






Hadoop集群搭建及ZooKeeper、Hbase、Hive配置
Hadoop集群搭建
| 主机名 | ip | NameNode | DataNode | Yarn | ZK | JournalNode |
|---|---|---|---|---|---|---|
| node02 | 172.29.66.129 | √ | √ | × | √ | √ |
| node03 | 172.29.66.130 | √ | √ | × | √ | √ |
| node04 | 172.29.66.131 | × | √ | √ | √ | √ |
NadeNode和SecondaryNameNode不能放在一起,Yarn的ResourceManager不能和NameNode、SecondaryNameNode放在一起,因为这三个都会占用大量资源,放在一起容易崩溃。
所有资源都可在百度网盘下载
链接: https://pan.baidu.com/s/1SkUfCurICy-RtxuOuiaZ-Q 提取码: dtga
1.模板虚拟机环境准备
将虚拟机IP设为静态,并进行配置
[root@node01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改为如下
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="e59bb0ad-2918-4de6-93fa-46bd94c0a474"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=172.29.66.128
GATEWAY=172.29.66.2
DNS1=172.29.66.2
配置模板虚拟机主机名称映射hosts文件
[root@node01 ~]# vim /etc/hosts
在末尾添加内容:
172.29.66.128 node01
172.29.66.129 node02
172.29.66.130 node03
172.29.66.131 node04
重启虚拟机
[root@node01 ~]# reboot
在Windows中打开C:\Windows\System32\drivers\etc路径,在hosts文件中添加如下内容:
172.29.66.128 node01
172.29.66.129 node02
172.29.66.130 node03
172.29.66.131 node04
安装epel-release
[root@node01 ~]# yum install -y epel-release
关闭防火墙,关闭防火墙开机自启
[root@node01 ~]# systemctl stop firewalld
[root@node01 ~]# systemctl disable firewalld.service
配置hadoop用户具有root权限
[root@node01 ~]# vim /etc/sudoers
hadoop配置如下:
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL
在/opt/下创建2个目录,并修改所有者和所在组
[hadoop@node01 opt]# mkdir module/ software/
[hadoop@node01 opt]# chown hadoop:hadoop module/ software/
卸载虚拟机自带JDK
[root@node01 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e –nodeps
重启虚拟机
[root@node01 ~]# reboot
模板虚拟机Node01的配置完成
2. 克隆虚拟机并配置网络
以Node01为模板虚拟机,克隆三台虚拟机,分别为:
Node02
Node03
Node04
每台虚拟机配置4G内存,4核处理器,20G硬盘

配置Node02的IP
[root@node02 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改:
IPADDR=192.168.10.102
修改Node02的主机名称
[root@node02 ~]# vim /etc/hostname
由node01改为:
node02
重启虚拟机
[root@node02 ~]# reboot
Node03、Node04操作步骤同上
完成操作后,使用xshell远程连接node02、node03、node04
3. JDK、Hadoop安装
使用xftp上传Hadoop和JDK至node02
解压JDK并指定目录
[hadoop@node02 ~]$ cd /opt/software/
[hadoop@node02 software]$ tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/module/
配置JDK环境变量
[hadoop@node02 ~]$ sudo vim /etc/profile.d/my_env.sh
添加
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_321
export PATH=$PATH:$JAVA_HOME/bin
使修改后的文件生效
[hadoop@node02 ~]$ source /etc/profile
测试JDK是否安装成功
[hadoop@node02 ~]$ java -version

解压Hadoop并指定目录
[hadoop@node02 ~]$ cd /opt/software/
[hadoop@node02 software]$ tar -zxvf hadoop-3.2.2.tar.gz -C /opt/module/
配置Hadoop环境变量
[hadoop@node02 ~]$ sudo vim /etc/profile.d/my_env.sh
在末尾添加
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
使修改后的文件生效
[hadoop@node02 ~]$ source /etc/profile
测试Hadoop是否安装成功
[hadoop@node02 ~]$ hadoop version
显示如下,安装成功:
Hadoop 3.2.2
Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932
Compiled by hexiaoqiao on 2021-01-03T09:26Z
Compiled with protoc 2.5.0
From source with checksum 5a8f564f46624254b27f6a33126ff4
This command was run using /opt/module/hadoop-3.2.2/share/hadoop/common/hadoop-common-3.2.2.jar
4. Hadoop完全分布式配置
在node02把node02的/opt/module/jdk1.8.0_321目录拷贝到node03
[hadoop@node02 opt]$ scp -r /opt/module/jdk1.8.0_321 hadoop@node03:/opt/module
在node03把node02的/opt/module/hadoop-3.2.2目录拷贝到node03
[hadoop@node03 ~]$ scp -r hadoop@node02:/opt/module/hadoop-3.2.2 /opt/module/
在node03把node02的/opt/module目录下的所有目录拷贝到node04
[hadoop@node03 ~]$ scp -r hadoop@node02:/opt/module/* hadoop@node04:/opt/module
编写集群分发脚本xsync
在node02的/home/hadoop下新建目录bin
[hadoop@node02 ~]$ mkdir /home/hadoop/bin
创建xsync脚本
[hadoop@node02 ~]$ vim /home/hadoop/bin/xsync
写入如下内容
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in node02 node03 node04
do
echo -e "\n==================== $host ===================="
#3. 遍历所有目录,逐个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exist!
