
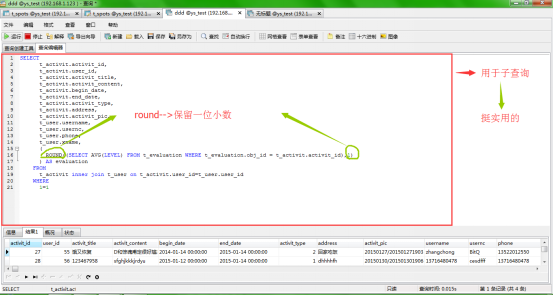
–6、 –子查询—-
代码附上:1、
drop function if exists getDistance;
DELIMITER $$
CREATE DEFINER=`root`@`localhost` FUNCTION `getDistance`(
lon1 float(10,7)
,lat1 float(10,7)
,lon2 float(10,7)
,lat2 float(10,7)
) RETURNS double
begin
declare d double;
declare radius int;
set radius = 6378140; #假设地球为正球形,直径为6378140米
set d = (2*ATAN2(SQRT(SIN((lat1-lat2)*PI()/180/2)
*SIN((lat1-lat2)*PI()/180/2)+
COS(lat2*PI()/180)*COS(lat1*PI()/180)
*SIN((lon1-lon2)*PI()/180/2)
*SIN((lon1-lon2)*PI()/180/2)),
SQRT(1-SIN((lat1-lat2)*PI()/180/2)
*SIN((lat1-lat2)*PI()/180/2)
+COS(lat2*PI()/180)*COS(lat1*PI()/180)
*SIN((lon1-lon2)*PI()/180/2)
*SIN((lon1-lon2)*PI()/180/2))))*radius;
return d;
end
$$
DELIMITER ;
select getDistance(116.3899,39.91578,116.3904,39.91576);
#查询数据 hotelinfo 表中的数据
2、
SELECT
hotelinfo.id,hotelinfo.address,
ROUND(getDistance(hotelinfo.longitude,hotelinfo.latitude,'116.354098','40.002223')) AS distance
FROM hotelinfo having distance <10;PS:查询数据的时候,尽量不要这样去查询,例如:
selcect * from student 这样是不大合理的,导致执行效率问题。相信你的老师教过你这些!















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











