







查看数据库
主要使用list-databases命令来对数据库进行查看:
sqoop list-databases \
--connect jdbc:mysql://master:3306 \
--username hive \
--password 123456使用如下指令可以对主机名为master的机器上的mysql下的数据库进行查看,结果如下:

这种方式也是进行验证sqoop访问是否可以访问数据库的一种有效的方法
,同理也可以使用list-tables去查看指定数据库下的表
此种方式直接输入password进行访问,对于数据库来说是不安全,我们可以使用-P的方式进行访问,这样是采用了交互式的方式,只有当正确输入了密码才能进行sqoop操作,保证了密码的安全性.
sqoop list-databases \
--connect jdbc:mysql://master:3306 \
--username hive \
-P在生产环境中还可以使用password-file,指定一个文件,使用文件内的内容作为访问的密码.
例如我们可以在linux下使用echo将密码追加到文件中去,注意该文件默认是要放在hdfs上,因此需要把该文件put到hdfs上
echo '123456' > password.pwd
hdfs dfs -put password.pwd /test然后执行如下内容,通过访问hdfs上的密码文件进行数据库的访问
sqoop list-databases \
--connect jdbc:mysql://master:3306 \
--username hive \
--password-file /test/password.pwd暂时此方法还有问题
数据导入HDFS
下面介绍将mysql的表导入HDFS中
我们将test库下的customer表导入hdfs中,customer表的建表指令及insert数据指令如下:
create table customer(id int,name varchar(50));
insert into customer values(1,'neil');
insert into customer values(2,'jack');
insert into customer values(3,'martin');
insert into customer values(4,'tony');
insert into customer values(5,'eric');我们执行如下指令将customer表进行导入
sqoop import \
--connect jdbc:mysql://master:3306/test \
--username hive \
--password 123456 \
--table customer执行此指令,却发现如下错误
16/12/14 17:33:05 ERROR tool.ImportTool: Error during import: No primary key could be found for table customer. Please specify one with –split-by or perform a sequential import with ‘-m 1’.
此时的错误是因为我们所要导入的customer表未设定主键,这个错误有两种解决的办法,一个是为customer设置主键,二是设定split-by选项或者-M来解决.
我们先使用设置主键的方法去解决此问题
alter table customer add primary key (id);设置customer表的id字段为该表的主键,再次执行,我们发现执行已成功,出现如下的内容:
16/12/14 17:52:10 INFO mapreduce.ImportJobBase: Transferred 37 bytes in 25.6157 seconds (1.4444 bytes/sec)
16/12/14 17:52:10 INFO mapreduce.ImportJobBase: Retrieved 5 records.
最终使用25s,导入数据条数为5条,可见sqoop对于小数据量的导入优势不是很明显
我们可以到webUI界面去查看job执行的情况,其实从终端的指令我们可以看出,其实sqoop会把我们的import任务转化为MR任务.我们到master:18088,发现出现了id名为application_1481523617291_0004的job,他的name是我们表名.jar

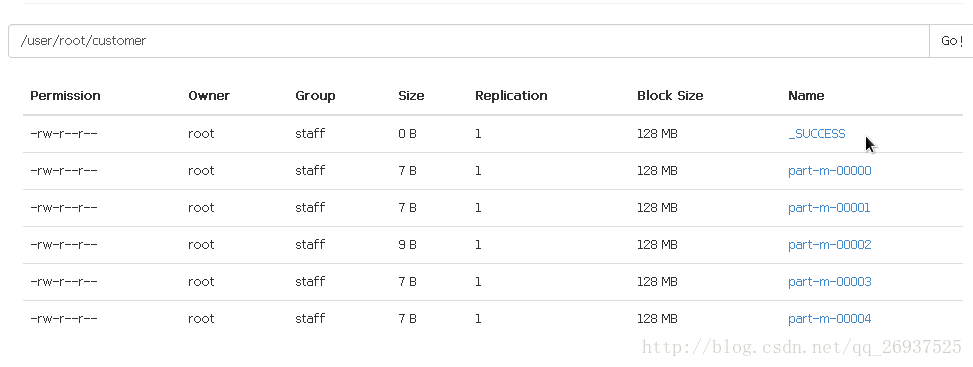
我们在上述的导入操作中并未指定导入HDFS的路径,默认导入到user目录下以用户名所命名的文件夹下,我们到50070下去查看,发现我们的root目录下已经出现了customer文件夹,打开之后发现customer已经存储在这里
- _SUCCESS文件内并没有存储内容,只表示成功的状态
- part文件代表文件存储的分块,-m表示操作只进行了map的操作,并没有进行reduce操作
- 我们没有指定并行度,sqoop将我们的表分成了5份
指定路径导入
在上述的sqoop指令后加入
--warehouse-dir XXX可以指定导入的路径,同时也要注意该路径是不能已经存在的
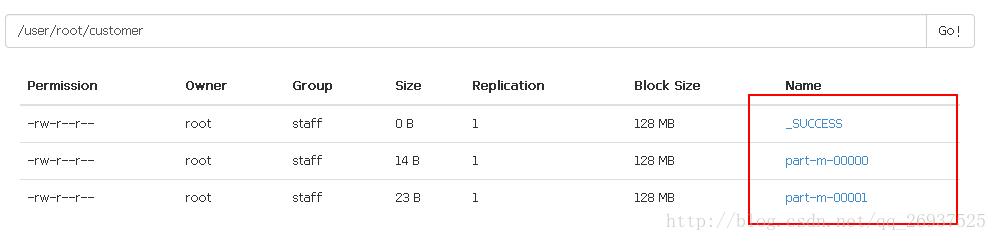
指定并行度
在上述的sqoop指令后加入
-m 2这样可以指定map操作的并行度为2,最终我们会发现文件会被分为2份:
控制分隔符
sqoop默认导入的分隔符为”,”号,在这里我们可以通过增加–field参数来制定分隔符
--fields-terminated-by "|"我们制定竖线来进行分隔,执行之后我们去cat存储的文件内容
hdfs dfs -cat /user/root/customer/part-m-00000

导入部分数据
- 使用–query可以实现sqoop的部分导入
sqoop import \
--connect jdbc:mysql://master:3306/test \
--username hive \
--password 123456 \
--query "select * from customer where id <=3 and \$CONDITIONS" \
-m 1 \
--target-dir /user/root/customer要注意使用–query导入部分数据时,不能再指定–table参数,同时必须指定–target-dir参数,否则则会报错.另外在where的筛选条件中一定要加上”and $CONDITIONS”
- 使用–where导入部分数据
sqoop import \
--connect jdbc:mysql://master:3306/test \
--username hive \
--password 123456 \
--table customer \
--where "id<=3" - 使用–columns指定导入的列
sqoop import \
--connect jdbc:mysql://master:3306/test \
--username hive \
--password 123456 \
--table customer \
--columns name我们这里只导入name列,在–columns后指定需要导入的列
使用配置文件控制导入
我们可以把上面输入操作指令写入到一个配置文件中,在sqoop导入时使用配置文件,实现同样的功能
我们vim一个名为sqoop.im的文件,将如下内容写入,注意参数值和内容必须独自成行
import
--connect
jdbc:mysql://master:3306/test
--username
hive
--password
123456
--table
customer
--columns
name在终端中执行
sqoop --options-file sqoop.im便可以使用sqoop.im进行数据的导入
sqoop的java代码生成
在进行数据导入的同时,sqoop还生成了一个java源文件,我们这里会生成一个名为customer.java文件,记录了导入的操作.














 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









