









正如每个Java文档所描述的那样,CountDownLatch是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行。在Java并发中,countdownlatch的概念是一个常见的面试题,所以一定要确保你很好的理解了它。在这篇文章中,我将会涉及到在Java并发编 程中跟CountDownLatch相关的以下几点:
目录
- CountDownLatch是什么?
- CountDownLatch如何工作?
- 在实时系统中的应用场景
- 应用范例
- 常见的面试题
CountDownLatch是什么
CountDownLatch是在java1.5被引入的,跟它一起被引入的并发工具类还有CyclicBarrier、Semaphore、ConcurrentHashMap和BlockingQueue,它们都存在于java.util.concurrent包下。CountDownLatch这个类能够使一个线程等待其他线程完成各自的工作后再执行。例如,应用程序的主线程希望在负责启动框架服务的线程已经启动所有的框架服务之后再执行。
CountDownLatch是通过一个计数器来实现的,计数器的初始值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就会减1。当计数器值到达0时,它表示所有的线程已经完成了任务,然后在闭锁上等待的线程就可以恢复执行任务。

CountDownLatch的伪代码如下所示:
|
1
2
3
4
5
6
|
//Main thread start
//Create CountDownLatch for N threads
//Create and start N threads
//Main thread wait on latch
//N threads completes there tasks are returns
//Main thread resume execution
|
CountDownLatch如何工作
CountDownLatch.java类中定义的构造函数:
|
1
2
|
//Constructs a CountDownLatch initialized with the given count.
public
void
CountDownLatch(
int
count) {...}
|
构造器中的计数值(count)实际上就是闭锁需要等待的线程数量。这个值只能被设置一次,而且CountDownLatch没有提供任何机制去重新设置这个计数值。
与CountDownLatch的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
其他N 个线程必须引用闭锁对象,因为他们需要通知CountDownLatch对象,他们已经完成了各自的任务。这种通知机制是通过 CountDownLatch.countDown()方法来完成的;每调用一次这个方法,在构造函数中初始化的count值就减1。所以当N个线程都调 用了这个方法,count的值等于0,然后主线程就能通过await()方法,恢复执行自己的任务。
在实时系统中的使用场景
让我们尝试罗列出在java实时系统中CountDownLatch都有哪些使用场景。我所罗列的都是我所能想到的。如果你有别的可能的使用方法,请在留言里列出来,这样会帮助到大家。
- 实现最大的并行性:有时我们想同时启动多个线程,实现最大程度的并行性。例如,我们想测试一个单例类。如果我们创建一个初始计数为1的CountDownLatch,并让所有线程都在这个锁上等待,那么我们可以很轻松地完成测试。我们只需调用 一次countDown()方法就可以让所有的等待线程同时恢复执行。
- 开始执行前等待n个线程完成各自任务:例如应用程序启动类要确保在处理用户请求前,所有N个外部系统已经启动和运行了。
- 死锁检测:一个非常方便的使用场景是,你可以使用n个线程访问共享资源,在每次测试阶段的线程数目是不同的,并尝试产生死锁。
CountDownLatch使用例子
在这个例子中,我模拟了一个应用程序启动类,它开始时启动了n个线程类,这些线程将检查外部系统并通知闭锁,并且启动类一直在闭锁上等待着。一旦验证和检查了所有外部服务,那么启动类恢复执行。
BaseHealthChecker.java:这个类是一个Runnable,负责所有特定的外部服务健康的检测。它删除了重复的代码和闭锁的中心控制代码。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
public
abstract
class
BaseHealthChecker
implements
Runnable {
private
CountDownLatch _latch;
private
String _serviceName;
private
boolean
_serviceUp;
//Get latch object in constructor so that after completing the task, thread can countDown() the latch
public
BaseHealthChecker(String serviceName, CountDownLatch latch)
{
super
();
this
._latch = latch;
this
._serviceName = serviceName;
this
._serviceUp =
false
;
}
@Override
public
void
run() {
try
{
verifyService();
_serviceUp =
true
;
}
catch
(Throwable t) {
t.printStackTrace(System.err);
_serviceUp =
false
;
}
finally
{
if
(_latch !=
null
) {
_latch.countDown();
}
}
}
public
String getServiceName() {
return
_serviceName;
}
public
boolean
isServiceUp() {
return
_serviceUp;
}
//This methos needs to be implemented by all specific service checker
public
abstract
void
verifyService();
}
|
NetworkHealthChecker.java:这个类继承了BaseHealthChecker,实现了verifyService()方法。DatabaseHealthChecker.java和CacheHealthChecker.java除了服务名和休眠时间外,与NetworkHealthChecker.java是一样的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public
class
NetworkHealthChecker
extends
BaseHealthChecker
{
public
NetworkHealthChecker (CountDownLatch latch) {
super
(
"Network Service"
, latch);
}
@Override
public
void
verifyService()
{
System.out.println(
"Checking "
+
this
.getServiceName());
try
{
Thread.sleep(
7000
);
}
catch
(InterruptedException e)
{
e.printStackTrace();
}
System.out.println(
this
.getServiceName() +
" is UP"
);
}
}
|
ApplicationStartupUtil.java:这个类是一个主启动类,它负责初始化闭锁,然后等待,直到所有服务都被检测完。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
public
class
ApplicationStartupUtil
{
//List of service checkers
private
static
List<BaseHealthChecker> _services;
//This latch will be used to wait on
private
static
CountDownLatch _latch;
private
ApplicationStartupUtil()
{
}
private
final
static
ApplicationStartupUtil INSTANCE =
new
ApplicationStartupUtil();
public
static
ApplicationStartupUtil getInstance()
{
return
INSTANCE;
}
public
static
boolean
checkExternalServices()
throws
Exception
{
//Initialize the latch with number of service checkers
_latch =
new
CountDownLatch(
3
);
//All add checker in lists
_services =
new
ArrayList<BaseHealthChecker>();
_services.add(
new
NetworkHealthChecker(_latch));
_services.add(
new
CacheHealthChecker(_latch));
_services.add(
new
DatabaseHealthChecker(_latch));
//Start service checkers using executor framework
Executor executor = Executors.newFixedThreadPool(_services.size());
for
(
final
BaseHealthChecker v : _services)
{
executor.execute(v);
}
//Now wait till all services are checked
_latch.await();
//Services are file and now proceed startup
for
(
final
BaseHealthChecker v : _services)
{
if
( ! v.isServiceUp())
{
return
false
;
}
}
return
true
;
}
}
|
现在你可以写测试代码去检测一下闭锁的功能了。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public
class
Main {
public
static
void
main(String[] args)
{
boolean
result =
false
;
try
{
result = ApplicationStartupUtil.checkExternalServices();
}
catch
(Exception e) {
e.printStackTrace();
}
System.out.println(
"External services validation completed !! Result was :: "
+ result);
}
}
|
|
1
2
3
4
5
6
7
8
9
|
Output
in
console:
Checking Network Service
Checking Cache Service
Checking Database Service
Database Service is UP
Cache Service is UP
Network Service is UP
External services validation completed !! Result was ::
true
|
常见面试题
可以为你的下次面试准备以下一些CountDownLatch相关的问题:
- 解释一下CountDownLatch概念?
- CountDownLatch 和CyclicBarrier的不同之处?
- 给出一些CountDownLatch使用的例子?
- CountDownLatch 类中主要的方法?
BlockingQueue接口定义了一种阻塞的FIFO queue,每一个BlockingQueue都有一个容量,让容量满时往BlockingQueue中添加数据时会造成阻塞,当容量为空时取元素操作会阻塞。
ArrayBlockingQueue是一个由数组支持的有界阻塞队列。在读写操作上都需要锁住整个容器,因此吞吐量与一般的实现是相似的,适合于实现“生产者消费者”模式。
基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
ArrayBlockingQueue和LinkedBlockingQueue的区别:
1. 队列中锁的实现不同
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock
2. 在生产或消费时操作不同
ArrayBlockingQueue实现的队列中在生产和消费的时候,是直接将枚举对象插入或移除的;
LinkedBlockingQueue实现的队列中在生产和消费的时候,需要把枚举对象转换为Node<E>进行插入或移除,会影响性能
3. 队列大小初始化方式不同
ArrayBlockingQueue实现的队列中必须指定队列的大小;
LinkedBlockingQueue实现的队列中可以不指定队列的大小,但是默认是Integer.MAX_VALUE

- public class BlockingQueueTest {
- private static ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<Integer>(5, true); //最大容量为5的数组堵塞队列
- //private static LinkedBlockingQueue<Integer> queue = new LinkedBlockingQueue<Integer>(5);
- private static CountDownLatch producerLatch; //倒计时计数器
- private static CountDownLatch consumerLatch;
- public static void main(String[] args) {
- BlockingQueueTest queueTest = new BlockingQueueTest();
- queueTest.test();
- }
- private void test(){
- producerLatch = new CountDownLatch(10); //state值为10
- consumerLatch = new CountDownLatch(10); //state值为10
- Thread t1 = new Thread(new ProducerTask());
- Thread t2 = new Thread(new ConsumerTask());
- //启动线程
- t1.start();
- t2.start();
- try {
- System.out.println("producer waiting...");
- producerLatch.await(); //进入等待状态,直到state值为0,再继续往下执行
- System.out.println("producer end");
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- try {
- System.out.println("consumer waiting...");
- consumerLatch.await(); //进入等待状态,直到state值为0,再继续往下执行
- System.out.println("consumer end");
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- //结束线程
- t1.interrupt();
- t2.interrupt();
- System.out.println("end");
- }
- //生产者
- class ProducerTask implements Runnable{
- private Random rnd = new Random();
- @Override
- public void run() {
- try {
- while(true){
- queue.put(rnd.nextInt(100)); //如果queue容量已满,则当前线程会堵塞,直到有空间再继续
- //offer方法为非堵塞的
- //queue.offer(rnd.nextInt(100), 1, TimeUnit.SECONDS); //等待1秒后还不能加入队列则返回失败,放弃加入
- //queue.offer(rnd.nextInt(100));
- producerLatch.countDown(); //state值减1
- //TimeUnit.SECONDS.sleep(2); //线程休眠2秒
- }
- } catch (InterruptedException e) {
- //e.printStackTrace();
- } catch (Exception ex){
- ex.printStackTrace();
- }
- }
- }
- //消费者
- class ConsumerTask implements Runnable{
- @Override
- public void run() {
- try {
- while(true){
- Integer value = queue.take(); //如果queue为空,则当前线程会堵塞,直到有新数据加入
- //poll方法为非堵塞的
- //Integer value = queue.poll(1, TimeUnit.SECONDS); //等待1秒后还没有数据可取则返回失败,放弃获取
- //Integer value = queue.poll();
- System.out.println("value = " + value);
- consumerLatch.countDown(); //state值减1
- TimeUnit.SECONDS.sleep(2); //线程休眠2秒
- }
- } catch (InterruptedException e) {
- //e.printStackTrace();
- } catch (Exception ex){
- ex.printStackTrace();
- }
- }
- }
- }
28. wait()和sleep()的区别。
对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。
在调用sleep()方法的过程中,线程不会释放对象锁。
而当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备
获取对象锁进入运行状态。
Java中经常会用到迭代列表数据的情况,本文针对几种常用的写法进行效率比较。虽然网上已经有了类似的文章,但是对他们的结论并不认同。
常见的实现方法:
1.for循环:
- for(int i = 0; i < list.size(); i++)
- for(int i = 0, size = list.size(); i < size; i++)
2.foreach:
- for(Object obj : list)
这是一种简洁的写法,只能对列表进行读取,无法修改。
3.while:
- int size = list.size();
- while(size-- > 0)
4.迭代:
- Object iter = list.iterator();
- while(iter.hasNext()) {
- iter.next();
- }
测试代码:
针对以上几种方法编写的测试代码。- public static void main(String[] args) {
- List<Integer> list = new ArrayList<Integer>();
- int runTime = 1000;//执行次数
- for (int i = 0; i < 1000 * 1000; i++) {
- list.add(i);
- }
- int size = list.size();
- long currTime = System.currentTimeMillis();//开始分析前的系统时间
- //基本的for
- for(int j = 0; j < runTime; j++) {
- for (int i = 0; i < size; i++) {
- list.get(i);
- }
- }
- long time1 = System.currentTimeMillis();
- //foreach
- for(int j = 0; j < runTime; j++) {
- for (Integer integer : list) {
- }
- }
- long time2 = System.currentTimeMillis();
- for(int j = 0; j < runTime; j++) {
- //while
- int i = 0 ;
- while(i < size){
- list.get(i++);
- }
- }
- long time3 = System.currentTimeMillis();
- for(int j = 0; j < runTime; j++) {//普通for循环
- for (int i = 0; i < list.size(); i++) {
- list.get(i);
- }
- }
- long time4 = System.currentTimeMillis();
- for(int j = 0; j < runTime; j++) {//迭代
- Iterator<Integer> iter = list.iterator();
- while(iter.hasNext()) {
- iter.next();
- }
- }
- long time5 = System.currentTimeMillis();
- long time = time1 - currTime ;
- System.out.print("use for:" + time);
- time = time2 - time1;
- System.out.print("\tuse foreach:" + time);
- time = time3 - time2;
- System.out.print("\tuse while:" + time);
- time = time4 - time3;
- System.out.print("\tuse for2:" + time);
- time = time5 - time4;
- System.out.print("\tuse iterator:" + time);
- System.out.println();
- }
输出结果(JDK1.6):
1.
