









JavaWeb之文件上传 和 文件下载
2016年11月25日19:54:35(javaweb 学习日记)
导读{
}
【1】文件上传
【1.1】表单页面设置
在Web应用中,由于大多数文件的上传都是通过表单的形式提交给服务器的,因此,要想在程序中实现文件上传的功能,首先得创建一个用于提交上传文件的表单页面。

为了使Servlet程序可以获取到上传文件的数据,需要将表单页面的method属性设置为post方式,enctype属性设置为“multipart/form-data”类型,添加文件的input标签类型设置为file类型。
【1.2】Servlet编写
【1.2.1】基本知识点
由于
请求正文
由
多个部分
组成
,解析这部分内容比较麻烦。
实现文件的上传主要通过
Apache
组织提供了一个开源组件
Commons-FileUpload 来实现
需要用到
/commons-fileupload-1.2.jar 实现上传 下载地址
http://cn.jarfire.org/commons.fileupload.html
DiskFileItemFactory类用于将请求消息实体中的每一个文件封装成单独的FileItem对象。如果上传的文件比较小,将直接保存在内存中,如果上传的文件比较大,则会以临时文件的形式,保存在磁盘的临时文件夹中。默认情况下,文件保存在内存还是硬盘临时文件夹的临界值是10240,即10kb。


ServletFileUpload 方法声明
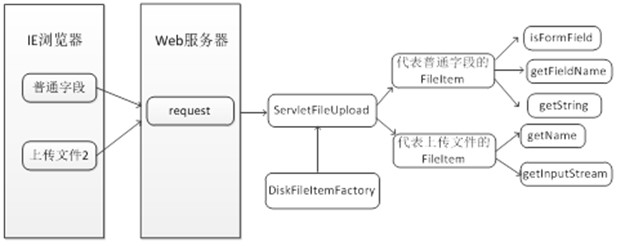
其中我们处理上传文件的时候,通常我们都有上传用户,谁上传的文件。\
我们可以在表单中设置一个 name= username type=text 的参数
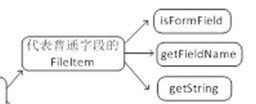
//如果当前表单项为普通文本字段
if(fileItem.isFormField()){
//获取当前表单项的字段名称
String filedName = fileItem.getFieldName();
//如果表单字段名为username
if(filedName.equals("username")){
//输出当前用户输入的值,用UTF-8解码解决中文乱码
response.getWriter().print("用户名:"+fileItem.getString("UTF-8")+"<br>");
}这样就拿到我们的上传用户![]()
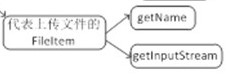
//获取上传的文件名(原始文件名)Stringname=fileItem.getName();FileItem 中的方法声明【1.2.2】代码部分
(1)servlet.java
package cn.edu.aynu.rjxy.servlet;import java.io.File;import java.io.IOException;import java.util.List;import java.util.UUID;import javax.servlet.ServletException;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import org.apache.commons.fileupload.FileItem;import org.apache.commons.fileupload.FileUploadBase;import org.apache.commons.fileupload.FileUploadException;import org.apache.commons.fileupload.disk.DiskFileItemFactory;import org.apache.commons.fileupload.servlet.ServletFileUpload;public class UploadServlet extends HttpServlet {public void doPost(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {//处理响应的中文乱码response.setContentType("text/html;charset=UTF-8");//创建工厂对象DiskFileItemFactory factory = new DiskFileItemFactory();//使用工厂对象创建ServletFileUpload对象(解析器)ServletFileUpload fileUpload = new ServletFileUpload(factory);//解决文件名中文乱码fileUpload.setHeaderEncoding("UTF-8");//设置上传的单个文件的大小,不能超过1024kB(1MB)fileUpload.setFileSizeMax(1024*1024);try {//使用解析器解析request,得到包含fileItem对象的链表List<FileItem> list = fileUpload.parseRequest(request);//遍历list,得到每一个fileItem(也就是每一个表单项)for(FileItem fileItem:list){//如果当前表单项为普通文本字段if(fileItem.isFormField()){//获取当前表单项的字段名称String filedName = fileItem.getFieldName();//如果表单字段名为usernameif(filedName.equals("username")){//输出当前用户输入的值,用UTF-8解码解决中文乱码response.getWriter().print("用户名:"+fileItem.getString("UTF-8")+"<br>");}}else{//文件上传字段//获取上传的文件名(原始文件名)String name = fileItem.getName();
- //我们先得到最后一个 \ 字符的位置,那么需要用到转义字符 \\ 转义就是 \
int lastIndexOf = name.lastIndexOf("\\");//切割字符串String substring = name.substring(lastIndexOf + 1);name = substring;
//如果上传的文件名为空(没有指定上传文件)if(name==null||name.isEmpty()){continue;}//获取上传文件保存的真实路径(绝对路径),上传的文件保存的目录String savepath = this.getServletContext().getRealPath("/WEB-INF/uploads");//使用UUID对上传的文件进行重命名,保证文件名是唯一的String uuid = UUID.randomUUID().toString();//新的文件名,格式:uuid_原始文件名String filename = uuid+"_"+name;/*** 在uploads目录下创建多个文件夹,让每个文件夹存放少量文件int hashcode = name.hashCode();//获取hashcode的低4位,并转换成16进制字符串String dir1 = Integer.toHexString(hashcode & 0XF);//获取hashcode的5~8位,并转换成16进制字符串String dir2 = Integer.toHexString(hashcode>>>4 & 0XF);//与文件目录合并构成完整路径savepath = savepath + "/" + dir1 +"/" +dir2;//如果不存在,就创建文件夹new File(savepath).mkdirs();*///通过文件保存目录和文件名创建File对象File file = new File(savepath, filename);//将上传文件保存到指定位置,上传结束fileItem.write(file);//给客户端输出一些提示response.getWriter().print("上传文件名:"+name+"<br>");response.getWriter().print("上传文件的大小:"+fileItem.getSize()+"<br>");response.getWriter().print("上传文件的类型:"+fileItem.getContentType());}}} catch (Exception e) {//判断抛出的异常是否为超出了单个文件大小的上限if(e instanceof FileUploadBase.FileSizeLimitExceededException){//将错误消息放到request域中request.setAttribute("msg", "上传失败,上传文件超过了1M字节!");//通过请求转发将消息带到upload.jsp上request.getRequestDispatcher("/upload.jsp").forward(request, response);return;}// TODO Auto-generated catch blocke.printStackTrace();}}}
index.jsp
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%><%String path = request.getContextPath();String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";%><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"><html> <head> <base href="<%=basePath%>"> <title>My JSP 'index.jsp' starting page</title> <meta http-equiv="pragma" content="no-cache"> <meta http-equiv="cache-control" content="no-cache"> <meta http-equiv="expires" content="0"> <meta http-equiv="keywords" content="keyword1,keyword2,keyword3"> <meta http-equiv="description" content="This is my page"> <!-- <link rel="stylesheet" type="text/css" href="styles.css"> --> </head> <body> <!--文件上传必须使用Post 提交,设置enctype(编码类型)="multipart/form-data" --> <form action="/demo/fileUploadServlet" method="post" enctype="multipart/form-data" > 上传者:<input type="text" name="username" /><br> 上传文件:<input type="file" name="name" /><br> <input type="submit" value="上传" /> </form> </body></html>
注意(报错情况分析):
针对不同的浏览器上传文件可能会出现这样的一个错误: 文件名,目录名,或卷标语法不正确
-
//获取上传的文件名(原始文件名) -
String name = fileItem.getName();
我们发现打印的这个信息就是 我们上传的文件名,但是我们的文件名应该只是 demo.txt
所以我们要切割 name 从其中拿到 demo.txt 字段
解决方法:
String name = fileItem.getName();- //我们先得到最后一个 \ 字符的位置,那么需要用到转义字符 \\ 转义就是 \
int lastIndexOf = name.lastIndexOf("\\");//切割字符串String substring = name.substring(lastIndexOf + 1);name = substring;
那么我们现在拿到的 name 就是
demo.txt 字段
这样方式也不会影响正常情况,拿到的name 就是 demo.txt
【2】web 文件下载
实现文件下载功能比较简单,直接使用Servlet类和输入/输出流实现即可。实现文件的下载,不仅需要指定文件的路径,还需要在HTTP协议中设置两个响应消息头:

注意点:
-
// 设置下载方式 dispositio 处理 -
response.setHeader("Content-Disposition", "attachment;filename=" -
+ URLEncoder.encode(filename, "UTF-8"));
这个需要设置正确,否则就不会出现 有下载框的 下载方式
不写这个 ,就是直接在页面显示打开。
——————————————————————————————————————————————————————————————————————————————————————
主要使用就是
IOUtils.copy(fileInputStream, response.getOutputStream());
把我们拿到的文件输入流 转化为 输出流 返回出去
package cn.edu.aynu.sushe;import java.io.FileInputStream;import java.io.IOException;import java.io.PrintWriter;import java.net.URLEncoder;import javax.servlet.ServletException;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import org.apache.commons.io.IOUtils;public class DowloadServlet extends HttpServlet {public void doGet(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {// 文件下载// 拿到我们的参数名String filename = request.getParameter("filename");// 处理一下文件名的中文乱码filename = new String(filename.getBytes("ISO-8859-1"), "UTF-8");// 拿到文件的真实目录(绝对路径)String path = this.getServletContext().getRealPath("/WEB-INF/downloads/" + filename);// 判断文件属于什么类型String mimeType = this.getServletContext().getMimeType(filename);// 设置内容的类型response.setContentType(mimeType);// 设置下载方式 dispositio 处理response.setHeader("Content-Disposition", "attachment;filename="+ URLEncoder.encode(filename, "UTF-8"));// 使用文件输入流 读取数据FileInputStream fileInputStream = new FileInputStream(path);// 使用输出流将文件保存到客户端// 使用 commons-io 流中的IOUtils.copy(fileInputStream, response.getOutputStream());fileInputStream.close();}public void doPost(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {this.doGet(request, response);}}
其中可能会出现的问题 :(文件名、目录名或卷标语法不正确)

出现问题是因为对中文乱码部分处理了两遍,原因就是在 tomcat的配置目录中的 server.xml () ( tomcat/conf/server.xml )
中对tomcat 端口号设置中多写了一个 URIEncoding="UTF-8" 然后我们在代码里也进行了中文乱码的处理。

设置这个参数就默认在通过get 方式的访问的时候,处理中文乱码
解决方法:
删除这个参数 或者 删除代码中的处理中文乱码的部分















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