fi
done
done
echo -e "\n"
使脚本 xsync 具有执行权限
[hadoop@node02 ~]$ cd bin/
[hadoop@node02 bin]$ chmod +x xsync
同步分发/home/hadoop/bin至node03、node04
[hadoop@node02 bin]$ cd
[hadoop@node02 ~]$ xsync bin/
可以在node03、node04上查看运行结果
[hadoop@node03 ~]$ ll bin/
[hadoop@node04 ~]$ ll bin/
分发环境变量
[hadoop@node02 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
在node03、node04上分别使修改后的文件生效
[hadoop@node03 ~]$ source /etc/profile
[hadoop@node04 ~]$ source /etc/profile
5.SSH免密登录配置
在node02上生成私钥和公钥
[hadoop@node02 ~]$ ssh-keygen -t rsa
在node02上将公钥拷贝到要免密登录的目标机器
[hadoop@node02 ~]$ ssh-copy-id node02
[hadoop@node02 ~]$ ssh-copy-id node03
[hadoop@node02 ~]$ ssh-copy-id node04
在node03、node04上同样进行以上步骤
在node02上切换至root用户
[hadoop@node02 ~]$ su
用root用户在node02上生成私钥和公钥
[root@node02 ~]# ssh-keygen -t rsa
用root用户在node02上将公钥拷贝到要免密登录的目标机器
[root@node02 ~]# ssh-copy-id node02
[root@node02 ~]# ssh-copy-id node03
[root@node02 ~]# ssh-copy-id node04
在node03、node04上同样进行以上步骤
6.集群配置
进入hadoop目录
[hadoop@node02 ~]$ cd /opt/module/hadoop-3.2.2/etc/hadoop/
配置core-site.xml
[hadoop@node02 ~]$ vim core-site.xml
在与之间添加内容:
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node02:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.2.2/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
配置hdfs-site.xml
[hadoop@node02 hadoop]$ vim hdfs-site.xml
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>node02:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node04:9868</value>
</property>
配置yarn-site.xml
[hadoop@node02 hadoop]$ vim yarn-site.xml
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node03</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node02:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为14天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>1209600</value>
</property>
配置mapred-site.xml
[hadoop@node02 hadoop]$ vim mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node02:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node02:19888</value>
</property>
分发配置文件
[hadoop@node02 hadoop]$ cd ..
[hadoop@node02 etc]$ xsync hadoop/
同步所有节点配置文件
[hadoop@node02 ~]$ xsync /opt/module/hadoop-3.2.2/etc
7.编写Hadoop集群脚本
编写Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
先转到hadoop的bin目录下:
[hadoop@node02 ~]$ cd /home/hadoop/bin/
[hadoop@node02 bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input!"
exit;
fi
case $1 in
"start")
echo -e "\n================= 启动 hadoop集群 ================="
echo " ------------------- 启动 hdfs --------------------"
ssh node02 "/opt/module/hadoop-3.2.2/sbin/start-dfs.sh"
echo " ------------------- 启动 yarn --------------------"
ssh node03 "/opt/module/hadoop-3.2.2/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh node02 "/opt/module/hadoop-3.2.2/bin/mapred --daemon start historyserver"
echo -e "\n"
;;
"stop")
echo -e "\n================= 关闭 hadoop集群 ================="
echo " --------------- 关闭 historyserver ---------------"
ssh node02 "/opt/module/hadoop-3.2.2/bin/mapred --daemon stop historyserver"
echo " ------------------- 关闭 yarn --------------------"
ssh node03 "/opt/module/hadoop-3.2.2/sbin/stop-yarn.sh"
echo " ------------------- 关闭 hdfs --------------------"
ssh node02 "/opt/module/hadoop-3.2.2/sbin/stop-dfs.sh"
echo -e "\n"
;;
*)
echo "Input Args Error!"