use for:8695 use foreach:17091 use while:6867 use for2:7741 use iterator:14144
2.
use for:8432 use foreach:18126 use while:6905 use for2:7893 use iterator:13976
3.
use for:8584 use foreach:17177 use while:6875 use for2:7707 use iterator:14345
结论:
1.针对列表的 foreach的效率是最低:
耗时是普通for循环的2倍以上。个人理解它的实现应该和iterator相似。
2. list.size()的开销很小:
list.size()次数多少对效率基本没有影响。查看ArrayList的实现就会发现,size()方法的只是返回了对象内的长度属性,并没有其它计算,所以只存在函数调用的开销。
对数组的测试:
应该主要是检测数据合法性时产生的。
将执行次数增加100万倍,这时可以看出结果基本相等,并没有明显的差异。说明:
4. 数组length也没有开销
可见数组长度并不是每次执行的时候都要计算的。联想一下Java创建数组的时候要求必须指定数组的长度,编译处理的时候显然没有把这个值抛弃掉。
30. Java IO与NIO。
内核空间、用户空间、计算机体系结构、计算机组成原理、……确实有点儿深奥。
我的新书《代码之谜》会有专门的章节讲解相关知识,现在写个简短的科普文:
就速度来说 CPU > 内存 > 硬盘
I- 就是从硬盘到内存O- 就是从内存到硬盘
第一种方式:我从硬盘读取数据,然后程序一直等,![]() 数据读完后,继续操作。这种方式是最简单的,叫阻塞IO。
数据读完后,继续操作。这种方式是最简单的,叫阻塞IO。
第二种方式:我从硬盘读取数据,然后程序继续向下执行,等数据读取完后,通知当前程序(对硬件来说叫中断,对程序来说叫回调),然后此程序可以立即处理数据,也可以执行完当前操作在读取数据。
在以前的 Java IO 中,都是阻塞式 IO,NIO 引入了非阻塞式 IO。
还有一种就是同步 IO 和异步 IO。经常说的一个术语就是“异步非阻塞”,好象异步和非阻塞是同一回事,这大概是一个误区吧。
至于 Java NIO 的 Selector,在旧的 Java IO 系统中,是基于 Stream 的,即“流”,流式 IO。
当程序从硬盘往内存读取数据的时候,操作系统使用了 2 个“小伎俩”来提高性能,那就是预读,如果我读取了第一扇区的第三磁道的内容,那么你很有可能也会使用第二磁道和第四磁道的内容,所以操作系统会把附近磁道的内容提前读取出来,放在内存中,![]() 即缓存。
即缓存。
(PS:以上过程简化了)
通过上面可以看到,操作系统是按块 Block从硬盘拿数据,就如同一个大脸盆,一下子就放入了一盆水。但是,当 Java 使用的时候,旧的 IO 确实基于 流 Stream的,也就是虽然操作系统给我了一脸盆水,但是我得用吸管慢慢喝。
于是,NIO 横空出世。
总的来说,java中的IO和NIO主要有三点区别:
| IO | NIO |
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器(Selectors) |
1.面向流与面向缓冲
Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2.阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
3.选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
下面着重谈一下阻塞和非阻塞各自的优势:
通常的,对一个文件描述符指定的文件或设备, 有两种工作方式: 阻塞与非阻塞。所谓阻塞方式的意思是指, 当试图对该文件描述符进行读写时, 如果当时没有东西可读,或者暂时不可写, 程序就进入等待状态, 直到有东西可读或者可写为止。而对于非阻塞状态, 如果没有东西可读, 或者不可写, 读写函数马上返回, 而不会等待。
传统的socket IO中,需要为每个连接创建一个线程,当并发的连接数量非常巨大时,线程所占用的栈内存和CPU线程切换的开销将非常巨大。这种方式具有很高的响应速度,并且控制起来也很简单,在连接数较少的时候非常有效,但是如果对每一个连接都产生一个线程的无疑是对系统资源的一种浪费,如果连接数较多将会出现资源不足的情况。
使用NIO,不再需要为每个线程创建单独的线程,可以用一个含有限数量线程的线程池,甚至一个线程来为任意数量的连接服务。由于线程数量小于连接数量,所以每个线程进行IO操作时就不能阻塞,如果阻塞的话,有些连接就得不到处理,NIO提供了这种非阻塞的能力。
小量的线程如何同时为大量连接服务呢,答案就是就绪选择。这就好比到餐厅吃饭,每来一桌客人,都有一个服务员专门为你服务,从你到餐厅到结帐走人,这样方式的好处是服务质量好,一对一的服务,VIP啊,可是缺点也很明显,成本高,如果餐厅生意好,同时来100桌客人,就需要100个服务员,那老板发工资的时候得心痛死了,这就是传统的一个连接一个线程的方式。
老板是什么人啊,精着呢。这老板就得捉摸怎么能用10个服务员同时为100桌客人服务呢,老板就发现,服务员在为客人服务的过程中并不是一直都忙着,客人点完菜,上完菜,吃着的这段时间,服务员就闲下来了,可是这个服务员还是被这桌客人占用着,不能为别的客人服务,用华为领导的话说,就是工作不饱满。那怎么把这段闲着的时间利用起来呢。这餐厅老板就想了一个办法,让一个服务员(前台)专门负责收集客人的需求,登记下来,比如有客人进来了、客人点菜了,客人要结帐了,都先记录下来按顺序排好。每个服务员到这里领一个需求,比如点菜,就拿着菜单帮客人点菜去了。点好菜以后,服务员马上回来,领取下一个需求,继续为别人客人服务去了。这种方式服务质量就不如一对一的服务了,当客人数据很多的时候可能需要等待。但好处也很明显,由于在客人正吃饭着的时候服务员不用闲着了,服务员这个时间内可以为其他客人服务了,原来10个服务员最多同时为10桌客人服务,现在可能为50桌,60客人服务了。
这种服务方式跟传统的区别有两个:
1、增加了一个角色,要有一个专门负责收集客人需求的人。NIO里对应的就是Selector。
2、由阻塞服务方式改为非阻塞服务了,客人吃着的时候服务员不用一直侯在客人旁边了。传统的IO操作,比如read(),当没有数据可读的时候,线程一直阻塞被占用,直到数据到来。NIO中没有数据可读时,read()会立即返回0,线程不会阻塞。
NIO 设计背后的基石:反应器(Reactor)模式,用于事件多路分离和分派的体系结构模式。NIO中,客户端创建一个连接后,先要将连接注册到Selector,相当于客人进入餐厅后,告诉前台你要用餐,前台会告诉你你的桌号是几号,然后你就可能到那张桌子坐下了,SelectionKey就是桌号。当某一桌需要服务时,前台就记录哪一桌需要什么服务,比如1号桌要点菜,2号桌要结帐,服务员从前台取一条记录,根据记录提供服务,完了再来取下一条。这样服务的时间就被最有效的利用起来了。
J2SE1.4以上版本中发布了全新的I/O类库。本文将通过一些实例来简单介绍NIO库提供的一些新特性:非阻塞I/O,字符转换,缓冲以及通道。
一. 介绍NIO
NIO包(java.nio.*)引入了四个关键的抽象数据类型,它们共同解决传统的I/O类中的一些问题。
1. Buffer:它是包含数据且用于读写的线形表结构。其中还提供了一个特殊类用于内存映射文件的I/O操作。
2. Charset:它提供Unicode字符串影射到字节序列以及逆影射的操作。
3. Channels:包含socket,file和pipe三种管道,它实际上是双向交流的通道。
4. Selector:它将多元异步I/O操作集中到一个或多个线程中(它可以被看成是Unix中select()函数或Win32中WaitForSingleEvent()函数的面向对象版本)。
二. 回顾传统
在介绍NIO之前,有必要了解传统的I/O操作的方式。以网络应用为例,传统方式需要监听一个ServerSocket,接受请求的连接为其提供服务(服务通常包括了处理请求并发送响应)图一是服务器的生命周期图,其中标有粗黑线条的部分表明会发生I/O阻塞。
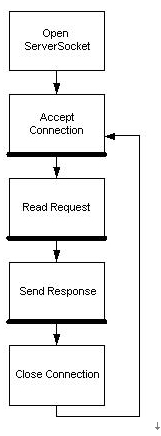
图一
可以分析创建服务器的每个具体步骤。首先创建ServerSocket
ServerSocket server=new ServerSocket(10000);
然后接受新的连接请求
Socket newConnection=server.accept();
对于accept方法的调用将造成阻塞,直到ServerSocket接受到一个连接请求为止。一旦连接请求被接受,服务器可以读客户socket中的请求。
InputStream in = newConnection.getInputStream();
InputStreamReader reader = new InputStreamReader(in);
BufferedReader buffer = new BufferedReader(reader);
Request request = new Request();
while(!request.isComplete()) {
String line = buffer.readLine();
request.addLine(line);
}
这样的操作有两个问题,首先BufferedReader类的readLine()方法在其缓冲区未满时会造成线程阻塞,只有一定数据填满了缓冲区或者客户关闭了套接字,方法才会返回。其次,它回产生大量的垃圾,BufferedReader创建了缓冲区来从客户套接字读入数据,但是同样创建了一些字符串存储这些数据。虽然BufferedReader内部提供了StringBuffer处理这一问题,但是所有的String很快变成了垃圾需要回收。
同样的问题在发送响应代码中也存在
Response response = request.generateResponse();
OutputStream out = newConnection.getOutputStream();
InputStream in = response.getInputStream();
int ch;
while(-1 != (ch = in.read())) {
out.write(ch);
}
newConnection.close();
类似的,读写操作被阻塞而且向流中一次写入一个字符会造成效率低下,所以应该使用缓冲区,但是一旦使用缓冲,流又会产生更多的垃圾。
传统的解决方法
通常在Java中处理阻塞I/O要用到线程(大量的线程)。一般是实现一个线程池用来处理请求,如图二

图二
线程使得服务器可以处理多个连接,但是它们也同样引发了许多问题。每个线程拥有自己的栈空间并且占用一些CPU时间,耗费很大,而且很多时间是浪费在阻塞的I/O操作上,没有有效的利用CPU。
三. 新I/O
1. Buffer
传统的I/O不断的浪费对象资源(通常是String)。新I/O通过使用Buffer读写数据避免了资源浪费。Buffer对象是线性的,有序的数据集合,它根据其类别只包含唯一的数据类型。
java.nio.Buffer 类描述
java.nio.ByteBuffer 包含字节类型。 可以从ReadableByteChannel中读在 WritableByteChannel中写
java.nio.MappedByteBuffer 包含字节类型,直接在内存某一区域映射
java.nio.CharBuffer 包含字符类型,不能写入通道
java.nio.DoubleBuffer 包含double类型,不能写入通道
java.nio.FloatBuffer 包含float类型
java.nio.IntBuffer 包含int类型
java.nio.LongBuffer 包含long类型
java.nio.ShortBuffer 包含short类型
可以通过调用allocate(int capacity)方法或者allocateDirect(int capacity)方法分配一个Buffer。特别的,你可以创建MappedBytesBuffer通过调用FileChannel.map(int mode,long position,int size)。直接(direct)buffer在内存中分配一段连续的块并使用本地访问方法读写数据。非直接(nondirect)buffer通过使用Java中的数组访问代码读写数据。有时候必须使用非直接缓冲例如使用任何的wrap方法(如ByteBuffer.wrap(byte[]))在Java数组基础上创建buffer。
2. 字符编码
向ByteBuffer中存放数据涉及到两个问题:字节的顺序和字符转换。ByteBuffer内部通过ByteOrder类处理了字节顺序问题,但是并没有处理字符转换。事实上,ByteBuffer没有提供方法读写String。
Java.nio.charset.Charset处理了字符转换问题。它通过构造CharsetEncoder和CharsetDecoder将字符序列转换成字节和逆转换。
3. 通道(Channel)
你可能注意到现有的java.io类中没有一个能够读写Buffer类型,所以NIO中提供了Channel类来读写Buffer。通道可以认为是一种连接,可以是到特定设备,程序或者是网络的连接。通道的类等级结构图如下
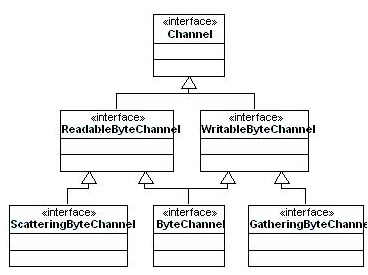
图三
图中ReadableByteChannel和WritableByteChannel分别用于读写。
GatheringByteChannel可以从使用一次将多个Buffer中的数据写入通道,相反的,ScatteringByteChannel则可以一次将数据从通道读入多个Buffer中。你还可以设置通道使其为阻塞或非阻塞I/O操作服务。
为了使通道能够同传统I/O类相容,Channel类提供了静态方法创建Stream或Reader
4. Selector
在过去的阻塞I/O中,我们一般知道什么时候可以向stream中读或写,因为方法调用直到stream准备好时返回。但是使用非阻塞通道,我们需要一些方法来知道什么时候通道准备好了。在NIO包中,设计Selector就是为了这个目的。SelectableChannel可以注册特定的事件,而不是在事件发生时通知应用,通道跟踪事件。然后,当应用调用Selector上的任意一个selection方法时,它查看注册了的通道看是否有任何感兴趣的事件发生。图四是selector和两个已注册的通道的例子

图四
并不是所有的通道都支持所有的操作。SelectionKey类定义了所有可能的操作位,将要用两次。首先,当应用调用SelectableChannel.register(Selector sel,int op)方法注册通道时,它将所需操作作为第二个参数传递到方法中。然后,一旦SelectionKey被选中了,SelectionKey的readyOps()方法返回所有通道支持操作的数位的和。SelectableChannel的validOps方法返回每个通道允许的操作。注册通道不支持的操作将引发IllegalArgumentException异常。下表列出了SelectableChannel子类所支持的操作。
ServerSocketChannel OP_ACCEPT
SocketChannel OP_CONNECT, OP_READ, OP_WRITE
DatagramChannel OP_READ, OP_WRITE
Pipe.SourceChannel OP_READ
Pipe.SinkChannel OP_WRITE
四. 举例说明
1. 简单网页内容下载
这个例子非常简单,类SocketChannelReader使用SocketChannel来下载特定网页的HTML内容。
package examples.nio;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
import java.net.InetSocketAddress;
import java.io.IOException;
public class SocketChannelReader{
private Charset charset=Charset.forName("UTF-8");//创建UTF-8字符集
private SocketChannel channel;
public void getHTMLContent(){
try{
connect();
sendRequest();
readResponse();
}catch(IOException e){
System.err.println(e.toString());
}finally{
if(channel!=null){
try{
channel.close();
}catch(IOException e){}
}
}
}
private void connect()throws IOException{//连接到CSDN
InetSocketAddress socketAddress=
