






Hive简介
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
术语“大数据”是大型数据集,其中包括体积庞大,高速,以及各种由与日俱增的数据的集合。使用传统的数据管理系统,它是难以加工大型数据。因此,Apache软件基金会推出了一款名为Hadoop的解决大数据管理和处理难题的框架。
Zookeeper简介
Zookeeper 是为分布式应用程序提供高性能协调服务的工具集合,也是Google的Chubby一个开源的实现,是Hadoop 的分布式协调服务。它包含一个简单的原语集5,分布式应用程序可以基于它实现配置维护、命名服务、分布式同步、组服务等。Zookeeper可以用来保证数据在ZK集群之间的数据的事务性一致6。其中ZooKeeper提供通用的分布式锁服务7,用以协调分布式应用。
Zookeeper作为Hadoop项目中的一个子项目,是 Hadoop集群管理的一个必不可少的模块,它主要用来解决分布式应用中经常遇到的数据管理问题,如集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等。在Hadoop中,它管理Hadoop集群中的NameNode,还有在Hbase中Master Election、Server 之间状态同状步等。
Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型。
安装Zookeeper
- 在slave1,slave2,slave3上安装Zookeeper
yum install -y zookeeper-server- 3台主机分别创建/usr/lib/tmpfile.d/zk.conf:
d /var/run/zookeeper 0775 zookeeper zookeeper -- 创建/var/run/zookeeper
# systemd-tmpfiles --create- 分别在3台服务器上初始化ID(id=1,2,3)
# echo ID > /var/lib/zookeeper/myid配置zoo.cfg
- 在3台Zookeeper服务器上配置/etc/zookeeper/conf/zoo.cfg:
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888分别启动3台zookeeper
- 创建启动服务文件:
# cp /usr/hdp/2.6.1.0-129/zookeeper/usr/lib/systemd/system/zookeeper-service /usr/lib/systemd/system- 启动服务
# systemctl start zookeeper-server- 激活服务
# systemctl enable zookeeper-server安装hive2和mysql
- 安装hive2
# yum install -y hive2- 安装mysql
# yum install -y mysql-server- 安装mysql驱动
# rpm -ivh mysql-connector-java-5.1.37-1激活mysql驱动
- 为hive准备jdbc驱动
# cp ln -s /usr/share/java/mysql-connector-java.jar /usr/hdp/2.6.1.0-129/hive2/lib配置hive2
- /etc/hive/conf/hive-site.xml中添加配置项
| name | value |
|---|---|
| javax.jdo.option.ConnectionURL | jdbc.mysql://slave1:3306/metastor |
| javax.jdo.option.ConnectionDriverName | com.mysql.jdbc.Driver |
| javax.jdo.option.ConnectionUserName | hiveuser |
| javax.jdo.option.ConnectionPasswd | passwd |
| datanucleus.autoCreateSchema | false |
| datanucleus.fixedDatastore | true |
| datanucleus.autoStarMechanism | SchemaTable |
| hive.metastor.uris | thrift://< IP_of_Slave1>:9083 |
| hive.support.concurrency | true |
| hive.zookeeper.quorum | slave1,slave2,slave3 |
准备HDFS目录
- 清空可能遗留的垃圾文件
# su - hdfs
$ hadoop fs -rm -r /tmp/hive
$ hadoop fs -rm -r /user/hive- 创建hive数据仓库
$ hadoop fs -mkdri/tmp
$ hadoop fs -chmod 1777 /tmp
$ hadoop fs -mkdri -p /user/hive/warehouse
$ hadoop fs -chown -R hive:hive /user/hive
$ hadoop fs -chmod 1777 /user/hive/warehouse启动mysql服务器
- 在slave1上启动mysql
# systemctl start mysqld- 链接mysql服务器
$ mysql -u root -h localhost创建hive数据库账号
> create database metastore;
> use metastore;
> create user 'hiveuser'@'%' identified by 'passwd';
> revoke all privileges,grant option from 'hiveuser'@'%';
> grant selsect,insert,update,selsete,lock tables,exexute.create,alter on metastore.* to 'hiveuser'@'%'初始化metastore
- 清空可能出现的垃圾文件
# rm -rf /var/lib/hive/*
# rm -rf /var/lib/hive2/*
- 删除可能存在的冲突配置文件
# mv /etc/hive2/ /etc/hive2.bak
# cp /etc/hive/ /etc/hive2
- 在slave1上创建metastore
# schematool -dbType mysql -initSchema- 从mysql控制台上确认表成功
mysql> show tables启动hive server2
- 切换到hadoop
- 开启远程metastore服务
$ /...(hive2目录)/bin/hive --service metastore
$ /...(hive2目录)/bin/hiveserver2- 连接服务器
$ /...(hive2目录)/bin/beeline -u jdbc:hive2://slave1:10000 -n hive结果如下:
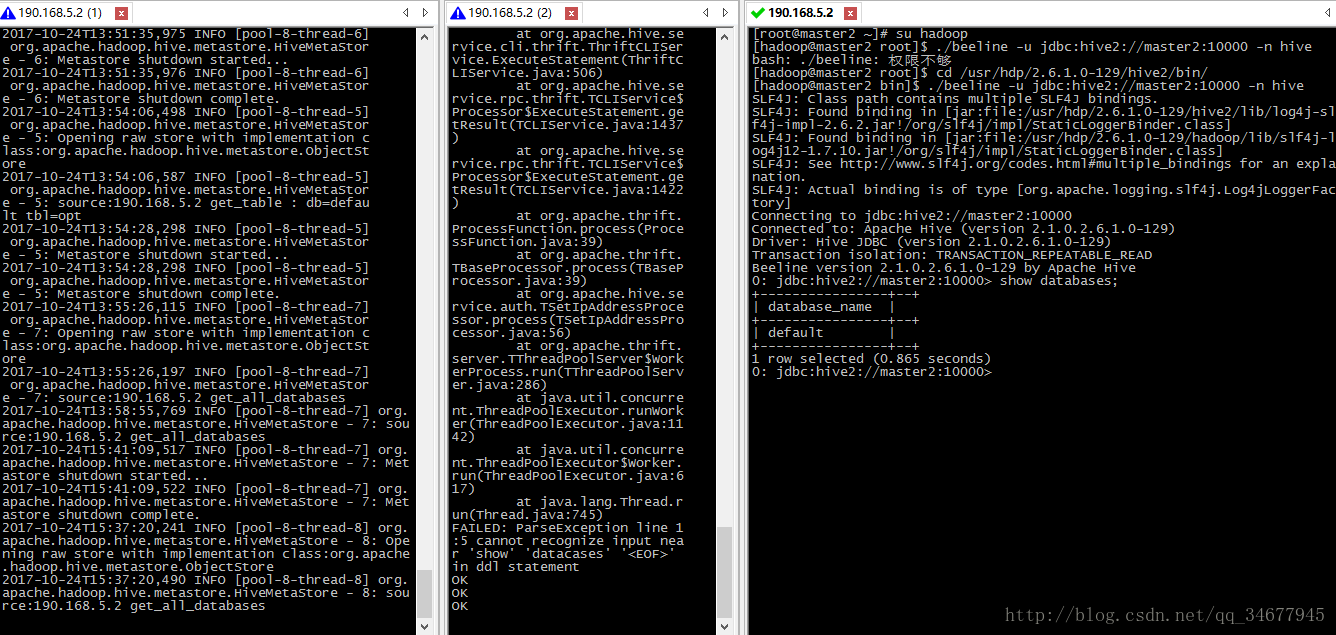
用到的知识














 787
787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