;;
esac
编写查看三台服务器Java进程脚本:jpsall
[hadoop@node02 bin]$ vim jpsall
#!/bin/bash
for host in node02 node03 node04
do
echo -e "\n=============== $host ==============="
ssh $host jps
done
echo -e "\n"
使脚本具有执行权限
[hadoop@node02 bin]$ chmod +x myhadoop.sh jpsall
分发脚本
[hadoop@node02 bin]$ cd ..
[hadoop@node02 ~]$ xsync bin/
配置workers
[hadoop@node02 ~]$ vim /opt/module/hadoop-3.2.2/etc/hadoop/workers
清除原有内容,写入:
node02
node03
node04
同步所有节点配置文件
[hadoop@node02 ~]$ xsync /opt/module/hadoop-3.2.2/etc
8.启动集群
集群第一次启动前,需要在node02节点格式化NameNode
[hadoop@node02 ~]$ hdfs namenode -format
启动集群(三台虚拟机任意一台都可以运行)
[hadoop@node02 ~]$ myhadoop.sh start
查看三台服务器Java进程
[hadoop@node02 ~]$ jpsall
停止集群
[hadoop@node02 ~]$ myhadoop.sh stop
ZooKeeper安装
zookeeper安装
上传apache-zookeeper-3.5.7-bin.tar.gz至node02
[hadoop@node02 ~]$ cd /opt/software/
解压
[hadoop@node02 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
修改文件夹名称
[hadoop@node02 ~]$ cd /opt/module/
[hadoop@node02 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
修改配置
[hadoop@node02 module]$ cd zookeeper-3.5.7/conf/
[hadoop@node02 conf]$ mv zoo_sample.cfg zoo.cfg
[hadoop@node02 conf]$ vim zoo.cfg
修改dataDir(数据存储路径)
dataDir=/opt/module/zookeeper-3.5.7/zkData
在末尾添加
server.2=node02:2888:3888
server.3=node03:2888:3888
server.4=node04:2888:3888
创建文件夹
[hadoop@node02 conf]$ cd ..
[hadoop@node02 zookeeper-3.5.7]$ mkdir zkData
在zkData下创建myid文件(文件名不可更换)
[hadoop@node02 zookeeper-3.5.7]$ cd zkData/
[hadoop@node02 zkData]$ vim myid
文件中仅写入以下内容:(不可含有空行和空格,只能有数字2)
2
将zookeeper分发至node03、node04
[hadoop@node02 zookeeper-3.5.7]$ xsync /opt/module/zookeeper-3.5.7/
xsync同步脚本见上文内容,没有的可以用以下命令:
[hadoop@node02 zookeeper-3.5.7]$ scp -r /opt/module/zookeeper-3.5.7/ hadoop@node03:/opt/module
[hadoop@node02 zookeeper-3.5.7]$ scp -r /opt/module/zookeeper-3.5.7/ hadoop@node04:/opt/module
修改node03、node04的myid文件内容
[hadoop@node03 ~]$ vim /opt/module/zookeeper-3.5.7/zkData/myid
将数字2分别改为
3
4
编写脚本(与上文hadoop脚本过程一致):zk.sh
zk.sh(zookeeper启动、关闭、查看状态)
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input No Args!"
exit;
fi
case $1 in
"start")
for i in node02 node03 node04
do
echo -e "\n------------ zookeeper $i 启动 ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
echo -e "\n"
;;
"stop")
for i in node02 node03 node04
do
echo -e "\n------------ zookeeper $i 停止 ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
echo -e "\n"
;;
"status")
for i in node02 node03 node04
do
echo -e "\n------------ zookeeper $i 状态 ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
echo -e "\n"
;;
*)
echo "Input Args Error!"