new InetSocketAddress("http://www.csdn.net",80/);
channel=SocketChannel.open(socketAddress);
//使用工厂方法open创建一个channel并将它连接到指定地址上
//相当与SocketChannel.open().connect(socketAddress);调用
}
private void sendRequest()throws IOException{
channel.write(charset.encode("GET "
+"/document"
+"\r\n\r\n"));//发送GET请求到CSDN的文档中心
//使用channel.write方法,它需要CharByte类型的参数,使用
//Charset.encode(String)方法转换字符串。
}
private void readResponse()throws IOException{//读取应答
ByteBuffer buffer=ByteBuffer.allocate(1024);//创建1024字节的缓冲
while(channel.read(buffer)!=-1){
buffer.flip();//flip方法在读缓冲区字节操作之前调用。
System.out.println(charset.decode(buffer));
//使用Charset.decode方法将字节转换为字符串
buffer.clear();//清空缓冲
}
}
public static void main(String [] args){
new SocketChannelReader().getHTMLContent();
}
2. 简单的加法服务器和客户机
服务器代码
package examples.nio;
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.net.InetSocketAddress;
import java.io.IOException;
/**
* SumServer.java
*
*
* Created: Thu Nov 06 11:41:52 2003
*
* @author starchu1981
* @version 1.0
*/
public class SumServer {
private ByteBuffer _buffer=ByteBuffer.allocate(8);
private IntBuffer _intBuffer=_buffer.asIntBuffer();
private SocketChannel _clientChannel=null;
private ServerSocketChannel _serverChannel=null;
public void start(){
try{
openChannel();
waitForConnection();
}catch(IOException e){
System.err.println(e.toString());
}
}
private void openChannel()throws IOException{
_serverChannel=ServerSocketChannel.open();
_serverChannel.socket().bind(new InetSocketAddress(10000));
System.out.println("服务器通道已经打开");
}
private void waitForConnection()throws IOException{
while(true){
_clientChannel=_serverChannel.accept();
if(_clientChannel!=null){
System.out.println("新的连接加入");
processRequest();
_clientChannel.close();
}
}
}
private void processRequest()throws IOException{
_buffer.clear();
_clientChannel.read(_buffer);
int result=_intBuffer.get(0)+_intBuffer.get(1);
_buffer.flip();
_buffer.clear();
_intBuffer.put(0,result);
_clientChannel.write(_buffer);
}
public static void main(String [] args){
new SumServer().start();
}
} // SumServer
客户代码
package examples.nio;
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.nio.channels.SocketChannel;
import java.net.InetSocketAddress;
import java.io.IOException;
/**
* SumClient.java
*
*
* Created: Thu Nov 06 11:26:06 2003
*
* @author starchu1981
* @version 1.0
*/
public class SumClient {
private ByteBuffer _buffer=ByteBuffer.allocate(8);
private IntBuffer _intBuffer;
private SocketChannel _channel;
public SumClient() {
_intBuffer=_buffer.asIntBuffer();
} // SumClient constructor
public int getSum(int first,int second){
int result=0;
try{
_channel=connect();
sendSumRequest(first,second);
result=receiveResponse();
}catch(IOException e){System.err.println(e.toString());
}finally{
if(_channel!=null){
try{
_channel.close();
}catch(IOException e){}
}
}
return result;
}
private SocketChannel connect()throws IOException{
InetSocketAddress socketAddress=
new InetSocketAddress("localhost",10000);
return SocketChannel.open(socketAddress);
}
private void sendSumRequest(int first,int second)throws IOException{
_buffer.clear();
_intBuffer.put(0,first);
_intBuffer.put(1,second);
_channel.write(_buffer);
System.out.println("发送加法请求 "+first+"+"+second);
}
private int receiveResponse()throws IOException{
_buffer.clear();
_channel.read(_buffer);
return _intBuffer.get(0);
}
public static void main(String [] args){
SumClient sumClient=new SumClient();
System.out.println("加法结果为 :"+sumClient.getSum(100,324));
}
} // SumClient
3. 非阻塞的加法服务器
首先在openChannel方法中加入语句
_serverChannel.configureBlocking(false);//设置成为非阻塞模式
重写WaitForConnection方法的代码如下,使用非阻塞方式
private void waitForConnection()throws IOException{
Selector acceptSelector = SelectorProvider.provider().openSelector();
/*在服务器套接字上注册selector并设置为接受accept方法的通知。
这就告诉Selector,套接字想要在accept操作发生时被放在ready表
上,因此,允许多元非阻塞I/O发生。*/
SelectionKey acceptKey = ssc.register(acceptSelector,
SelectionKey.OP_ACCEPT);
int keysAdded = 0;
/*select方法在任何上面注册了的操作发生时返回*/
while ((keysAdded = acceptSelector.select()) > 0) {
// 某客户已经准备好可以进行I/O操作了,获取其ready键集合
Set readyKeys = acceptSelector.selectedKeys();
Iterator i = readyKeys.iterator();
// 遍历ready键集合,并处理加法请求
while (i.hasNext()) {
SelectionKey sk = (SelectionKey)i.next();
i.remove();
ServerSocketChannel nextReady =
(ServerSocketChannel)sk.channel();
// 接受加法请求并处理它
_clientSocket = nextReady.accept().socket();
processRequest();
_clientSocket.close();
}
}
}
JAVA反射(放射)机制:“程序运行时,允许改变程序结构或变量类型,这种语言称为动态语言”。从这个观点看,Perl,Python,Ruby是动态语言,C++,Java,C# 不是动态语言。但是JAVA有着一个非常突出的动态相关机制:Reflection,用在Java身上指的是我们可以于运行时加载、探知、使用编译期间完 全未知的classes。换句话说,Java程序可以加载一个运行时才得知名称的class,获悉其完整构造(但不包括methods定义),并生成其对 象实体、或对其fields设值、或唤起其methods。 用途:Java反射机制主要提供了以下功能: 在运行时判断任意一个对象所属的类;在运行时构造任意一个类的对象;在运行时判断任意一个类所具有的成员变量和方法;在运行时调用任意一个对象的方法;生成动态代理。 有时候我们说某个语言具有很强的动态性,有时候我们会区分动态和静态的不同技术与作法。我们朗朗上口动态绑定(dynamic binding)、动态链接(dynamic linking)、动态加载(dynamic loading)等。然而“动态”一词其实没有绝对而普遍适用的严格定义,有时候甚至像面向对象当初被导入编程领域一样,一人一把号,各吹各的调。 一般而言,开发者社群说到动态语言,大致认同的一个定义是:“程序运行时,允许改变程序结构或变量类型,这种语言称为动态语言”。从这个观点看,Perl,Python,Ruby是动态语言,C++,Java,C#不是动态语言。 尽管在这样的定义与分类下Java不是动态语言,它却有着一个非常突出的动态相关机制:Reflection。 这个字的意思是“反射、映象、倒影”,用在Java身上指的是我们可以于运行时加载、探知、使用编译期间完全未知的classes。换句话说,Java程 序可以加载一个运行时才得知名称的class,获悉其完整构造(但不包括methods定义),并生成其对象实体、或对其fields设值、或唤起其 methods。这种“看透class”的能力(the ability of the program to examine itself)被称为introspection(内省、内观、反省)。Reflection和introspection是常被并提的两个术语。 Java如何能够做出上述的动态特性呢?这是一个深远话题,本文对此只简单介绍一些概念。整个篇幅最主要还是介绍 Reflection APIs,也就是让读者知道如何探索class的结构、如何对某个“运行时才获知名称的class”生成一份实体、为其fields设值、调用其 methods。本文将谈到java.lang.Class,以及java.lang.reflect中的Method、Field、Constructor等等classes。
32. 泛型常用特点,List<String>能否转为List<Object>。
所谓泛型,就是变量类型的参数化。
泛型是JDK1.5中一个最重要的特征。通过引入泛型,我们将获得编译时类型的安全和运行时更小的抛出ClassCastException的可能。
在JDK1.5中,你可以声明一个集合将接收/返回的对象的类型。
使用泛型时如果不指明参数类型,即泛型类没有参数化,会提示警告,此时类型为Object。
为什么使用泛型
使用泛型的典型例子,是在集合中的泛型使用。
在使用泛型前,存入集合中的元素可以是任何类型的,当从集合中取出时,所有的元素都是Object类型,需要进行向下的强制类型转换,转换到特定的类型。
比如:
List myIntList = new LinkedList(); // 1 myIntList.add(new Integer(0)); // 2 Integer x = (Integer) myIntList.iterator().next(); // 3
第三行的这个强制类型转换可能会引起运行时的错误。
泛型的思想就是由程序员指定类型,这样集合就只能容纳该类型的元素。
使用泛型:
List<Integer> myIntList = new LinkedList<Integer>(); // 1' myIntList.add(new Integer(0)); // 2' Integer x = myIntList.iterator().next(); // 3'
将第三行的强制类型转换变为了第一行的List类型说明,编译器会为我们检查类型的正确性。这样,代码的可读性和健壮性也会增强。
泛型使用基础
例如:

public interface List <E> { void add(E x); Iterator<E> iterator(); } public interface Iterator<E> { E next(); boolean hasNext(); }
尖括号中包含的是形式类型参数(formal type parameters),它们就如同一般的类型一样,可以在整个类的声明中被使用。
当类被使用时,会使用具体的实际类型参数(actual type argument)代替。
比如前面的例子中的List<Integer>,那么所有的E将会被Integer类型所代替。
泛型类型参数只能被类或接口类型赋值,不能被原生数据类型赋值,原生数据类型需要使用对应的包装类。
形式类型参数的命名:尽量使用单个的大写字母(有时候多个泛型类型时会加上数字,比如T1,T2),比如许多容器集合使用E,代表element(元素),Map中用K代表键keys,V代表值。
泛型容器的实现讨论
不能用new的形式来创建一个泛型数组。
如下:
public class SimpleCollection<T> { private T[] objArr; private int index = 0; public SimpleCollection() { //Error: Cannot create a generic array of T objArr = new T[10]; } }
会报错。
如何创建一个数组让它接受所有可能的类型呢?
public class SimpleCollection<T> { private T[] objArr; private int index = 0; public SimpleCollection() { //Error: Cannot create a generic array of T //objArr = new T[10]; //Warning: Unchecked cast from Object[] to T[] objArr = (T[]) new Object[10]; } }
这个形式虽然可以做到,但是会产生一个警告。
查看ArrayList中的实现,可以发现它是使用了一个Object类型的数组:
private transient Object[] elementData;
在取出的时候(get方法中)使用了类型转换:
(E) elementData[index];
泛型和子类
List<String> ls = new ArrayList<String>(); // 1 List<Object> lo = ls; // 2
一个String类型的List是一个Object类的List吗?
