









假设要在一篇文章里查找”he”,可以使用正则表达式”he”。这几乎是最简单的正则表达式,它可以精确匹配这样的字符串:由两个字符组成,前一个字符是”h”,后一个是”e”。通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中这个选项,它可以匹配”he”,”HE”,”He”,”hE”这四种情况中的任意一种。
但是很多单词里包含”he”这两个连续的字符,比如”her”、”heet”等。用”he”来查找,这些单词中的”he”也会被找出来。如果要精确地查找”he”这个单词,应该使用以下形式:
\bhe\b"\b"是正则表达式规定的一个特殊代码,代表单词的开头或结尾,也就是单词的分界处。虽然通常英文单词是由空格、标点符号或者换行来分隔,但是"\b"并不匹配这些单词的分割字符中的任何一个,它只匹配一个位置。
"\b"匹配位置的精确说法:前一个字符和后一个字符不全是(一个是,一个不是或不存在)"\w"。
假如要找”he”后面不远处跟着一个”is”,应该表示如下:
\bhe\b.*is\b这里,点号(.)是元字符,匹配除了换行符以外的任意字符。"*"同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定"*"前边的内容可以连续重复使用任意次以使整个表达式得到匹配。因此,"."和"*"连在一起就意味着任意数量的、不包含换行的字符。现在,"\bhe\b.*\bis\b"的意思很明显:先是一个单词he,然后是任意个任意字符(但不能是换行符),最后是is这个单词。
什么是元字符
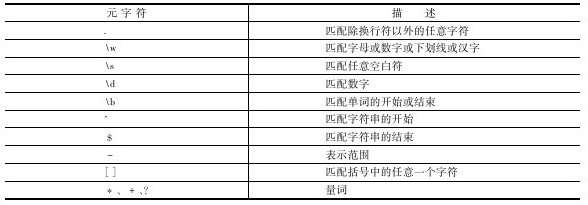
元字符(Meta Characters)是正则表达式中具有特殊意义的专用字符,用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。通过前面的例子,我们已经知道几个很有用的元字符。正则表达式里有很多元字符,常用元字符如下表所示。
例子:
1)匹配以字母”a”开头的单词:
\ba\w*\b以上表达式先是某个单词开始处(\b),然后是字母”a”,接着是任意数量的字母或数字(\w*),最后是单词结束处(\b),匹配的单词如adandon、action、a等。
2)匹配1个或更多连续的数字:
\d+以上表达式可以匹配0、1、555等。这里的元字符+和*类似,不同的是,*匹配重复任意次(可能是0次),而+则匹配重复1次或更多次。
3)匹配刚好6个字符的单词:
\b\w{6}\b以上表达式匹配action、123456、ste_ph等。
【注意】 正则表达式里”单词”指不少于1个的连续字母和数字。
如果同时使用其他元字符,则能构造出功能更强大的正则表达式。比如下面这个例子:
0\d\d-\d\d\d\d\d\d\d\d匹配字符串:以0开头,然后是2个数字,1个连字符,最后是8个数字,也就是中国部分地区的电话号码,如010-12345678。
这里"\d"是元字符,匹配1位数字(0、1、2……)。"-"不是元字符,只匹配它本身——连字符(或者减号,或者中横线,或者随你怎么称呼它)。
为了避免那么多烦人的重复,也可以这样写这个表达式:
0\d{2}-\d{8}这里\d后面{2}和{8}的意思是,前面\d必须连续重复匹配2次和8次。
起始和结束元字符
元字符中有两个用来匹配位置:
^:匹配字符串的开始。
