




 本文介绍了一种基于矩阵分解的推荐算法,该算法通过分解用户-物品评分矩阵来预测未知评分,实现个性化推荐。文章详细解释了算法原理,并提供了一个C++实现的例子。
本文介绍了一种基于矩阵分解的推荐算法,该算法通过分解用户-物品评分矩阵来预测未知评分,实现个性化推荐。文章详细解释了算法原理,并提供了一个C++实现的例子。
转载自博客园,请直接链接原文查看(更详细更完整):
http://www.cnblogs.com/kobedeshow/p/3651833.html?utm_source=tuicool&utm_medium=referral
本文将要讨论基于矩阵分解的推荐算法,这一类型的算法通常会有很高的预测精度,也活跃于各大推荐系统竞赛上面,前段时间的百度电影推荐最终结果的前10名貌似都是把矩阵分解作为一个单模型,最后各种ensemble.
假设
N×M
维(
N
表示行数,
R≈P×QT=R^rij^=piTqj=∑i=1Kpikqkj
对于
P,QT
矩阵的理解,直观上,
P
矩阵是
对于如何衡量,我们分解的好坏呢,式子3,给出了衡量标准,也就是损失函数,平方项损失,最后的目标,就是每一个元素(非缺失值)的e(i,j)的总和 最小
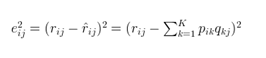
目前现在评分矩阵有了,损失函数也有了,该优化算法登场了,下面式子4是,基于梯度下降的优化算法,p,q里面的每个元素的更新方式
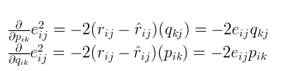
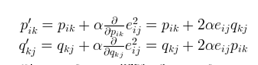
然而,机器学习算法都喜欢加一个正则项(控制过拟合),这里面对式子3稍作修改,得到如下式子5,beita (Mahout中的lambda)是正则参数
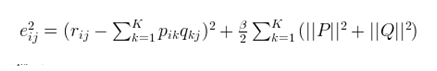
相应的p,q矩 阵各个元素的更新也换成了如下方式
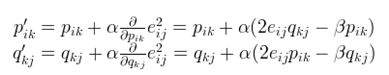
//C++算法:(对原文代码格式进行了调整,仅保留核心算法部分,完整的代码要查看原文,能直接运行出结果来)
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cmath>
using namespace std;
void matrix_factorization(double *R,double *P,double *Q,int N,int M,int K,int steps=5000,float alpha=0.0002,float beta=0.02)
{
for(int step =0;step<steps;++step){
for(int i=0;i<N;++i) {
for(int j=0;j<M;++j) {
if(R[i*M+j]>0) {
double error = R[i*M+j];
for(int k=0;k<K;++k)
error -= P[i*K+k]*Q[k*M+j];
for(int k=0;k<K;++k) {
P[i*K+k] += alpha * (2 * error * Q[k*M+j] - beta * P[i*K+k]);
Q[k*M+j] += alpha * (2 * error * P[i*K+k] - beta * Q[k*M+j]);
}
} //end if
} //end M
} //end N
double loss=0;
for(int i=0;i<N;++i) {
for(int j=0;j<M;++j) {
if(R[i*M+j]>0){
double error = 0;
for(int k=0;k<K;++k)
error += P[i*K+k]*Q[k*M+j];
loss += pow(R[i*M+j]-error,2);
for(int k=0;k<K;++k)
loss += (beta/2) * (pow(P[i*K+k],2) + pow(Q[k*M+j],2));
}//end for R
}//end for M
}//end for N
if(loss<0.001) break; //停止条件
}//end step
}//end function
R矩阵
5,3,0,1,
4,0,0,1,
1,1,0,5,
1,0,0,4,
0,1,5,4,
重构出来的R矩阵
4.9,2.9,5.8,1.0,
3.5,2.2,5.5,2.2,
0.9,0.9,5.8,5.2,
1.2,0.9,4.3,3.3,
1.3,1.0,4.9,3.9,
这样原来没有值的地方就全部有预测值了,是不是很神奇呢?!

















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









