







第一周笔记 : 《Text Mining and Analytics》学习笔记——第一周
目录
组合关系
1.熵
首先看一下我们遇到的问题:我们需要知道什么单词会有跟eats一起出现的趋势呢?

先设可能会一起出现的词为W
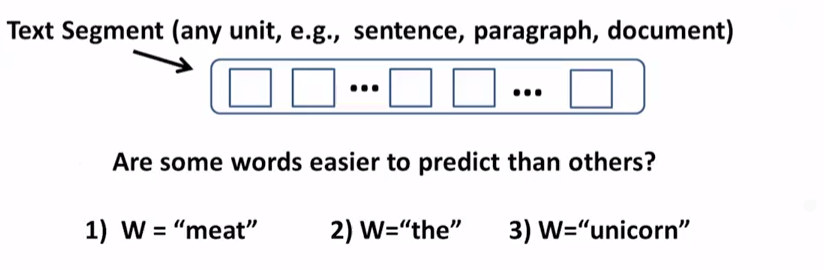
假设现在W有3个可选选项,分别为W=“meat”;W=“the”;W=“unicorn”。
我们可以发现有一些词是比较容易预测的:
the好像放哪都可以,所以容易预测很可能出现
而“unicorn”很不常见,也容易预测基本不会出现
而“meat”出现的频率介于两者之间,所以更难预测一些,可能出现也可能不出现
那我们到底要怎么衡量一个单词出现在某个短语中可能性呢?这里引入熵的概念来度量X的随机性。
熵的公式:
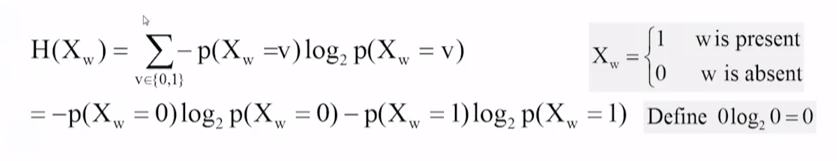
在一次事件中:
极端情况:当一旦此出现的概率为1或0的时候,它的熵为0
当单词的概率为1/2的时候,熵最大(当某件事情发生的概率为1/2时,足以说明这个事情很随机,比如抛硬币)。

对应到我们之前的问题中,其中“the”随处都可以看见,“unicorn”很不常见,所以他们的熵接近于0,而此时“meat”的对应的熵会明显高于其它两个单词。
现在我们可以得到熵越高词越难预测。
2.条件熵
上面是每一个单词单独出现的预测,那么当我们已知了eats已经存在于这个上下文中,那么其它单词的出现应该怎么预测呢?这里我们就引入了条件熵的概念。

那么条件熵就变为了:
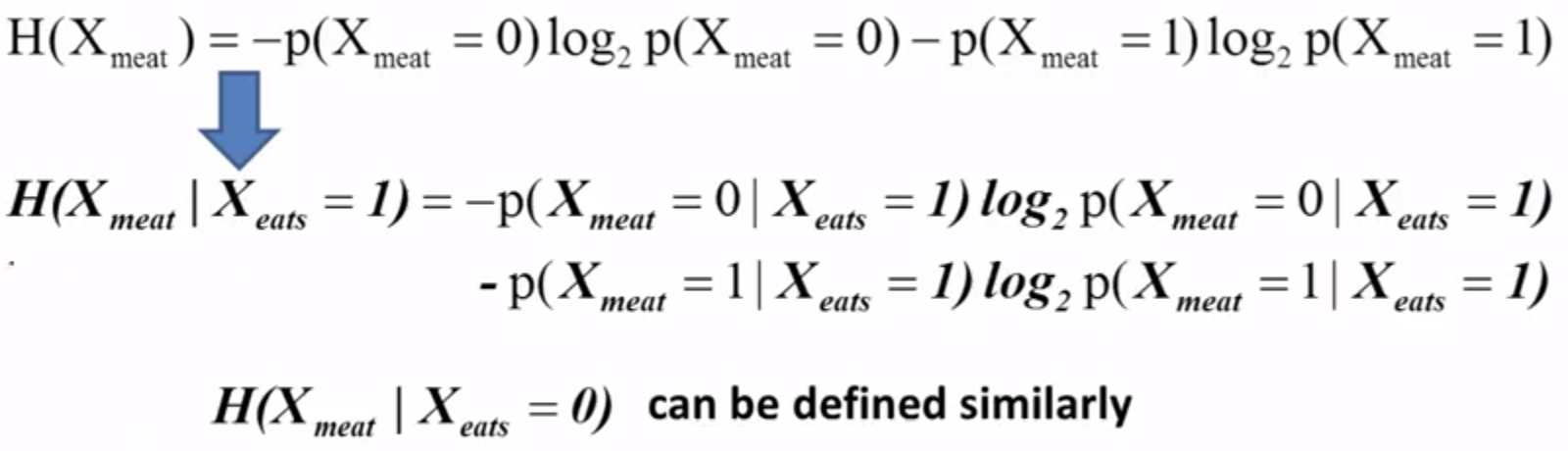
一般的 H(Xmeat)⩾H(Xmeat|Xeats) H ( X m e a t ) ⩾ H ( X m e a t | X e a t s ) ,因为当我们增加了信息后,信息的不确定性就会降低,就会变得相对容易预测。
条件熵的最小值:
H(Xmeat|Xmeat)=0 H ( X m e a t | X m e a t ) = 0 ,因为我们已经知道了meat的存在,它就没有不确定性了。H(Xmeat|Xthe) H ( X m e a t | X t h e ) , H(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2745
2745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









