






1、前序
上篇文章中(《架构设计:系统间通信(15)——服务治理与Dubbo 上篇》),我们以示例的方式讲解了阿里DUBBO服务治理框架基本使用。从这节开始我们将对DUBBO的主要模块的设计原理进行讲解,从而帮助读者理解DUBBO是如何工作的。(由于这个章节的内容比较多,包括了知识准备、DUBBO框架概述、DUBBO各模块分析,所以我将把内容切割成多篇文章)
2、基础知识准备
为了让读者更好理解下文讲解的内容,在开始讲解DUBBO框架主要模块前,我们先要介绍一些基础知识。这些基础知识将帮助读者更轻松的看懂后面的技术分析。这些基础知识包括了一个在DUBBO框架代理层工作的Javassist组件、一种在整个DUBBO框架各层中大量运用的创建型模式:工厂方法模式、以及几种在DUBBO各层使用的第三方框架。
2-1、动态编程:Javassist
Javassist是一个开源的分析、编辑和创建Java字节码的类库。是由东京工业大学的数学和计算机科学系的 Shigeru Chiba (千叶 滋)所创建的。它已加入了开放源代码JBoss 应用服务器项目,通过使用Javassist对字节码操作为JBoss实现动态”AOP”框架。(摘自百度百科)
说人话就是:在JAVA应用程序运行时,按照要求动态生成class并且完成实例化。我们都知道在JAVA语言中我们可以通过“反射”机制在JAVA应用程序运行时加载业已存在的class文件。但前提有两个:即这个class是已经在编译时存在的,另外这个class在JAVA-Classloader可以识别的路径上。
而Javassist组件给了我们一个新的选择,在编译期不需要有这个java文件的存在也不需要这个java文件编译好一个class。而是运行时再生成class。使用的代码示例如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
大家先猜猜,DUBBO用它干什么呢?提示:主要是DUBBO中RPC模块的“代理层”在用哦~~
2-2、设计模式:工厂方法模式
设计模式中有一种创建模型(23中设计模式,分为三大类:创建模型、结构模型和行为模型), 在这种创建模型下,我们通过A接口的工厂AFactory接口,创建任何一种特定环境下的A接口实现。
例如我们可以定义一个Router(路由服务),并且通过Router的RouterFactory抽象工厂,来统一任何一种路由的具体实现(无论是编辑脚本实现的路由、配置文件实现的路由,还是动态条件实现的路由),对外部调用者来说,它看到的都是“Router”这个接口服务。以下是典型的工厂方法模式的类图:
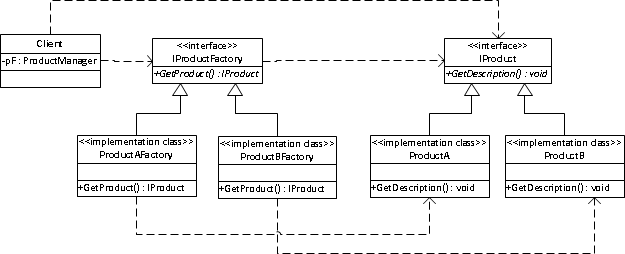
上图中,Client类在DUBBO框架中,代表了框架内的其他模块。工厂方法模式的优点在于对于某种形态的业务实现来说,都会有一个特定的具体对象工厂指向它;那么当需要添加一种新业务实现时,只需要添加这个业务接口的另外一个具体实现和指向这个实现的具体工厂:现在DUBBO支持的RPC协议层支持Dubbo、Thrift、RMI等,他们都有相应的创建工厂;如果后续DUBBO框架需要引入一种新的RPC协议层支持,只需要创建这个RPC协议的具体实现,和对应的创建工厂。已有的RPC协议支持不会受到任何影响,DUBBO框架中使用这个RPC协议模块的其他模块,由于使用的是Protocol接口,所以也不会感觉有任何的不同。
给出Client具体的使用方式(伪代码,我写得比较’快’,前提是我知道您已经理解抽象工厂模式的设计核心):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
很明显如果Client这样使用抽象工厂创建具体的IProduct实现就会出现一个谬论:Client必须知道现在的系统环境要么是conditionA要么是conditionB,也必须知道IProductFactory接口有两个实现,要么是ProductAFactory要么是ProductBFactory。
为了保证这些细节‘调用者不需要关心’,其中一种做法是将IProductFactory的实现细节隐藏到这个工厂方法模型的内部:将工厂接口抽象化,并且结合单例模式在内部完成实例化:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这样依赖AbstractProductFactory是创建ProductAFactory还是创建ProductBFactory的条件逻辑就不需要模块的调用者知晓了,模块的调用者也不会知道IProduct具体有两种业务实现。但是AbstractProductFactory还是没有逃脱厄运:在有新的业务环境、业务实现加入模块时,技术人员还是需要改写AbstractProductFactory中的getNewInstance实现。这里的本质原因是,您始终都要自己写‘new’关键字,既然要写‘new’关键字,您就必须知道所有的细节;
那么有没有方法,让AbstractProductFactory进一步拜托这个厄运呢(设计结构更加优化)?答案肯定是有的:使用spring的动态代理技术,彻底摆脱‘new’:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
以下是spring的配置信息
- 1
- 1
2-3、RPC名词:
现在业界主流的RPC技术在前文中已经提过一次。这里为了便于大家尽快找到节奏,再进行一次概括性的介绍(以下介绍摘自百度百科):
-