;;
esac
脚本用法:
在任意一台机器的任意位置,输入:
zk.sh start 启动zookeeper
zk.sh stop 关闭zookeeper
zk.sh status 查看zookeeper状态
给脚本赋予可执行权限,分发脚本至node03、node04
[hadoop@node02 bin]$ chmod 777 zk.sh
[hadoop@node02 bin]$ xsync zk.sh
zookeeper安装结束
脚本用法:
在任意一台机器的任意位置,输入:
zk.sh start 启动zookeeper
zk.sh stop 关闭zookeeper
zk.sh status 查看zookeeper状态
hbs.sh start 启动hbase
hbs.sh stop 关闭hbase
all.sh start 启动hadoop集群、启动zookeeper、启动hbase、显示进程
all.sh stop 关闭hbase、关闭zookeeper、关闭hadoop集群、显示进程
hbase安装
启动hadoop集群
脚本见hadoop集群搭建,也可自行手动启动集群
[hadoop@node02 ~]$ myhadoop.sh start
启动zookeeper
脚本见本文档zookeeper安装
[hadoop@node02 ~]$ zk.sh start
上传hbase-2.0.5-bin.tar.gz至node02
[hadoop@node02 ~]$ cd /opt/software/
解压
[hadoop@node02 software]$ tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module/
配置hbase环境变量
[hadoop@node02 ~]$ sudo vim /etc/profile.d/my_env.sh
添加内容:
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.0.5
export PATH=$PATH:$HBASE_HOME/bin
修改hbase-env.sh
[hadoop@node02 ~]$ cd /opt/module/hbase-2.0.5/conf/
[hadoop@node02 conf]$ vim hbase-env.sh
写入,或去掉#并改为:
export HBASE_MANAGES_ZK=false
修改hbase-site.xml
[hadoop@node02 conf]$ vim hbase-site.xml
修改为
注意更改主机名、目录名,注意hdfs端口号(hadoop集群与我相同无需更改端口号)
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node02:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node02,node03,node04</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.5.7/zkData</value>
</property>
</configuration>
修改regionservers
[hadoop@node02 conf]$ vim regionservers
改为你对应的主机名
node02
node03
node04
分别在node02、node03、node04上删除如下jar包
[hadoop@node02 ~]$ rm -rf /opt/module/hbase-2.0.5/lib/slf4j-log4j12-1.7.25.jar
配置高可用
[hadoop@node02 ~]$ cd /opt/module/hbase-2.0.5/conf/
[hadoop@node02 conf]$ vim backup-masters
写入
node03
将hbase分发至node03、node04
[hadoop@node02 hbase-2.0.5]$ xsync /opt/module/hbase-2.0.5/
编写脚本(与上文hadoop脚本过程一致):hbs.sh all.sh
hbs.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input No Args!"
exit;
fi
case $1 in
"start")
echo -e "\n================= 启动 hbase ================="
ssh node02 "/opt/module/hbase-2.0.5/bin/start-hbase.sh"
echo -e "\n"
;;
"stop")
echo -e "\n================= 关闭 hbase ================="
ssh node02 "/opt/module/hbase-2.0.5/bin/stop-hbase.sh"
echo -e "\n"
;;
*)
echo "Input Args Error!"
;;
esac
all.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input No Args!"
exit;
fi
case $1 in
"start")
echo -e "\n\n================= 1. 启动 hadoop集群 ================="
echo " ------------------- 启动 hdfs --------------------"
ssh node02 "/opt/module/hadoop-3.2.2/sbin/start-dfs.sh"
echo " ------------------- 启动 yarn --------------------"
ssh node03 "/opt/module/hadoop-3.2.2/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh node02 "/opt/module/hadoop-3.2.2/bin/mapred --daemon start historyserver"
sleep 1
echo -e "\n\n================= 2. 启动 zookeeper ================="
sleep 1
for i in node02 node03 node04
do
echo -e "\n------------ zookeeper $i 启动 ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
echo -e "\n\n=================== 3. 启动 hbase ===================="
sleep 1
ssh node02 "/opt/module/hbase-2.0.5/bin/start-hbase.sh"
echo -e "\n"
for host in node02 node03 node04
do
echo -e "\n=============== $host ==============="
ssh $host jps
done
echo -e "\n"
;;
"stop")
echo -e "\n\n=================== 1. 关闭 hbase ===================="
ssh node02 "/opt/module/hbase-2.0.5/bin/stop-hbase.sh"
echo -e "\n\n================= 2. 关闭 zookeeper ================="
for i in node02 node03 node04
do
echo -e "\n------------ zookeeper $i 停止 ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
echo -e "\n\n================= 3. 关闭 hadoop集群 ================="
echo " --------------- 关闭 historyserver ---------------"
ssh node02 "/opt/module/hadoop-3.2.2/bin/mapred --daemon stop historyserver"
echo " ------------------- 关闭 yarn --------------------"
ssh node03 "/opt/module/hadoop-3.2.2/sbin/stop-yarn.sh"
echo " ------------------- 关闭 hdfs --------------------"
ssh node02 "/opt/module/hadoop-3.2.2/sbin/stop-dfs.sh"
echo -e "\n"
for host in node02 node03 node04
do
echo -e "\n=============== $host ==============="
ssh $host jps
done
echo -e "\n"
;;
*)
echo "Input Args Error!"