不可以,Java编译器将会在第二行产生一个编译错误,因为它们的类型不匹配。
这样就避免了如果lo引入加入Object类型的对象,而ls引用试图将其转换为String类型而引发错误。所以编译器阻止了这种可能。
继承泛型类别
直接用例子说明:
父类:
public class Parent<T1,T2> { private T1 foo1; private T2 foo2; public T1 getFoo1() { return foo1; } public void setFoo1(T1 foo1) { this.foo1 = foo1; } public T2 getFoo2() { return foo2; } public void setFoo2(T2 foo2) { this.foo2 = foo2; } }
子类继承父类:
public class Child<T1, T2, T3> extends Parent<T1, T2> { private T3 foo3; public T3 getFoo3() { return foo3; } public void setFoo3(T3 foo3) { this.foo3 = foo3; } }
实现泛型接口
见例子:
泛型接口:
public interface ParentInterface<T1,T2> { public void setFoo1(T1 foo1); public void setFoo2(T2 foo2); public T1 getFoo1(); public T2 getFoo2(); }
子类实现泛型接口:
public class ChildClass<T1,T2> implements ParentInterface<T1, T2> { private T1 foo1; private T2 foo2; @Override public void setFoo1(T1 foo1) { this.foo1 = foo1; } @Override public void setFoo2(T2 foo2) { this.foo2 = foo2; } @Override public T1 getFoo1() { return this.foo1; } @Override public T2 getFoo2() { return this.foo2; } }
一. 泛型概念的提出(为什么需要泛型)?
首先,我们看下下面这段简短的代码:
1 public class GenericTest {
2
3 public static void main(String[] args) {
4 List list = new ArrayList();
5 list.add("qqyumidi");
6 list.add("corn");
7 list.add(100);
8
9 for (int i = 0; i < list.size(); i++) {
10 String name = (String) list.get(i); // 1
11 System.out.println("name:" + name);
12 }
13 }
14 }
定义了一个List类型的集合,先向其中加入了两个字符串类型的值,随后加入一个Integer类型的值。这是完全允许的,因为此时list默认的类型为Object类型。在之后的循环中,由于忘记了之前在list中也加入了Integer类型的值或其他编码原因,很容易出现类似于//1中的错误。因为编译阶段正常,而运行时会出现“java.lang.ClassCastException”异常。因此,导致此类错误编码过程中不易发现。
在如上的编码过程中,我们发现主要存在两个问题:
1.当我们将一个对象放入集合中,集合不会记住此对象的类型,当再次从集合中取出此对象时,改对象的编译类型变成了Object类型,但其运行时类型任然为其本身类型。
2.因此,//1处取出集合元素时需要人为的强制类型转化到具体的目标类型,且很容易出现“java.lang.ClassCastException”异常。
那么有没有什么办法可以使集合能够记住集合内元素各类型,且能够达到只要编译时不出现问题,运行时就不会出现“java.lang.ClassCastException”异常呢?答案就是使用泛型。
二.什么是泛型?
泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。
看着好像有点复杂,首先我们看下上面那个例子采用泛型的写法。
1 public class GenericTest {
2
3 public static void main(String[] args) {
4 /*
5 List list = new ArrayList();
6 list.add("qqyumidi");
7 list.add("corn");
8 list.add(100);
9 */
10
11 List<String> list = new ArrayList<String>();
12 list.add("qqyumidi");
13 list.add("corn");
14 //list.add(100); // 1 提示编译错误
15
16 for (int i = 0; i < list.size(); i++) {
17 String name = list.get(i); // 2
18 System.out.println("name:" + name);
19 }
20 }
21 }
采用泛型写法后,在//1处想加入一个Integer类型的对象时会出现编译错误,通过List<String>,直接限定了list集合中只能含有String类型的元素,从而在//2处无须进行强制类型转换,因为此时,集合能够记住元素的类型信息,编译器已经能够确认它是String类型了。
结合上面的泛型定义,我们知道在List<String>中,String是类型实参,也就是说,相应的List接口中肯定含有类型形参。且get()方法的返回结果也直接是此形参类型(也就是对应的传入的类型实参)。下面就来看看List接口的的具体定义:
1 public interface List<E> extends Collection<E> {
2
3 int size();
4
5 boolean isEmpty();
6
7 boolean contains(Object o);
8
9 Iterator<E> iterator();
10
11 Object[] toArray();
12
13 <T> T[] toArray(T[] a);
14
15 boolean add(E e);
16
17 boolean remove(Object o);
18
19 boolean containsAll(Collection<?> c);
20
21 boolean addAll(Collection<? extends E> c);
22
23 boolean addAll(int index, Collection<? extends E> c);
24
25 boolean removeAll(Collection<?> c);
26
27 boolean retainAll(Collection<?> c);
28
29 void clear();
30
31 boolean equals(Object o);
32
33 int hashCode();
34
35 E get(int index);
36
37 E set(int index, E element);
38
39 void add(int index, E element);
40
41 E remove(int index);
42
43 int indexOf(Object o);
44
45 int lastIndexOf(Object o);
46
47 ListIterator<E> listIterator();
48
49 ListIterator<E> listIterator(int index);
50
51 List<E> subList(int fromIndex, int toIndex);
52 }
我们可以看到,在List接口中采用泛型化定义之后,<E>中的E表示类型形参,可以接收具体的类型实参,并且此接口定义中,凡是出现E的地方均表示相同的接受自外部的类型实参。
自然的,ArrayList作为List接口的实现类,其定义形式是:
1 public class ArrayList<E> extends AbstractList<E>
2 implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
3
4 public boolean add(E e) {
5 ensureCapacityInternal(size + 1); // Increments modCount!!
6 elementData[size++] = e;
7 return true;
8 }
9
10 public E get(int index) {
11 rangeCheck(index);
12 checkForComodification();
13 return ArrayList.this.elementData(offset + index);
14 }
15
16 //...省略掉其他具体的定义过程
17
18 }
由此,我们从源代码角度明白了为什么//1处加入Integer类型对象编译错误,且//2处get()到的类型直接就是String类型了。
三.自定义泛型接口、泛型类和泛型方法
从上面的内容中,大家已经明白了泛型的具体运作过程。也知道了接口、类和方法也都可以使用泛型去定义,以及相应的使用。是的,在具体使用时,可以分为泛型接口、泛型类和泛型方法。
自定义泛型接口、泛型类和泛型方法与上述Java源码中的List、ArrayList类似。如下,我们看一个最简单的泛型类和方法定义:
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box<String> name = new Box<String>("corn");
6 System.out.println("name:" + name.getData());
7 }
8
9 }
10
11 class Box<T> {
12
13 private T data;
14
15 public Box() {
16
17 }
18
19 public Box(T data) {
20 this.data = data;
21 }
22
23 public T getData() {
24 return data;
25 }
26
27 }
在泛型接口、泛型类和泛型方法的定义过程中,我们常见的如T、E、K、V等形式的参数常用于表示泛型形参,由于接收来自外部使用时候传入的类型实参。那么对于不同传入的类型实参,生成的相应对象实例的类型是不是一样的呢?
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box<String> name = new Box<String>("corn");
6 Box<Integer> age = new Box<Integer>(712);
7
8 System.out.println("name class:" + name.getClass()); // com.qqyumidi.Box
9 System.out.println("age class:" + age.getClass()); // com.qqyumidi.Box
10 System.out.println(name.getClass() == age.getClass()); // true
11
12 }
13
14 }
由此,我们发现,在使用泛型类时,虽然传入了不同的泛型实参,但并没有真正意义上生成不同的类型,传入不同泛型实参的泛型类在内存上只有一个,即还是原来的最基本的类型(本实例中为Box),当然,在逻辑上我们可以理解成多个不同的泛型类型。
究其原因,在于Java中的泛型这一概念提出的目的,导致其只是作用于代码编译阶段,在编译过程中,对于正确检验泛型结果后,会将泛型的相关信息擦出,也就是说,成功编译过后的class文件中是不包含任何泛型信息的。泛型信息不会进入到运行时阶段。
对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。
四.类型通配符
接着上面的结论,我们知道,Box<Number>和Box<Integer>实际上都是Box类型,现在需要继续探讨一个问题,那么在逻辑上,类似于Box<Number>和Box<Integer>是否可以看成具有父子关系的泛型类型呢?
为了弄清这个问题,我们继续看下下面这个例子:
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box<Number> name = new Box<Number>(99);
6 Box<Integer> age = new Box<Integer>(712);
7
8 getData(name);
9
10 //The method getData(Box<Number>) in the type GenericTest is
11 //not applicable for the arguments (Box<Integer>)
12 getData(age); // 1
13
14 }
15
16 public static void getData(Box<Number> data){
17 System.out.println("data :" + data.getData());
18 }
19
20 }
我们发现,在代码//1处出现了错误提示信息:The method getData(Box<Number>) in the t ype GenericTest is not applicable for the arguments (Box<Integer>)。显然,通过提示信息,我们知道Box<Number>在逻辑上不能视为Box<Integer>的父类。那么,原因何在呢?
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box<Integer> a = new Box<Integer>(712);
6 Box<Number> b = a; // 1
7 Box<Float> f = new Box<Float>(3.14f);
8 b.setData(f); // 2
9
10 }
11
12 public static void getData(Box<Number> data) {
13 System.out.println("data :" + data.getData());
14 }
15
16 }
17
18 class Box<T> {
19
20 private T data;
21
22 public Box() {
23
24 }
25
26 public Box(T data) {
27 setData(data);
28 }
29
30 public T getData() {
31 return data;
32 }
33
34 public void setData(T data) {
35 this.data = data;
36 }
37
38 }
这个例子中,显然//1和//2处肯定会出现错误提示的。在此我们可以使用反证法来进行说明。
假设Box<Number>在逻辑上可以视为Box<Integer>的父类,那么//1和//2处将不会有错误提示了,那么问题就出来了,通过getData()方法取出数据时到底是什么类型呢?Integer? Float? 还是Number?且由于在编程过程中的顺序不可控性,导致在必要的时候必须要进行类型判断,且进行强制类型转换。显然,这与泛型的理念矛盾,因此,在逻辑上Box<Number>不能视为Box<Integer>的父类。
好,那我们回过头来继续看“类型通配符”中的第一个例子,我们知道其具体的错误提示的深层次原因了。那么如何解决呢?总部能再定义一个新的函数吧。这和Java中的多态理念显然是违背的,因此,我们需要一个在逻辑上可以用来表示同时是Box<Integer>和Box<Number>的父类的一个引用类型,由此,类型通配符应运而生。
类型通配符一般是使用 ? 代替具体的类型实参。注意了,此处是类型实参,而不是类型形参!且Box<?>在逻辑上是Box<Integer>、Box<Number>...等所有Box<具体类型实参>的父类。由此,我们依然可以定义泛型方法,来完成此类需求。
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box<String> name = new Box<String>("corn");
6 Box<Integer> age = new Box<Integer>(712);
7 Box<Number> number = new Box<Number>(314);
8
9 getData(name);
10 getData(age);
11 getData(number);
12 }
13
14 public static void getData(Box<?> data) {
15 System.out.println("data :" + data.getData());
16 }
17
18 }
有时候,我们还可能听到类型通配符上限和类型通配符下限。具体有是怎么样的呢?