$:匹配字符串的结束。
元字符"^"、"$"与"\b"有点类似。"^"匹配字符串的开头,"$"匹配结尾。这两个代码在验证输入内容时非常有用,比如某网站如果要求填写QQ号必须为5~11位数字时,可以使用:
^\d{5,11}$这里{5,11}表示重复次数不能少于5次,不能多于11次,否则都不匹配。因为使用”^”和”$”,所以输入的整个字符串都要和\d{5,11}匹配。也就是说,整个输入必须是5~11个数字,如果输入QQ号能匹配这个正则表达式,就符合要求。如果输入含有5~11个数字,但不是完整数字串,而只是一串字符的一部分,也不能匹配成功,如图
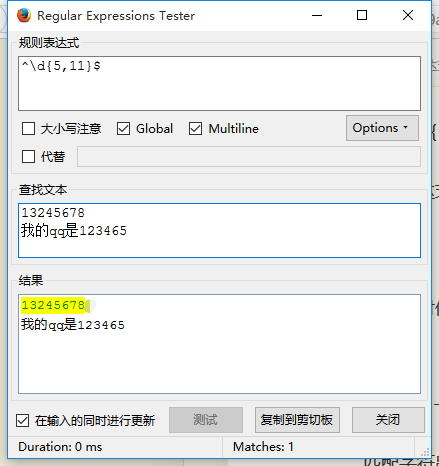
从图中就能清晰地看出^\d{5,11}$的确切含义。我想,你也能猜测到它和正则表达式\d{5,11}的区别。为了加深印象,分别使用下面4个正则表达式看一下效果:
^\d{5,11}$ //匹配起始和结束位置都是数字的,且连续5-11位
\d{5,11}$ //匹配结束位置是数字的,且连续5-11位
^\d{5,11} //匹配起始位置是数字的,且连续5-11位
\d{5,11} //匹配连续的5-11位数字【注意】 我们在正则表达式处理工具处勾选Multiline选项,即多行选项,^和的意义就变成匹配行的开始处和结束处,否则将把整个输入视作一个字符串,忽视换行符。可以试着把多行选项去除后再看看效果。如果用过Vim编辑器,就知道命令”d^”和”d”的作用了。
点号
点号(.)是使用频率最高的元字符。例如,在做采集时抓取页面,要匹配某DIV里的内容,就需要用到点号匹配。下面代码是抓取本地HTML页面的一部分:
<!DOCTYPE HTML>
<html>
<head>
<meta charset="UTF-8">
<meta name="description" content="107网站工作室">
<title>107网站工作室</title>
<link rel="stylesheet" type="text/css" href="http://www.107lab.com/css/style1.css" />要匹配这个网页的标题应该怎么办呢?很简单,使用点号匹配全部字符,如下:
<title>.*<\/title>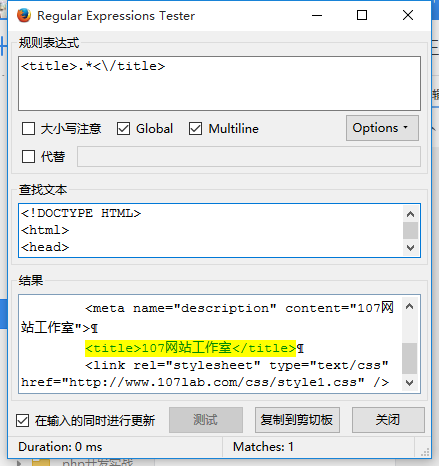
这样就可以抓取你想要的任何内容了,包括DIV、SPAN等。
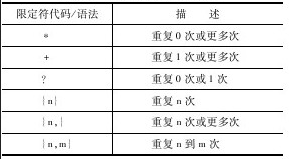
量词
前面实际上已经涉及量词的概念,比如\d+、\d{5,11}等都应用了量词。正则表达式中的量词如下表所示。
下面是一些例子:
1)匹配Windows后面跟1个或更多数字:
Windows\d+2)表示index后面紧跟0个或1个数字,:
index\d?以上表达式匹配index、index1、index9这样的文件名,但不匹配index10、indexa这样的文件名。
3)匹配一行第一个单词(或整个字符串第一个单词,具体匹配哪种,得看选项设置):
^\w+提示 在学习量词的过程中,要【注意】*和?这两个量词。前面提到过通配符的概念,通配符里也有这两个符号,要【注意】它们之间的区别。















 1734
1734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









