






作业:
1.mapreduce 工作流程 参数意义
2.FileInputFormat ?
3.写个去重MR
4.完成sort
5.工作流程总结 spli—map—reduce
6.InputSplit? 简介
mapreduce工作流程
转载自 http://blog.csdn.net/tanggao1314/
整个MapReduce的过程大致分为 Map–>Shuffle(排序)–>Combine(组合)–>Reduce
下面通过一个单词计数案例来理解各个过程
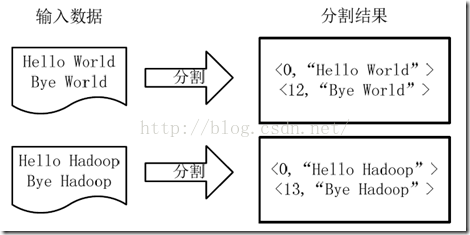
1)将文件拆分成splits(片),并将每个split按行分割形成key,value对,如图所示。这一步由MapReduce框架自动完成,其中偏移量即key值
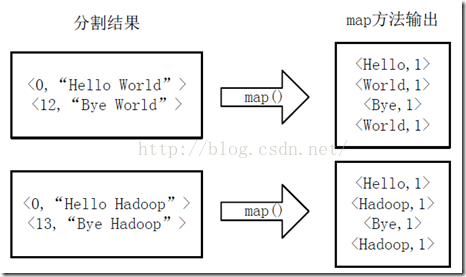
将分割好的key,value对交给用户定义的map方法进行处理,生成新的key,value对,如下图所示。
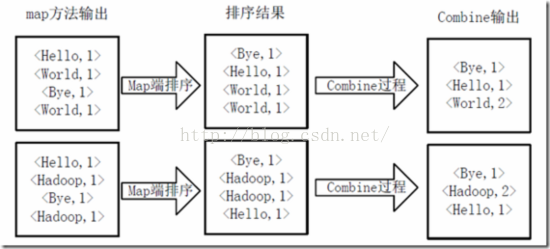
得到map方法输出的key,value对后,Mapper会将它们按照key值进行Shuffle(排序),并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如下图所示。
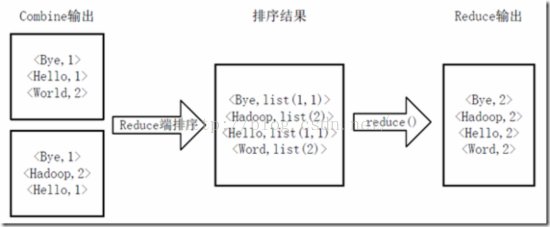
Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的key,value对,并作为WordCount的输出结果,如下图所示
参数说明
转载自董的博客
本文链接地址: http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-configurations-mapreduce/
MapReduce相关配置参数分为两部分,分别是JobHistory Server和应用程序参数,Job History可运行在一个独立节点上,而应用程序参数则可存放在mapred-site.xml中作为默认参数,也可以在提交应用程序时单独指定,注意,如果用户指定了参数,将覆盖掉默认参数。
以下这些参数全部在mapred-site.xml中设置。
1. MapReduce JobHistory相关配置参数
在JobHistory所在节点的mapred-site.xml中配置。
(1) mapreduce.jobhistory.address
参数解释:MapReduce JobHistory Server地址。
默认值: 0.0.0.0:10020
(2) mapreduce.jobhistory.webapp.address
参数解释:MapReduce JobHistory Server Web UI地址。
默认值: 0.0.0.0:19888
(3) mapreduce.jobhistory.intermediate-done-dir
参数解释:MapReduce作业产生的日志存放位置。
默认值: /mr-history/tmp
(4) mapreduce.jobhistory.done-dir
参数解释:MR JobHistory Server管理的日志的存放位置。
默认值: /mr-history/done
2. MapReduce作业配置参数
可在客户端的mapred-site.xml中配置,作为MapReduce作业的缺省配置参数。也可以在作业提交时,个性化指定这些参数。
参数名称 缺省值 说明
mapreduce.job.name 作业名称
mapreduce.job.priority NORMAL 作业优先级
yarn.app.mapreduce.am.resource.mb 1536 MR ApplicationMaster占用的内存量
yarn.app.mapreduce.am.resource.cpu-vcores 1 MR ApplicationMaster占用的虚拟CPU个数
mapreduce.am.max-attempts 2 MR ApplicationMaster最大失败尝试次数
mapreduce.map.memory.mb 1024 每个Map Task需要的内存量
mapreduce.map.cpu.vcores 1 每个Map Task需要的虚拟CPU个数
mapreduce.map.maxattempts 4 Map Task最大失败尝试次数
mapreduce.reduce.memory.mb 1024 每个Reduce Task需要的内存量
mapreduce.reduce.cpu.vcores 1 每个Reduce Task需要的虚拟CPU个数
mapreduce.reduce.maxattempts 4 Reduce Task最大失败尝试次数
mapreduce.map.speculative false 是否对Map Task启用推测执行机制
mapreduce.reduce.speculative false 是否对Reduce Task启用推测执行机制
mapreduce.job.queuename default 作业提交到的队列
mapreduce.task.io.sort.mb 100 任务内部排序缓冲区大小
mapreduce.map.sort.spill.percent 0.8 Map阶段溢写文件的阈值(排序缓冲区大小的百分比)
mapreduce.reduce.shuffle.parallelcopies 5 Reduce Task启动的并发拷贝数据的线程数目
注意,MRv2重新命名了MRv1中的所有配置参数,但兼容MRv1中的旧参数,只不过会打印一条警告日志提示用户参数过期。MapReduce新旧参数对照表可参考Java类org.apache.hadoop.mapreduce.util.ConfigUtil,举例如下:
过期参数名 新参数名
mapred.job.name mapreduce.job.name
mapred.job.priority mapreduce.job.priority
mapred.job.queue.name mapreduce.job.queuename
mapred.map.tasks.speculative.execution mapreduce.map.speculative
mapred.reduce.tasks.speculative.execution mapreduce.reduce.speculative