Apache Thrift:Thrift最初由facebook开发用做系统内各语言之间的RPC通信 。08年5月进入apache孵化器 。Apache Thrift通过自身独立的一套IDL语言支持多种语言之间的RPC方式的通信。
-
RMI:RMI是Java的一组拥护开发分布式应用程序的API。RMI使用Java语言接口定义了远程对象,它集合了Java序列化和Java远程方法协议(JavaRemote Method Protocol)。RMI具有RPC规则中典型的功能划分,是一种在Java语言构建的系统间进行远端调用的RPC框架。
-
Hessian:Hessian是一个轻量级的remoting onhttp工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
RPC框架的核心/次要结构要素,在我前面的一篇博文(《架构设计:系统间通信(10)——RPC的基本概念》)中已经详细介绍过。
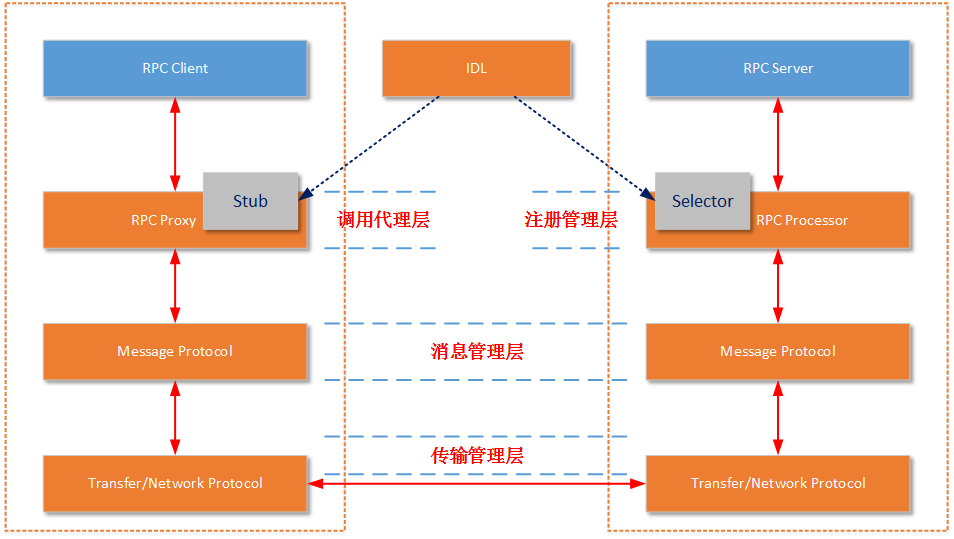
它们分别是:
-
服务管理层/注册管理层(Selector/Processor):存在于RPC服务端,由于服务器端某一个RPC接口的实现的特性(它并不知道自己是一个将要被RPC提供给第三方系统调用的服务)。所以在RPC框架中应该有一种“负责执行RPC接口实现”的角色。它负责了包括:管理RPC接口的注册、判断客户端的请求权限、控制接口实现类的执行在内的各种工作。
-
调用代理层(Stub/Proxy):RPC代理存在于客户端,因为要实现客户端对RPC框架“透明”调用,那么客户端不可能自行去管理消息格式、不可能自己去管理网络传输协议,也不可能自己去判断调用过程是否有异常。这一切工作在客户端都是交给RPC框架中的“代理”层来处理的。
-
消息层/序列化层(Message Protocol):RPC的消息管理层专门对网络传输所承载的消息信息进行编号和解码操作。目前流行的技术趋势是不同的RPC实现,为了加强自身框架的效率都有一套(或者几套)私有的消息格式。就像前文介绍过的RMI的JRMP协议、Thrift的私有消息协议等。
-
传输管理层(Transfer/Network Protocol):传输协议层负责管理RPC框架所使用的网络协议、网络IO模型。例如Hessian的传输协议基于HTTP(应用层协议);而Thrift的传输协议基于TCP(传输层协议)。传输层还需要统一RPC客户端和RPC服务端所使用的网络IO模型;
-
IDL语言:实际上IDL(接口定义语言)并不是RPC实现中所必须的。但是需要跨语言的RPC框架一定会有IDL部分的存在。这是因为要找到一个各种语言能够理解的消息结构、接口定义的描述形式。如果您的RPC实现没有考虑跨语言性,那么IDL部分就不是必须的。
2-4、网络框架层名词:
一部分读者对Netty、MINA、Grizzly这组技术名词和Thrift、RMI、Hessian这组技术名词傻傻分不清。最根本的原因是没有搞清楚系统网络通讯的基本原理,前者这组技术代表的是JAVA语言对网络IO模型的封装(参见这个系列文章的《架构设计:系统间通信(3)——IO通信模型和JAVA实践 上篇》、《架构设计:系统间通信(4)——IO通信模型和JAVA实践 中篇》、《架构设计:系统间通信(5)——IO通信模型和JAVA实践 下篇》)。
-
网络IO模型:网络IO模型是计算机IO技术的一个分支(磁盘IO模型我将会在下一个系列博文:存储系统中进行详细说明,计划明年上半年在这个系列博文结束后即刻推出)。目前包括的网络IO模型有:阻塞式同步IO、非阻塞式同步IO、多路复用IO和异步IO。
-
Netty和MINA:这两款网络IO模型的封装组件是由同一个技术人员主导完成的。其中Netty是由JBOSS提供的一个java开源框架。Netty和MINA一样,提供异步的、事件驱动的网络应用程序框架和工具(不且不仅仅限于此),用以快速开发高性能、高可靠性的网络服务器和客户端程序。
-
Grizzly:摘自Grizzly官网(https://grizzly.java.net/)
Writing scalable server applications in the Java™ programming language has always been difficult. Before the advent of the Java New I/O API (NIO), thread management issues made it impossible for a server to scale to thousands of users. The Grizzly NIO framework has been designed to help developers to take advantage of the Java™ NIO API. Grizzly’s goal is to help developers to build scalable and robust servers using NIO as well as offering extended framework components: Web Framework (HTTP/S), WebSocket, Comet, and more!
(接下文)














 3876
3876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









