






基本思想
在中文中,我们都知道汉字是由若干部分组成的,称为偏旁。而且偏旁也往往能够提供丰富的语义信息。比如,单人旁组成的字往往意指人,如“他”、“你”等;三点水为部首的字往往与水有关,如“海”、“江”等。因此,一个非常自然的想法就是将偏旁信息融入到词向量的生成过程中。Yanran Li等人发表的论文 《Component-Enhanced Chinese Character Embeddings》就是在这方面做得一个尝试。
引入
对于中文,现在分为简体字和繁体字,其文字的笔划是不一样的,这样对于同一个字和同一个部首,其表现形式是不一样的。如“食”作为部首时,在繁体字中是“飠”,而在简体字中是“饣”。为了解决这个不一致问题,该篇论文的作者将所有的字都转为了繁体字。其次作者认为一个字的部首比字的其他部分能够提供更加丰富的语义信息,因此只把部首作为额外的语义信息加入到字向量的生成过程中来。
具体方法
首先引入一些符号标记。假设有一个字序列D={z1, z2, …, zn}表示由字典V中的N个字组成的集合。令z表示一个汉字,c表示上下文信息,e表示部首列表,K表示向量的维度,T表示窗口的大小,M表示每个字考虑到的偏旁数量,并把第一个作为部首,V表示字典大小。
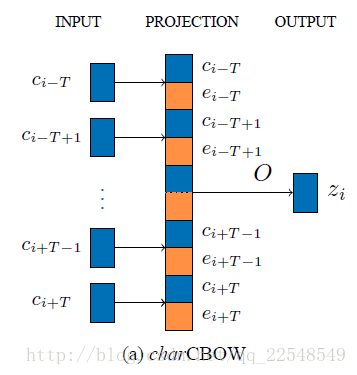
作者提出了两种模型,分别是charCBOW和charSkipGram,分别是基于CBOW和SkipGram模型的方法。这里以charCBOW模型为例进行介绍,其在CBOW模型的基础上做了两点改变:
- 首先是加入了部首信息
- 其次是将映射层原先的向量相加改成了向量的首尾相连
它的目标是使下面这个似然函数最大
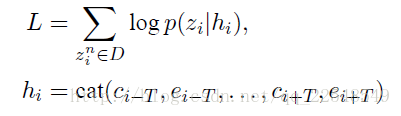
模型的图示如下














 4084
4084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









