







 本文详细介绍了B树、B+树和B*树的结构、查找与插入算法,重点阐述了它们在数据库中的应用,特别是MySQL中的MyISAM和InnoDB引擎如何利用这些数据结构作为索引。B+树因其特性在查找和遍历上的优势,成为数据库索引的常用选择。通过对这两种引擎的分析,揭示了InnoDB在性能和效率上的优势。
本文详细介绍了B树、B+树和B*树的结构、查找与插入算法,重点阐述了它们在数据库中的应用,特别是MySQL中的MyISAM和InnoDB引擎如何利用这些数据结构作为索引。B+树因其特性在查找和遍历上的优势,成为数据库索引的常用选择。通过对这两种引擎的分析,揭示了InnoDB在性能和效率上的优势。
接触到了数据结构当中的B树,B+树,B*树,我觉得应该写一篇博客记录下,毕竟是第一次接触的,只有写了博客以后,感觉对这个的印象才会更加深刻。
前言:
为什么要有B树?
学习任何一个东西我们都要知道为什么要有它,B树也一样,既然存储数据,我们为什么不用红黑树呢?
这个要从几个方面来说了,
计算机有一个局部性原理,就是说,当一个数据被用到时,其附近的数据也通常会马上被使用。
所以当你用红黑树的时候,你一次只能得到一个键值的信息,而用B树,可以得到最多M-1个键值的信息。这样来说B树当然更好了。
另外一方面,同样的数据,红黑树的阶数更大,B树更短,这样查找的时候当然B树更具有优势了,效率也就越高。
一.B树
首先我们来谈一谈关于B树的问题,
对于B树,我们首先要知道它的应用,B树大量应用在数据库和文件系统当中。
B树是对二叉查找树的改进。它的设计思想是,将相关数据尽量集中在一起,以便一次读取多个数据,减少硬盘操作次数。
B树为系统最优化大块数据的读和写操作。B树算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。
假定一个节点可以容纳100个值,那么3层的B树可以容纳100万个数据,如果换成二叉查找树,则需要20层!假定操作系统一次读取一个节点,并且根节点保留在内存中,那么B树在100万个数据中查找目标值,只需要读取两次硬盘。
B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
B树的结构要求:
1)根节点至少有两个子节点
2)每个节点有M-1个key,并且以升序排列
3)位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
4)其它节点至少有M/2个子节点
5)所有叶子节点都在同一层
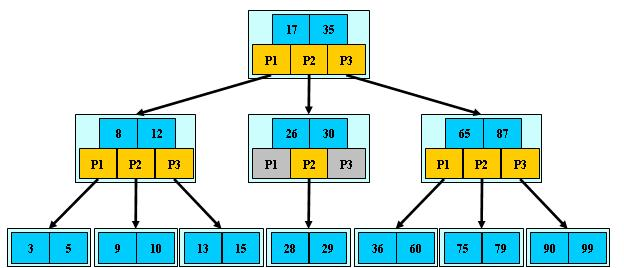
根据B树的特点,我们首先可以写出B树的整体的结构。
1.B树结构
B树的结构我们定义需要参考规则,我们首先是需要给出保存键值的一个数组,这个数组的大小取决与我们定义的M,然后我们根据规则,可以得到一个保存M+1个子的一个数组,然后当然为了方便访问,parent指针,然后要有一个记录每个节点中键值个数的一个size。
所以定义如下:
template <typename K,int M>
struct BTreeNode
{
K _keys[M]; //用来保存键值。
BTreeNode<K, M>* _sub[M + 1]; //用来保存子。
BTreeNode<K, M>* _parent;
size_t _size;
BTreeNode()
:_parent(NULL)
, _size(0)
{
int i = 0;
for ( i = 0; i < M; i++)
{
_keys[i] = K();
_sub[i] = K();
}
_sub[i] = K();
}
};
2.B树的查找
对于AVL,BST,红黑树,B树这些高级的数据结构而言,查找算法是非常重要的。我们首先确定返回值,对于这种关于key和key-value的数据结构,参考map和set,我们让它返回一个pair的一个结构体。
pair结构体的定义在std中是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