在上面的例子中,如果需要定义一个功能类似于getData()的方法,但对类型实参又有进一步的限制:只能是Number类及其子类。此时,需要用到类型通配符上限。
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box<String> name = new Box<String>("corn");
6 Box<Integer> age = new Box<Integer>(712);
7 Box<Number> number = new Box<Number>(314);
8
9 getData(name);
10 getData(age);
11 getData(number);
12
13 //getUpperNumberData(name); // 1
14 getUpperNumberData(age); // 2
15 getUpperNumberData(number); // 3
16 }
17
18 public static void getData(Box<?> data) {
19 System.out.println("data :" + data.getData());
20 }
21
22 public static void getUpperNumberData(Box<? extends Number> data){
23 System.out.println("data :" + data.getData());
24 }
25
26 }
此时,显然,在代码//1处调用将出现错误提示,而//2 //3处调用正常。
类型通配符上限通过形如Box<? extends Number>形式定义,相对应的,类型通配符下限为Box<? super Number>形式,其含义与类型通配符上限正好相反,在此不作过多阐述了。
五.话外篇
本文中的例子主要是为了阐述泛型中的一些思想而简单举出的,并不一定有着实际的可用性。另外,一提到泛型,相信大家用到最多的就是在集合中,其实,在实际的编程过程中,自己可以使用泛型去简化开发,且能很好的保证代码质量。并且还要注意的一点是,Java中没有所谓的泛型数组一说。
对于泛型,最主要的还是需要理解其背后的思想和目的。
33. 解析XML的几种方式的原理与特点:DOM、SAX、PULL。
在android开发中,经常用到去解析xml文件,常见的解析xml的方式有一下三种:SAX、Pull、Dom解析方式。最近做了一个android版的CSDN阅读器,用到了其中的两种(sax,pull),今天对android解析xml的这三种方式进行一次总结。
今天解析的xml示例(channels.xml)如下:
<?xml version="1.0" encoding="utf-8"?>
<channel>
<item id="0" url="http://www.baidu.com">百度</item>
<item id="1" url="http://www.qq.com">腾讯</item>
<item id="2" url="http://www.sina.com.cn">新浪</item>
<item id="3" url="http://www.taobao.com">淘宝</item>
</channel>
一、使用sax方式解析
基础知识:
这种方式解析是一种基于事件驱动的api,有两个部分,解析器和事件处理器,解析器就是XMLReader接口,负责读取XML文档,和向事件处理器发送事件(也是事件源),事件处理器ContentHandler接口,负责对发送的事件响应和进行XML文档处理。
下面是ContentHandler接口的常用方法
public abstract void characters (char[] ch, int start, int length)
这个方法来接收字符块通知,解析器通过这个方法来报告字符数据块,解析器为了提高解析效率把读到的所有字符串放到一个字符数组(ch)中,作为参数传递给character的方法中,如果想获取本次事件中读取到的字符数据,需要使用start和length属性。
public abstract void startDocument () 接收文档开始的通知
public abstract void endDocument () 接收文档结束的通知
public abstract void startElement (String uri, String localName, String qName, Attributes atts) 接收文档开始的标签
public abstract void endElement (String uri, String localName, String qName) 接收文档结束的标签
在一般使用中为了简化开发,在org.xml.sax.helpers提供了一个DefaultHandler类,它实现了ContentHandler的方法,我们只想继承DefaultHandler方法即可。
另外SAX解析器提供了一个工厂类:SAXParserFactory,SAX的解析类为SAXParser 可以调用它的parser方法进行解析。
看了些基础以后开始上代码吧(核心代码,下载代码在附件)
1 public class SAXPraserHelper extends DefaultHandler {
2
3 final int ITEM = 0x0005;
4
5 List<channel> list;
6 channel chann;
7 int currentState = 0;
8
9 public List<channel> getList() {
10 return list;
11 }
12
13 /*
14 * 接口字符块通知
15 */
16 @Override
17 public void characters(char[] ch, int start, int length)
18 throws SAXException {
19 // TODO Auto-generated method stub
20 // super.characters(ch, start, length);
21 String theString = String.valueOf(ch, start, length);
22 if (currentState != 0) {
23 chann.setName(theString);
24 currentState = 0;
25 }
26 return;
27 }
28
29 /*
30 * 接收文档结束通知
31 */
32 @Override
33 public void endDocument() throws SAXException {
34 // TODO Auto-generated method stub
35 super.endDocument();
36 }
37
38 /*
39 * 接收标签结束通知
40 */
41 @Override
42 public void endElement(String uri, String localName, String qName)
43 throws SAXException {
44 // TODO Auto-generated method stub
45 if (localName.equals("item"))
46 list.add(chann);
47 }
48
49 /*
50 * 文档开始通知
51 */
52 @Override
53 public void startDocument() throws SAXException {
54 // TODO Auto-generated method stub
55 list = new ArrayList<channel>();
56 }
57
58 /*
59 * 标签开始通知
60 */
61 @Override
62 public void startElement(String uri, String localName, String qName,
63 Attributes attributes) throws SAXException {
64 // TODO Auto-generated method stub
65 chann = new channel();
66 if (localName.equals("item")) {
67 for (int i = 0; i < attributes.getLength(); i++) {
68 if (attributes.getLocalName(i).equals("id")) {
69 chann.setId(attributes.getValue(i));
70 } else if (attributes.getLocalName(i).equals("url")) {
71 chann.setUrl(attributes.getValue(i));
72 }
73 }
74 currentState = ITEM;
75 return;
76 }
77 currentState = 0;
78 return;
79 }
80 }
1 private List<channel> getChannelList() throws ParserConfigurationException, SAXException, IOException
2 {
3 //实例化一个SAXParserFactory对象
4 SAXParserFactory factory=SAXParserFactory.newInstance();
5 SAXParser parser;
6 //实例化SAXParser对象,创建XMLReader对象,解析器
7 parser=factory.newSAXParser();
8 XMLReader xmlReader=parser.getXMLReader();
9 //实例化handler,事件处理器
10 SAXPraserHelper helperHandler=new SAXPraserHelper();
11 //解析器注册事件
12 xmlReader.setContentHandler(helperHandler);
13 //读取文件流
14 InputStream stream=getResources().openRawResource(R.raw.channels);
15 InputSource is=new InputSource(stream);
16 //解析文件
17 xmlReader.parse(is);
18 return helperHandler.getList();
19 }
从第二部分代码,可以看出使用SAX解析XML的步骤:
1、实例化一个工厂SAXParserFactory
2、实例化SAXPraser对象,创建XMLReader 解析器
3、实例化handler,处理器
4、解析器注册一个事件
4、读取文件流
5、解析文件
二、使用pull方式解析
基础知识:
在android系统中,很多资源文件中,很多都是xml格式,在android系统中解析这些xml的方式,是使用pul解析器进行解析的,它和sax解析一样(个人感觉要比sax简单点),也是采用事件驱动进行解析的,当pull解析器,开始解析之后,我们可以调用它的next()方法,来获取下一个解析事件(就是开始文档,结束文档,开始标签,结束标签),当处于某个元素时可以调用XmlPullParser的getAttributte()方法来获取属性的值,也可调用它的nextText()获取本节点的值。
其实以上描述,就是对整个解析步骤的一个描述,看看代码吧
1 private List<Map<String, String>> getData() {
2 List<Map<String, String>> list = new ArrayList<Map<String, String>>();
3 XmlResourceParser xrp = getResources().getXml(R.xml.channels);
4
5 try {
6 // 直到文档的结尾处
7 while (xrp.getEventType() != XmlResourceParser.END_DOCUMENT) {
8 // 如果遇到了开始标签
9 if (xrp.getEventType() == XmlResourceParser.START_TAG) {
10 String tagName = xrp.getName();// 获取标签的名字
11 if (tagName.equals("item")) {
12 Map<String, String> map = new HashMap<String, String>();
13 String id = xrp.getAttributeValue(null, "id");// 通过属性名来获取属性值
14 map.put("id", id);
15 String url = xrp.getAttributeValue(1);// 通过属性索引来获取属性值
16 map.put("url", url);
17 map.put("name", xrp.nextText());
18 list.add(map);
19 }
20 }
21 xrp.next();// 获取解析下一个事件
22 }
23 } catch (XmlPullParserException e) {
24 // TODO Auto-generated catch block
25 e.printStackTrace();
26 } catch (IOException e) {
27 // TODO Auto-generated catch block
28 e.printStackTrace();
29 }
30
31 return list;
32 }
三、使用Dom方式解析
基础知识:
最后来看看Dom解析方式,这种方式解析自己之前也没有用过(在j2ee开发中比较常见,没有做过这方面的东西),在Dom解析的过程中,是先把dom全部文件读入到内存中,然后使用dom的api遍历所有数据,检索想要的数据,这种方式显然是一种比较消耗内存的方式,对于像手机这样的移动设备来讲,内存是非常有限的,所以对于比较大的XML文件,不推荐使用这种方式,但是Dom也有它的优点,它比较直观,在一些方面比SAX方式比较简单。在xml文档比较小的情况下也可以考虑使用dom方式。
Dom方式解析的核心代码如下:
1 public static List<channel> getChannelList(InputStream stream)
2 {
3 List<channel> list=new ArrayList<channel>();
4
5 //得到 DocumentBuilderFactory 对象, 由该对象可以得到 DocumentBuilder 对象
6 DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
7
8 try {
9 //得到DocumentBuilder对象
10 DocumentBuilder builder=factory.newDocumentBuilder();
11 //得到代表整个xml的Document对象
12 Document document=builder.parse(stream);
13 //得到 "根节点"
14 Element root=document.getDocumentElement();
15 //获取根节点的所有items的节点
16 NodeList items=root.getElementsByTagName("item");
17 //遍历所有节点
18 for(int i=0;i<items.getLength();i++)
19 {
20 channel chann=new channel();
21 Element item=(Element)items.item(i);
22 chann.setId(item.getAttribute("id"));
23 chann.setUrl(item.getAttribute("url"));
24 chann.setName(item.getFirstChild().getNodeValue());
25 list.add(chann);
26 }
27
28 } catch (ParserConfigurationException e) {
29 // TODO Auto-generated catch block
30 e.printStackTrace();
31 } catch (SAXException e) {
32 // TODO Auto-generated catch block
33 e.printStackTrace();
34 } catch (IOException e) {
35 // TODO Auto-generated catch block
36 e.printStackTrace();
37 }
38
39 return list;
40 }
总结一下Dom解析的步骤(和sax类似)
1、调用 DocumentBuilderFactory.newInstance() 方法得到 DOM 解析器工厂类实例。
2、调用解析器工厂实例类的 newDocumentBuilder() 方法得到 DOM 解析器对象
3、调用 DOM 解析器对象的 parse() 方法解析 XML 文档得到代表整个文档的 Document 对象。
四、总结
除以上三种外还有很多解析xml的方法,比如DOM4J、JDOM等等。但其基本的解析方式包含两种,一种是事件驱动的(代表SAX),另一种方式是基于文档结构(代表DOM)。其他的只不过语法不一样而已。
附(本文示例运行截屏):


34. Java与C++对比。
(1) 最大的障碍在于速度:解释过的Java要比C的执行速度慢上约20倍。无论什么都不能阻止Java语言进行编译。写作本书的时候,刚刚出现了一些准实时编译器,它们能显著加快速度。当然,我们完全有理由认为会出现适用于更多流行平台的纯固有编译器,但假若没有那些编译器,由于速度的限制,必须有些问题是Java不能解决的。
(2) 和C++一样,Java也提供了两种类型的注释。
(3) 所有东西都必须置入一个类。不存在全局函数或者全局数据。如果想获得与全局函数等价的功能,可考虑将static方法和static数据置入一个类里。注意没有象结构、枚举或者联合这一类的东西,一切只有“类”(Class)!