io.sort.factor mapreduce.task.io.sort.factor
io.sort.mb mapreduce.task.io.sort.mb
FileInputFormat
FileInputFormat(org.apache.hadoop.mapreduce.lib.input.FileInputFormat)是专门针对文件类型的数据源而设计的,也是一个抽象类,它提供两方面的作用:
(1)定义Job输入文件的静态方法;
(2)为输入文件形成切片的通用实现;
FileInputFormat提供了四个静态方法用于定义Job的输入文件路径:
public static void addInputPath(Job job, Path path)
public static void addInputPaths(Job job, String commaSeparatedPaths)
public static void setInputPaths(Job job, Path… inputPaths)
public static void setInputPaths(Job job, String commaSeparatedPaths)
addInputPath()、addInputPaths()用于“添加”一个(批)输入路径,可以重复被调用
addInputPath的每一次调用都会将输入路径(Path会被转换为字符串形式)与原有值以“,”分隔进行拼接(并不会覆盖原有值),并保存至Job Configuration的属性INPUT_DIR(mapreduce.input.fileinputformat.inputdir)中
而addInputPaths实际是对addInputPath的循环调用。
setInputPaths()实际是两个重载方法,用于“设置”一个(批)输入路径,该方法用于一次性调用,每一次调用都会覆盖之前的结果,
该方法的最后会替换Job Configuration属性INPUT_DIR(mapreduce.input.fileinputformat.inputdir)的原有值。
这里所说的输入路径可以代表一个文件,也可以代表一个目录(该目录下的所有文件将全部作为输入数据),而且可以在输入路径中使用通配符或者使用“,”进行多个输入路径的拼接。
注意:目录中的内容(子目录)不会被递归处理。实际上目录中应仅包含文件,如果目录中包含子目录,这些子目录会被当作文件处理,从而引发异常。如果我们不需要递归目录,我们可以通过File Pattern或者Filter(见后)告知
FileInputFormat仅仅选取指定目录中的文件;如果我们确实需要递归处理目录,则可以通过设置mapreduce.input.fileinputformat.input.dir.recursive为true实现。
InputSplit
输入分片(Input Split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
Hadoop 2.x默认的block大小是128MB,hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807
那么分片到底是多大呢?
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
我们再来看一下源码
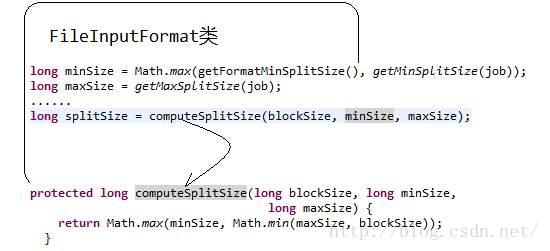
原文地址:http://blog.csdn.net/lylcore/article/details/9136555
一个split的大小是由goalSize, minSize, blockSize这三个值决定的。computeSplitSize的逻辑是,先从goalSize和blockSize两个值中选出最小的那个(比如一般不设置map数,这时blockSize为当前文件的块size,而goalSize是文件大小除以用户设置的map数得到的,如果没设置的话,默认是1)。
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还取决于其他的因素。
为了方便介绍,先来看几个名词:
block_size : hdfs的文件块大小,默认为64M,可以通过参数dfs.block.size设置
total_size : 输入文件整体的大小
input_file_num : 输入文件的个数
(1)默认map个数
如果不进行任何设置,默认的map个数是和blcok_size相关的。
default_num = total_size / block_size;
(2)期望大小
可以通过参数mapred.map.tasks来设置程序员期望的map个数,但是这个个数只有在大于default_num的时候,才会生效。
goal_num = mapred.map.tasks;
(3)设置处理的文件大小
可以通过mapred.min.split.size 设置每个task处理的文件大小,但是这个大小只有在大于block_size的时候才会生效。
split_size = max(mapred.min.split.size, block_size);
split_num = total_size / split_size;
(4)计算的map个数
compute_map_num = min(split_num, max(default_num, goal_num))
除了这些配置以外,mapreduce还要遵循一些原则。 mapreduce的每一个map处理的数据是不能跨越文件的,也就是说min_map_num >= input_file_num。 所以,最终的map个数应该为:
final_map_num = max(compute_map_num, input_file_num)
经过以上的分析,在设置map个数的时候,可以简单的总结为以下几点:
(1)如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。
(2)如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。
(3)如果输入中有很多小文件,依然想减少map个数,则需要将小文件merger为大文件,然后使用准则2。















 6498
6498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