(4) 所有方法都是在类的主体定义的。所以用C++的眼光看,似乎所有函数都已嵌入,但实情并非如何(嵌入的问题在后面讲述)。
(5) 在Java中,类定义采取几乎和C++一样的形式。但没有标志结束的分号。没有class foo这种形式的类声明,只有类定义。
class aType()
void aMethod() {/* 方法主体 */}
}
(6) Java中没有作用域范围运算符“::”。Java利用点号做所有的事情,但可以不用考虑它,因为只能在一个类里定义元素。即使那些方法定义,也必须在一个类的内部,所以根本没有必要指定作用域的范围。我们注意到的一项差异是对static方法的调用:使用ClassName.methodName()。除此以外,package(包)的名字是用点号建立的,并能用import关键字实现C++的“#include”的一部分功能。例如下面这个语句:
import java.awt.*;
(#include并不直接映射成import,但在使用时有类似的感觉。)
(7) 与C++类似,Java含有一系列“主类型”(Primitive type),以实现更有效率的访问。在Java中,这些类型包括boolean,char,byte,short,int,long,float以及double。所有主类型的大小都是固有的,且与具体的机器无关(考虑到移植的问题)。这肯定会对性能造成一定的影响,具体取决于不同的机器。对类型的检查和要求在Java里变得更苛刻。例如:
■条件表达式只能是boolean(布尔)类型,不可使用整数。
■必须使用象X+Y这样的一个表达式的结果;不能仅仅用“X+Y”来实现“副作用”。
(8) char(字符)类型使用国际通用的16位Unicode字符集,所以能自动表达大多数国家的字符。
(9) 静态引用的字串会自动转换成String对象。和C及C++不同,没有独立的静态字符数组字串可供使用。
(10) Java增添了三个右移位运算符“>>>”,具有与“逻辑”右移位运算符类似的功用,可在最末尾插入零值。“>>”则会在移位的同时插入符号位(即“算术”移位)。
(11) 尽管表面上类似,但与C++相比,Java数组采用的是一个颇为不同的结构,并具有独特的行为。有一个只读的length成员,通过它可知道数组有多大。而且一旦超过数组边界,运行期检查会自动丢弃一个异常。所有数组都是在内存“堆”里创建的,我们可将一个数组分配给另一个(只是简单地复制数组句柄)。数组标识符属于第一级对象,它的所有方法通常都适用于其他所有对象。
(12) 对于所有不属于主类型的对象,都只能通过new命令创建。和C++不同,Java没有相应的命令可以“在堆栈上”创建不属于主类型的对象。所有主类型都只能在堆栈上创建,同时不使用new命令。所有主要的类都有自己的“封装(器)”类,所以能够通过new创建等价的、以内存“堆”为基础的对象(主类型数组是一个例外:它们可象C++那样通过集合初始化进行分配,或者使用new)。
(13) Java中不必进行提前声明。若想在定义前使用一个类或方法,只需直接使用它即可——编译器会保证使用恰当的定义。所以和在C++中不同,我们不会碰到任何涉及提前引用的问题。
(14) Java没有预处理机。若想使用另一个库里的类,只需使用import命令,并指定库名即可。不存在类似于预处理机的宏。
(15) Java用包代替了命名空间。由于将所有东西都置入一个类,而且由于采用了一种名为“封装”的机制,它能针对类名进行类似于命名空间分解的操作,所以命名的问题不再进入我们的考虑之列。数据包也会在单独一个库名下收集库的组件。我们只需简单地“import”(导入)一个包,剩下的工作会由编译器自动完成。
(16) 被定义成类成员的对象句柄会自动初始化成null。对基本类数据成员的初始化在Java里得到了可靠的保障。若不明确地进行初始化,它们就会得到一个默认值(零或等价的值)。可对它们进行明确的初始化(显式初始化):要么在类内定义它们,要么在构建器中定义。采用的语法比C++的语法更容易理解,而且对于static和非static成员来说都是固定不变的。我们不必从外部定义static成员的存储方式,这和C++是不同的。
(17) 在Java里,没有象C和C++那样的指针。用new创建一个对象的时候,会获得一个引用(本书一直将其称作“句柄”)。例如:
String s = new String("howdy");
然而,C++引用在创建时必须进行初始化,而且不可重定义到一个不同的位置。但Java引用并不一定局限于创建时的位置。它们可根据情况任意定义,这便消除了对指针的部分需求。在C和C++里大量采用指针的另一个原因是为了能指向任意一个内存位置(这同时会使它们变得不安全,也是Java不提供这一支持的原因)。指针通常被看作在基本变量数组中四处移动的一种有效手段。Java允许我们以更安全的形式达到相同的目标。解决指针问题的终极方法是“固有方法”(已在附录A讨论)。将指针传递给方法时,通常不会带来太大的问题,因为此时没有全局函数,只有类。而且我们可传递对对象的引用。Java语言最开始声称自己“完全不采用指针!”但随着许多程序员都质问没有指针如何工作?于是后来又声明“采用受到限制的指针”。大家可自行判断它是否“真”的是一个指针。但不管在何种情况下,都不存在指针“算术”。
(18) Java提供了与C++类似的“构建器”(Constructor)。如果不自己定义一个,就会获得一个默认构建器。而如果定义了一个非默认的构建器,就不会为我们自动定义默认构建器。这和C++是一样的。注意没有复制构建器,因为所有自变量都是按引用传递的。
(19) Java中没有“破坏器”(Destructor)。变量不存在“作用域”的问题。一个对象的“存在时间”是由对象的存在时间决定的,并非由垃圾收集器决定。有个finalize()方法是每一个类的成员,它在某种程度上类似于C++的“破坏器”。但finalize()是由垃圾收集器调用的,而且只负责释放“资源”(如打开的文件、套接字、端口、URL等等)。如需在一个特定的地点做某样事情,必须创建一个特殊的方法,并调用它,不能依赖finalize()。而在另一方面,C++中的所有对象都会(或者说“应该”)破坏,但并非Java中的所有对象都会被当作“垃圾”收集掉。由于Java不支持破坏器的概念,所以在必要的时候,必须谨慎地创建一个清除方法。而且针对类内的基础类以及成员对象,需要明确调用所有清除方法。
(20) Java具有方法“过载”机制,它的工作原理与C++函数的过载几乎是完全相同的。
(21) Java不支持默认自变量。
(22) Java中没有goto。它采取的无条件跳转机制是“break 标签”或者“continue 标准”,用于跳出当前的多重嵌套循环。
(23) Java采用了一种单根式的分级结构,因此所有对象都是从根类Object统一继承的。而在C++中,我们可在任何地方启动一个新的继承树,所以最后往往看到包含了大量树的“一片森林”。在Java中,我们无论如何都只有一个分级结构。尽管这表面上看似乎造成了限制,但由于我们知道每个对象肯定至少有一个Object接口,所以往往能获得更强大的能力。C++目前似乎是唯一没有强制单根结构的唯一一种OO语言。
(24) Java没有模板或者参数化类型的其他形式。它提供了一系列集合:Vector(向量),Stack(堆栈)以及Hashtable(散列表),用于容纳Object引用。利用这些集合,我们的一系列要求可得到满足。但这些集合并非是为实现象C++“标准模板库”(STL)那样的快速调用而设计的。Java 1.2中的新集合显得更加完整,但仍不具备正宗模板那样的高效率使用手段。
(25) “垃圾收集”意味着在Java中出现内存漏洞的情况会少得多,但也并非完全不可能(若调用一个用于分配存储空间的固有方法,垃圾收集器就不能对其进行跟踪监视)。然而,内存漏洞和资源漏洞多是由于编写不当的finalize()造成的,或是由于在已分配的一个块尾释放一种资源造成的(“破坏器”在此时显得特别方便)。垃圾收集器是在C++基础上的一种极大进步,使许多编程问题消弥于无形之中。但对少数几个垃圾收集器力有不逮的问题,它却是不大适合的。但垃圾收集器的大量优点也使这一处缺点显得微不足道。
(26) Java内建了对多线程的支持。利用一个特殊的Thread类,我们可通过继承创建一个新线程(放弃了run()方法)。若将synchronized(同步)关键字作为方法的一个类型限制符使用,相互排斥现象会在对象这一级发生。在任何给定的时间,只有一个线程能使用一个对象的synchronized方法。在另一方面,一个synchronized方法进入以后,它首先会“锁定”对象,防止其他任何synchronized方法再使用那个对象。只有退出了这个方法,才会将对象“解锁”。在线程之间,我们仍然要负责实现更复杂的同步机制,方法是创建自己的“监视器”类。递归的synchronized方法可以正常运作。若线程的优先等级相同,则时间的“分片”不能得到保证。
(27) 我们不是象C++那样控制声明代码块,而是将访问限定符(public,private和protected)置入每个类成员的定义里。若未规定一个“显式”(明确的)限定符,就会默认为“友好的”(friendly)。这意味着同一个包里的其他元素也可以访问它(相当于它们都成为C++的“friends”——朋友),但不可由包外的任何元素访问。类——以及类内的每个方法——都有一个访问限定符,决定它是否能在文件的外部“可见”。private关键字通常很少在Java中使用,因为与排斥同一个包内其他类的访问相比,“友好的”访问通常更加有用。然而,在多线程的环境中,对private的恰当运用是非常重要的。Java的protected关键字意味着“可由继承者访问,亦可由包内其他元素访问”。注意Java没有与C++的protected关键字等价的元素,后者意味着“只能由继承者访问”(以前可用“private protected”实现这个目的,但这一对关键字的组合已被取消了)。
(28) 嵌套的类。在C++中,对类进行嵌套有助于隐藏名称,并便于代码的组织(但C++的“命名空间”已使名称的隐藏显得多余)。Java的“封装”或“打包”概念等价于C++的命名空间,所以不再是一个问题。Java 1.1引入了“内部类”的概念,它秘密保持指向外部类的一个句柄——创建内部类对象的时候需要用到。这意味着内部类对象也许能访问外部类对象的成员,毋需任何条件——就好象那些成员直接隶属于内部类对象一样。这样便为回调问题提供了一个更优秀的方案——C++是用指向成员的指针解决的。
(29) 由于存在前面介绍的那种内部类,所以Java里没有指向成员的指针。
(30) Java不存在“嵌入”(inline)方法。Java编译器也许会自行决定嵌入一个方法,但我们对此没有更多的控制权力。在Java中,可为一个方法使用final关键字,从而“建议”进行嵌入操作。然而,嵌入函数对于C++的编译器来说也只是一种建议。
(31) Java中的继承具有与C++相同的效果,但采用的语法不同。Java用extends关键字标志从一个基础类的继承,并用super关键字指出准备在基础类中调用的方法,它与我们当前所在的方法具有相同的名字(然而,Java中的super关键字只允许我们访问父类的方法——亦即分级结构的上一级)。通过在C++中设定基础类的作用域,我们可访问位于分级结构较深处的方法。亦可用super关键字调用基础类构建器。正如早先指出的那样,所有类最终都会从Object里自动继承。和C++不同,不存在明确的构建器初始化列表。但编译器会强迫我们在构建器主体的开头进行全部的基础类初始化,而且不允许我们在主体的后面部分进行这一工作。通过组合运用自动初始化以及来自未初始化对象句柄的异常,成员的初始化可得到有效的保证。
public class Foo extends Bar {
public Foo(String msg) {
super(msg); // Calls base constructor
}
public baz(int i) { // Override
super.baz(i); // Calls base method
}
}
(32) Java中的继承不会改变基础类成员的保护级别。我们不能在Java中指定public,private或者protected继承,这一点与C++是相同的。此外,在衍生类中的优先方法不能减少对基础类方法的访问。例如,假设一个成员在基础类中属于public,而我们用另一个方法代替了它,那么用于替换的方法也必须属于public(编译器会自动检查)。
(33) Java提供了一个interface关键字,它的作用是创建抽象基础类的一个等价物。在其中填充抽象方法,且没有数据成员。这样一来,对于仅仅设计成一个接口的东西,以及对于用extends关键字在现有功能基础上的扩展,两者之间便产生了一个明显的差异。不值得用abstract关键字产生一种类似的效果,因为我们不能创建属于那个类的一个对象。一个abstract(抽象)类可包含抽象方法(尽管并不要求在它里面包含什么东西),但它也能包含用于具体实现的代码。因此,它被限制成一个单一的继承。通过与接口联合使用,这一方案避免了对类似于C++虚拟基础类那样的一些机制的需要。
为创建可进行“例示”(即创建一个实例)的一个interface(接口)的版本,需使用implements关键字。它的语法类似于继承的语法,如下所示:
public interface Face {
public void smile();
}
public class Baz extends Bar implements Face {
public void smile( ) {
System.out.println("a warm smile");
}
}
(34) Java中没有virtual关键字,因为所有非static方法都肯定会用到动态绑定。在Java中,程序员不必自行决定是否使用动态绑定。C++之所以采用了virtual,是由于我们对性能进行调整的时候,可通过将其省略,从而获得执行效率的少量提升(或者换句话说:“如果不用,就没必要为它付出代价”)。virtual经常会造成一定程度的混淆,而且获得令人不快的结果。final关键字为性能的调整规定了一些范围——它向编译器指出这种方法不能被取代,所以它的范围可能被静态约束(而且成为嵌入状态,所以使用C++非virtual调用的等价方式)。这些优化工作是由编译器完成的。
(35) Java不提供多重继承机制(MI),至少不象C++那样做。与protected类似,MI表面上是一个很不错的主意,但只有真正面对一个特定的设计问题时,才知道自己需要它。由于Java使用的是“单根”分级结构,所以只有在极少的场合才需要用到MI。interface关键字会帮助我们自动完成多个接口的合并工作。
(36) 运行期的类型标识功能与C++极为相似。例如,为获得与句柄X有关的信息,可使用下述代码:
X.getClass().getName();
为进行一个“类型安全”的紧缩造型,可使用:
derived d = (derived)base;
这与旧式风格的C造型是一样的。编译器会自动调用动态造型机制,不要求使用额外的语法。尽管它并不象C++的“new casts”那样具有易于定位造型的优点,但Java会检查使用情况,并丢弃那些“异常”,所以它不会象C++那样允许坏造型的存在。
(37) Java采取了不同的异常控制机制,因为此时已经不存在构建器。可添加一个finally从句,强制执行特定的语句,以便进行必要的清除工作。Java中的所有异常都是从基础类Throwable里继承而来的,所以可确保我们得到的是一个通用接口。
public void f(Obj b) throws IOException {
myresource mr = b.createResource();
try {
mr.UseResource();
} catch (MyException e) {
// handle my exception
} catch (Throwable e) {
// handle all other exceptions
} finally {
mr.dispose(); // special cleanup
}
}
(38) Java的异常规范比C++的出色得多。丢弃一个错误的异常后,不是象C++那样在运行期间调用一个函数,Java异常规范是在编译期间检查并执行的。除此以外,被取代的方法必须遵守那一方法的基础类版本的异常规范:它们可丢弃指定的异常或者从那些异常衍生出来的其他异常。这样一来,我们最终得到的是更为“健壮”的异常控制代码。
(39) Java具有方法过载的能力,但不允许运算符过载。String类不能用+和+=运算符连接不同的字串,而且String表达式使用自动的类型转换,但那是一种特殊的内建情况。
(40) 通过事先的约定,C++中经常出现的const问题在Java里已得到了控制。我们只能传递指向对象的句柄,本地副本永远不会为我们自动生成。若希望使用类似C++按值传递那样的技术,可调用clone(),生成自变量的一个本地副本(尽管clone()的设计依然尚显粗糙——参见第12章)。根本不存在被自动调用的副本构建器。为创建一个编译期的常数值,可象下面这样编码:
static final int SIZE = 255
static final int BSIZE = 8 * SIZE
(41) 由于安全方面的原因,“应用程序”的编程与“程序片”的编程之间存在着显著的差异。一个最明显的问题是程序片不允许我们进行磁盘的写操作,因为这样做会造成从远程站点下载的、不明来历的程序可能胡乱改写我们的磁盘。随着Java 1.1对数字签名技术的引用,这一情况已有所改观。根据数字签名,我们可确切知道一个程序片的全部作者,并验证他们是否已获得授权。Java 1.2会进一步增强程序片的能力。
(42) 由于Java在某些场合可能显得限制太多,所以有时不愿用它执行象直接访问硬件这样的重要任务。Java解决这个问题的方案是“固有方法”,允许我们调用由其他语言写成的函数(目前只支持C和C++)。这样一来,我们就肯定能够解决与平台有关的问题(采用一种不可移植的形式,但那些代码随后会被隔离起来)。程序片不能调用固有方法,只有应用程序才可以。
(43) Java提供对注释文档的内建支持,所以源码文件也可以包含它们自己的文档。通过一个单独的程序,这些文档信息可以提取出来,并重新格式化成HTML。这无疑是文档管理及应用的极大进步。
(44) Java包含了一些标准库,用于完成特定的任务。C++则依靠一些非标准的、由其他厂商提供的库。这些任务包括(或不久就要包括):
■连网
■数据库连接(通过JDBC)
■多线程
■分布式对象(通过RMI和CORBA)
■压缩
■商贸
由于这些库简单易用,而且非常标准,所以能极大加快应用程序的开发速度。
(45) Java 1.1包含了Java Beans标准,后者可创建在可视编程环境中使用的组件。由于遵守同样的标准,所以可视组件能够在所有厂商的开发环境中使用。由于我们并不依赖一家厂商的方案进行可视组件的设计,所以组件的选择余地会加大,并可提高组件的效能。除此之外,Java Beans的设计非常简单,便于程序员理解;而那些由不同的厂商开发的专用组件框架则要求进行更深入的学习。
(46) 若访问Java句柄失败,就会丢弃一次异常。这种丢弃测试并不一定要正好在使用一个句柄之前进行。根据Java的设计规范,只是说异常必须以某种形式丢弃。许多C++运行期系统也能丢弃那些由于指针错误造成的异常。
(47) Java通常显得更为健壮,为此采取的手段如下:
■对象句柄初始化成null(一个关键字)
■句柄肯定会得到检查,并在出错时丢弃异常
■所有数组访问都会得到检查,及时发现边界违例情况
■自动垃圾收集,防止出现内存漏洞
■明确、“傻瓜式”的异常控制机制
■为多线程提供了简单的语言支持
■对网络程序片进行字节码校验
1.jdk7语法上
1.1二进制变量的表示,支持将整数类型用二进制来表示,用0b开头。
1.2 Switch语句支持string类型
1.3 Try-with-resource语句
注意:实现java.lang.AutoCloseable接口的资源都可以放到try中,跟final里面的关闭资源类似; 按照声明逆序关闭资源 ;Try块抛出的异常通过Throwable.getSuppressed获取
1.4 Catch多个异常 说明:Catch异常类型为final; 生成Bytecode 会比多个catch小; Rethrow时保持异常类型
1.5 数字类型的下划线表示 更友好的表示方式,不过要注意下划线添加的一些标准
1.6 泛型实例的创建可以通过类型推断来简化 可以去掉后面new部分的泛型类型,只用<>就可以了
1.7在可变参数方法中传递非具体化参数,改进编译警告和错误
1.8 信息更丰富的回溯追踪 就是上面try中try语句和里面的语句同时抛出异常时,异常栈的信息
2. NIO2的一些新特性
1.java.nio.file 和java.nio.file.attribute包 支持更详细属性,比如权限,所有者
2. symbolic and hard links支持
3. Path访问文件系统,Files支持各种文件操作
4.高效的访问metadata信息
5.递归查找文件树,文件扩展搜索
6.文件系统修改通知机制
7.File类操作API兼容
8.文件随机访问增强 mapping a region,locl a region,绝对位置读取
9. AIO Reactor(基于事件)和Proactor
2.1IO and New IO 监听文件系统变化通知
通过FileSystems.getDefault().newWatchService()获取watchService,然后将需要监听的path目录注册到这个watchservice中,对于这个目录的文件修改,新增,删除等实践可以配置,然后就自动能监听到响应的事件。
2.2 IO and New IO遍历文件树 ,通过继承SimpleFileVisitor类,实现事件遍历目录树的操作,然后通过Files.walkFileTree(listDir, opts, Integer.MAX_VALUE, walk);这个API来遍历目录树
2.3 AIO异步IO 文件和网络 异步IO在java
NIO2实现了,都是用AsynchronousFileChannel,AsynchronousSocketChanne等实现,关于同步阻塞IO,同步非阻塞IO,异步阻塞IO和异步非阻塞IO。Java NIO2中就实现了操作系统的异步非阻塞IO。
3. JDBC 4.1
3.1.可以使用try-with-resources自动关闭Connection, ResultSet, 和 Statement资源对象
3.2. RowSet 1.1:引入RowSetFactory接口和RowSetProvider类,可以创建JDBC driver支持的各种 row sets,这里的rowset实现其实就是将sql语句上的一些操作转为方法的操作,封装了一些功能。
3.3. JDBC-ODBC驱动会在jdk8中删除
4. 并发工具增强
4.1.fork-join
最大的增强,充分利用多核特性,将大问题分解成各个子问题,由多个cpu可以同时解决多个子问题,最后合并结果,继承RecursiveTask,实现compute方法,然后调用fork计算,最后用join合并结果。
4.2.ThreadLocalRandon 并发下随机数生成类,保证并发下的随机数生成的线程安全,实际上就是使用threadlocal
4.3. phaser 类似cyclebarrier和countdownlatch,不过可以动态添加资源减少资源
5. Networking增强
新增URLClassLoader close方法,可以及时关闭资源,后续重新加载class文件时不会导致资源被占用或者无法释放问题
URLClassLoader.newInstance(new URL[]{}).close();
新增Sockets Direct Protocol
绕过操作系统的数据拷贝,将数据从一台机器的内存数据通过网络直接传输到另外一台机器的内存中
6. Multithreaded Custom Class Loaders
解决并发下加载class可能导致的死锁问题,这个是jdk1.6的一些新版本就解决了,jdk7也做了一些优化。有兴趣可以仔细从官方文档详细了解
JDK1.8的新特性
一、接口的默认方法
Java 8允许我们给接口添加一个非抽象的方法实现,只需要使用 default关键字即可,这个特征又叫做扩展方法。
二、Lambda 表达式
在Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8提供了更简洁的语法,lambda表达式:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});
三、函数式接口
Lambda表达式是如何在java的类型系统中表示的呢?每一个lambda表达式都对应一个类型,通常是接口类型。而“函数式接口”是指仅仅只包含一个抽象方法的接口,每一个该类型的lambda表达式都会被匹配到这个抽象方法。因为 默认方法 不算抽象方法,所以你也可以给你的函数式接口添加默认方法。
四、方法与构造函数引用
Java 8 允许你使用 :: 关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法:
converter = something::startsWith;
String converted = converter.convert("Java");
System.out.println(converted);
五、Lambda 作用域
在lambda表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量。
六、访问局部变量
可以直接在lambda表达式中访问外层的局部变量:
七、访问对象字段与静态变量
和本地变量不同的是,lambda内部对于实例的字段以及静态变量是即可读又可写。该行为和匿名对象是一致的:
八、访问接口的默认方法
JDK 1.8 API包含了很多内建的函数式接口,在老Java中常用到的比如Comparator或者Runnable接口,这些接口都增加了@FunctionalInterface注解以便能用在lambda上。
Java 8 API同样还提供了很多全新的函数式接口来让工作更加方便,有一些接口是来自Google Guava库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
1.jdk7语法上
1.1二进制变量的表示,支持将整数类型用二进制来表示,用0b开头。
// 所有整数 int, short,long,byte都可以用二进制表示
// An 8-bit 'byte' value:
byte aByte = (byte) 0b00100001;
// A 16-bit 'short' value:
short aShort = (short) 0b1010000101000101;
// Some 32-bit 'int' values:
intanInt1 = 0b10100001010001011010000101000101;
intanInt2 = 0b101;
intanInt3 = 0B101; // The B can be upper or lower case.
// A 64-bit 'long' value. Note the "L" suffix:
long aLong = 0b1010000101000101101000010100010110100001010001011010000101000101L;
// 二进制在数组等的使用
final int[] phases = { 0b00110001, 0b01100010, 0b11000100, 0b10001001,
0b00010011, 0b00100110, 0b01001100, 0b10011000 };
1.2 Switch语句支持string类型
public static String getTypeOfDayWithSwitchStatement(String dayOfWeekArg) {
String typeOfDay;
switch (dayOfWeekArg) {
case "Monday":
typeOfDay = "Start of work week";
break;
case "Tuesday":
case "Wednesday":
case "Thursday":
typeOfDay = "Midweek";
break;
case "Friday":
typeOfDay = "End of work week";
break;
case "Saturday":
case "Sunday":
typeOfDay = "Weekend";
break;
default:
throw new IllegalArgumentException("Invalid day of the week: " + dayOfWeekArg);
}
return typeOfDay;
}
1.3 Try-with-resource语句
注意:实现java.lang.AutoCloseable接口的资源都可以放到try中,跟final里面的关闭资源类似; 按照声明逆序关闭资源 ;Try块抛出的异常通过Throwable.getSuppressed获取
try (java.util.zip.ZipFile zf = new java.util.zip.ZipFile(zipFileName);
java.io.BufferedWriter writer = java.nio.file.Files
.newBufferedWriter(outputFilePath, charset)) {
// Enumerate each entry
for (java.util.Enumeration entries = zf.entries(); entries
.hasMoreElements();) {
// Get the entry name and write it to the output file
String newLine = System.getProperty("line.separator");
String zipEntryName = ((java.util.zip.ZipEntry) entries
.nextElement()).getName() + newLine;
writer.write(zipEntryName, 0, zipEntryName.length());
}
}
1.4 Catch多个异常 说明:Catch异常类型为final; 生成Bytecode 会比多个catch小; Rethrow时保持异常类型
public static void main(String[] args) throws Exception {
try {
testthrows();
} catch (IOException | SQLException ex) {
throw ex;
}
}
public static void testthrows() throws IOException, SQLException {
}
1.5 数字类型的下划线表示 更友好的表示方式,不过要注意下划线添加的一些标准,可以参考下面的示例
long creditCardNumber = 1234_5678_9012_3456L;
long socialSecurityNumber = 999_99_9999L;
float pi = 3.14_15F;
long hexBytes = 0xFF_EC_DE_5E;
long hexWords = 0xCAFE_BABE;
long maxLong = 0x7fff_ffff_ffff_ffffL;
byte nybbles = 0b0010_0101;
long bytes = 0b11010010_01101001_10010100_10010010;
//float pi1 = 3_.1415F; // Invalid; cannot put underscores adjacent to a decimal point
//float pi2 = 3._1415F; // Invalid; cannot put underscores adjacent to a decimal point
//long socialSecurityNumber1= 999_99_9999_L; // Invalid; cannot put underscores prior to an L suffix
//int x1 = _52; // This is an identifier, not a numeric literal
int x2 = 5_2; // OK (decimal literal)
//int x3 = 52_; // Invalid; cannot put underscores at the end of a literal
int x4 = 5_______2; // OK (decimal literal)
//int x5 = 0_x52; // Invalid; cannot put underscores in the 0x radix prefix
//int x6 = 0x_52; // Invalid; cannot put underscores at the beginning of a number
int x7 = 0x5_2; // OK (hexadecimal literal)
//int x8 = 0x52_; // Invalid; cannot put underscores at the end of a number
int x9 = 0_52; // OK (octal literal)
int x10 = 05_2; // OK (octal literal)
//int x11 = 052_; // Invalid; cannot put underscores at the end of a number
1.6 泛型实例的创建可以通过类型推断来简化 可以去掉后面new部分的泛型类型,只用<>就可以了。
//使用泛型前
List strList = new ArrayList();
List<String> strList4 = new ArrayList<String>();
List<Map<String, List<String>>> strList5 = new ArrayList<Map<String, List<String>>>();
//编译器使用尖括号 (<>) 推断类型
List<String> strList0 = new ArrayList<String>();
List<Map<String, List<String>>> strList1 = new ArrayList<Map<String, List<String>>>();
List<String> strList2 = new ArrayList<>();
List<Map<String, List<String>>> strList3 = new ArrayList<>();
List<String> list = new ArrayList<>();
list.add("A");
// The following statement should fail since addAll expects
// Collection<? extends String>
//list.addAll(new ArrayList<>());
1.7在可变参数方法中传递非具体化参数,改进编译警告和错误
Heap pollution 指一个变量被指向另外一个不是相同类型的变量。例如
List l = new ArrayList<Number>();
List<String> ls = l; // unchecked warning
l.add(0, new Integer(42)); // another unchecked warning
String s = ls.get(0); // ClassCastException is thrown
Jdk7:
public static <T> void addToList (List<T> listArg, T... elements) {
for (T x : elements) {
listArg.add(x);
}
}
你会得到一个warning
warning: [varargs] Possible heap pollution from parameterized vararg type
要消除警告,可以有三种方式
1.加 annotation @SafeVarargs
2.加 annotation @SuppressWarnings({"unchecked", "varargs"})
3.使用编译器参数 –Xlint:varargs;
1.8 信息更丰富的回溯追踪 就是上面try中try语句和里面的语句同时抛出异常时,异常栈的信息
java.io.IOException
§? at Suppress.write(Suppress.java:19)
§? at Suppress.main(Suppress.java:8)
§? Suppressed: java.io.IOException
§? at Suppress.close(Suppress.java:24)
§? at Suppress.main(Suppress.java:9)
§? Suppressed: java.io.IOException
§? at Suppress.close(Suppress.java:24)
§? at Suppress.main(Suppress.java:9)
2. NIO2的一些新特性
1.java.nio.file 和java.nio.file.attribute包 支持更详细属性,比如权限,所有者
2. symbolic and hard links支持
3. Path访问文件系统,Files支持各种文件操作
4.高效的访问metadata信息
5.递归查找文件树,文件扩展搜索
6.文件系统修改通知机制
7.File类操作API兼容
8.文件随机访问增强 mapping a region,locl a region,绝对位置读取
9. AIO Reactor(基于事件)和Proactor
下面列一些示例:
2.1IO and New IO 监听文件系统变化通知
通过FileSystems.getDefault().newWatchService()获取watchService,然后将需要监听的path目录注册到这个watchservice中,对于这个目录的文件修改,新增,删除等实践可以配置,然后就自动能监听到响应的事件。
private WatchService watcher;
public TestWatcherService(Path path) throws IOException {
watcher = FileSystems.getDefault().newWatchService();
path.register(watcher, ENTRY_CREATE, ENTRY_DELETE, ENTRY_MODIFY);
}
public void handleEvents() throws InterruptedException {
while (true) {
WatchKey key = watcher.take();
for (WatchEvent<?> event : key.pollEvents()) {
WatchEvent.Kind kind = event.kind();
if (kind == OVERFLOW) {// 事件可能lost or discarded
continue;
}
WatchEvent<Path> e = (WatchEvent<Path>) event;
Path fileName = e.context();
System.out.printf("Event %s has happened,which fileName is %s%n",kind.name(), fileName);
}
if (!key.reset()) {
break;
}
2.2 IO and New IO遍历文件树 ,通过继承SimpleFileVisitor类,实现事件遍历目录树的操作,然后通过Files.walkFileTree(listDir, opts, Integer.MAX_VALUE, walk);这个API来遍历目录树
private void workFilePath() {
Path listDir = Paths.get("/tmp"); // define the starting file
ListTree walk = new ListTree();
…Files.walkFileTree(listDir, walk);…
// 遍历的时候跟踪链接
EnumSet opts = EnumSet.of(FileVisitOption.FOLLOW_LINKS);
try {
Files.walkFileTree(listDir, opts, Integer.MAX_VALUE, walk);
} catch (IOException e) {
System.err.println(e);
}
class ListTree extends SimpleFileVisitor<Path> {// NIO2 递归遍历文件目录的接口
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) {
System.out.println("Visited directory: " + dir.toString());
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) {
System.out.println(exc);
return FileVisitResult.CONTINUE;
}
}
2.3 AIO异步IO 文件和网络 异步IO在java
NIO2实现了,都是用AsynchronousFileChannel,AsynchronousSocketChanne等实现,关于同步阻塞IO,同步非阻塞IO,异步阻塞IO和异步非阻塞IO在ppt的这页上下面备注有说明,有兴趣的可以深入了解下。Java NIO2中就实现了操作系统的异步非阻塞IO。
// 使用AsynchronousFileChannel.open(path, withOptions(),
// taskExecutor))这个API对异步文件IO的处理
public static void asyFileChannel2() {
final int THREADS = 5;
ExecutorService taskExecutor = Executors.newFixedThreadPool(THREADS);
String encoding = System.getProperty("file.encoding");
List<Future<ByteBuffer>> list = new ArrayList<>();
int sheeps = 0;
Path path = Paths.get("/tmp",
"store.txt");
try (AsynchronousFileChannel asynchronousFileChannel = AsynchronousFileChannel
.open(path, withOptions(), taskExecutor)) {
for (int i = 0; i < 50; i++) {
Callable<ByteBuffer> worker = new Callable<ByteBuffer>() {
@Override
public ByteBuffer call() throws Exception {
ByteBuffer buffer = ByteBuffer
.allocateDirect(ThreadLocalRandom.current()
.nextInt(100, 200));
asynchronousFileChannel.read(buffer, ThreadLocalRandom
……
3. JDBC 4.1
3.1.可以使用try-with-resources自动关闭Connection, ResultSet, 和 Statement资源对象
3.2. RowSet 1.1:引入RowSetFactory接口和RowSetProvider类,可以创建JDBC driver支持的各种 row sets,这里的rowset实现其实就是将sql语句上的一些操作转为方法的操作,封装了一些功能。
3.3. JDBC-ODBC驱动会在jdk8中删除
try (Statement stmt = con.createStatement()) {
RowSetFactory aFactory = RowSetProvider.newFactory();
CachedRowSet crs = aFactory.createCachedRowSet();
RowSetFactory rsf = RowSetProvider.newFactory("com.sun.rowset.RowSetFactoryImpl", null);
WebRowSet wrs = rsf.createWebRowSet();
createCachedRowSet
createFilteredRowSet
createJdbcRowSet
createJoinRowSet
createWebRowSet
4. 并发工具增强
4.1.fork-join
最大的增强,充分利用多核特性,将大问题分解成各个子问题,由多个cpu可以同时解决多个子问题,最后合并结果,继承RecursiveTask,实现compute方法,然后调用fork计算,最后用join合并结果。
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
private int compute(int small) {
final int[] results = { 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 };
return results[small];
}
public Integer compute() {
if (n <= 10) {
return compute(n);
}
Fibonacci f1 = new Fibonacci(n - 1);
Fibonacci f2 = new Fibonacci(n - 2);
System.out.println("fork new thread for " + (n - 1));
f1.fork();
System.out.println("fork new thread for " + (n - 2));
f2.fork();
return f1.join() + f2.join();
}
}
4.2.ThreadLocalRandon 并发下随机数生成类,保证并发下的随机数生成的线程安全,实际上就是使用threadlocal
final int MAX = 100000;
ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
long start = System.nanoTime();
for (int i = 0; i < MAX; i++) {
threadLocalRandom.nextDouble();
}
long end = System.nanoTime() - start;
System.out.println("use time1 : " + end);
long start2 = System.nanoTime();
for (int i = 0; i < MAX; i++) {
Math.random();
}
long end2 = System.nanoTime() - start2;
System.out.println("use time2 : " + end2);
4.3. phaser 类似cyclebarrier和countdownlatch,不过可以动态添加资源减少资源
void runTasks(List<Runnable> tasks) {
final Phaser phaser = new Phaser(1); // "1" to register self
// create and start threads
for (final Runnable task : tasks) {
phaser.register();
new Thread() {
public void run() {
phaser.arriveAndAwaitAdvance(); // await all creation
task.run();
}
}.start();
}
// allow threads to start and deregister self
phaser.arriveAndDeregister();
}
5. Networking增强
新增URLClassLoader close方法,可以及时关闭资源,后续重新加载class文件时不会导致资源被占用或者无法释放问题
URLClassLoader.newInstance(new URL[]{}).close();
新增Sockets Direct Protocol
绕过操作系统的数据拷贝,将数据从一台机器的内存数据通过网络直接传输到另外一台机器的内存中
6. Multithreaded Custom Class Loaders
解决并发下加载class可能导致的死锁问题,这个是jdk1.6的一些新版本就解决了,jdk7也做了一些优化。有兴趣可以仔细从官方文档详细了解
jdk7前:
Class Hierarchy:
class A extends B
class C extends D
ClassLoader Delegation Hierarchy:
Custom Classloader CL1:
directly loads class A
delegates to custom ClassLoader CL2 for class B
Custom Classloader CL2:
directly loads class C
delegates to custom ClassLoader CL1 for class D
Thread 1:
Use CL1 to load class A (locks CL1)
defineClass A triggers
loadClass B (try to lock CL2)
Thread 2:
Use CL2 to load class C (locks CL2)
defineClass C triggers
loadClass D (try to lock CL1)
Synchronization in the ClassLoader class wa
jdk7
Thread 1:
Use CL1 to load class A (locks CL1+A)
defineClass A triggers
loadClass B (locks CL2+B)
Thread 2:
Use CL2 to load class C (locks CL2+C)
defineClass C triggers
loadClass D (locks CL1+D)
7. Security 增强
7.1.提供几种 ECC-based algorithms (ECDSA/ECDH) Elliptic Curve Cryptography (ECC)
7.2.禁用CertPath Algorithm Disabling
7.3. JSSE (SSL/TLS)的一些增强
8. Internationalization 增强 增加了对一些编码的支持和增加了一些显示方面的编码设置等
1. New Scripts and Characters from Unicode 6.0.0
2. Extensible Support for ISO 4217 Currency Codes
Currency类添加:
getAvailableCurrencies
getNumericCode
getDisplayName
getDisplayName(Locale)
3. Category Locale Support
getDefault(Locale.Category)FORMAT DISPLAY
4. Locale Class Supports BCP47 and UTR35
UNICODE_LOCALE_EXTENSION
PRIVATE_USE_EXTENSION
Locale.Builder
getExtensionKeys()
getExtension(char)
getUnicodeLocaleType(String
……
5. New NumericShaper Methods
NumericShaper.Range
getShaper(NumericShaper.Range)
getContextualShaper(Set<NumericShaper.Range>)……
9.jvm方面的一些特性增强,下面这些特性有些在jdk6中已经存在,这里做了一些优化和增强。
1.Jvm支持非java的语言 invokedynamic 指令
2. Garbage-First Collector 适合server端,多处理器下大内存,将heap分成大小相等的多个区域,mark阶段检测每个区域的存活对象,compress阶段将存活对象最小的先做回收,这样会腾出很多空闲区域,这样并发回收其他区域就能减少停止时间,提高吞吐量。
3. HotSpot性能增强
Tiered Compilation -XX:+UseTieredCompilation 多层编译,对于经常调用的代码会直接编译程本地代码,提高效率
Compressed Oops 压缩对象指针,减少空间使用
Zero-Based Compressed Ordinary Object Pointers (oops) 进一步优化零基压缩对象指针,进一步压缩空间
4. Escape Analysis 逃逸分析,对于只是在一个方法使用的一些变量,可以直接将对象分配到栈上,方法执行完自动释放内存,而不用通过栈的对象引用引用堆中的对象,那么对于对象的回收可能不是那么及时。
5. NUMA Collector Enhancements
NUMA(Non Uniform Memory Access),NUMA在多种计算机系统中都得到实现,简而言之,就是将内存分段访问,类似于硬盘的RAID,Oracle中的分簇
10. Java 2D Enhancements
1. XRender-Based Rendering Pipeline -Dsun.java2d.xrender=True
2. Support for OpenType/CFF Fonts GraphicsEnvironment.getAvailableFontFamilyNames
3. TextLayout Support for Tibetan Script
4. Support for Linux Fonts
11. Swing Enhancements
1. JLayer
2. Nimbus Look & Feel
3. Heavyweight and Lightweight Components
4. Shaped and Translucent Windows
5. Hue-Saturation-Luminance (HSL) Color Selection in JColorChooser Class
12. Jdk8 lambda表达式 最大的新增的特性,不过在很多动态语言中都已经原生支持。
原来这么写:
btn.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
System.out.println("Hello World!");
}
});
jdk8直接可以这么写:
btn.setOnAction(
event -> System.out.println("Hello World!")
);
更多示例:
public class Utils {
public static int compareByLength(String in, String out){
return in.length() - out.length();
}
}
public class MyClass {
public void doSomething() {
String[] args = new String[] {"microsoft","apple","linux","oracle"}
Arrays.sort(args, Utils::compareByLength);
}
}
13.jdk8的一些其他特性,当然jdk8的增强功能还有很多,大家可以参考http://openjdk.java.net/projects/jdk8/
用Metaspace代替PermGen
动态扩展,可以设置最大值,限制于本地内存的大小
Parallel array sorting 新APIArrays#parallelSort.
New Date & Time API
Clock clock = Clock.systemUTC(); //return the current time based on your system clock and set to UTC.
Clock clock = Clock.systemDefaultZone(); //return time based on system clock zone
long time = clock.millis(); //time in milliseconds from January 1st, 1970















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