;;
esac
启动hbase(需要先启动zookeeper)
脚本用法:
在任意一台机器的任意位置,输入:
hbs.sh start 启动hbase
hbs.sh stop 关闭hbase
all.sh start 启动hadoop集群、启动zookeeper、启动hbase、显示进程
all.sh stop 关闭hbase、关闭zookeeper、关闭hadoop集群、显示进程
查看hbase网页端,启动后可以在浏览器里输入node03:16010
hdfs网页端为node02:9870
yarn网页端为node03:8088
Hive安装
1. Hive安装与配置
进入/opt/software/目录
[hadoop@node02 ~]$ cd /opt/software/
上传apache-hive-3.1.2-bin.tar.gz
上传mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
上传mysql-connector-java-5.1.37.jar
解压apache-hive-3.1.2-bin.tar.gz
[hadoop@node02 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
修改目录名称
[hadoop@node02 software]$ mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive-3.1.2
配置hive环境变量
[hadoop@node02 software]$ sudo vim /etc/profile.d/my_env.sh
在末尾添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
使环境变量的修改生效
[hadoop@node02 software]$ source /etc/profile
删除冲突jar包
[hadoop@node02 software]$ rm /opt/module/hive-3.1.2/lib/log4j-slf4j-impl-2.10.0.jar
使用脚本启动hadoop集群
[hadoop@node02 software]$ myhadoop.sh start
初始化元数据库
[hadoop@node02 software]$ cd ../module/hive-3.1.2/bin/
[hadoop@node02 bin]$ schematool -dbType derby -initSchema
启动hive
[hadoop@node02 bin]$ hive
退出hive
hive> exit;
2. MySQL安装与配置
(MySQL文件已上传)
查看是否已安装MySQL
[hadoop@node02 ~]$ rpm -qa|grep mariadb
若已安装,需要卸载MySQL
[hadoop@node02 ~]$ sudo rpm -e --nodeps mariadb-libs
进入/opt/software/目录
[hadoop@node02 ~]$ cd /opt/software/
解压mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
[hadoop@node02 software]$ tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
执行命令
[hadoop@node02 software]$ sudo yum install -y libaio
如果安装成功,或者显示以下内容,即可继续安装步骤:
软件包 libaio-0.3.109-13.el7.x86_64 已安装并且是最新版本
无须任何处理
安装,依次输入以下5条命令
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
初始化数据库
[hadoop@node02 software]$ sudo mysqld --initialize --user=mysql
查看临时密码
[hadoop@node02 software]$ sudo cat /var/log/mysqld.log
将临时密码复制,或者暂时存到某处(一定要保存好)
启动MySQL
[hadoop@node02 software]$ sudo systemctl start mysqld
登录
[hadoop@node02 software]$ mysql -uroot -p
输入临时密码
Enter password: 临时密码
登陆成功后,修改密码为000000
mysql> set password = password("000000");
使root允许任意ip连接
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
退出MySQL
mysql> exit;
拷贝MySQL的JDBC驱动至hive-3.1.2下的lib/
[hadoop@node02 software]$ cp /opt/software/mysql-connector-java-5.1.37.jar /opt/module/hive-3.1.2/lib/
编写配置文件hive-site.xml
[hadoop@node02 software]$ cd /opt/module/hive-3.1.2/conf/
[hadoop@node02 conf]$ vim hive-site.xml
输入前,注意修改主机名
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node02:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node02:9083</value>
</property>
<!-- 指定hiveserver2连接的主机名 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node02</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
登录MySQL,输入密码
[hadoop@node02 ~]$ mysql -uroot -p
新建hive元数据库
mysql> create database metastore;
mysql> exit;
初始化hive元数据库
[hadoop@node02 ~]$ schematool -initSchema -dbType mysql -verbose
启动hive
[hadoop@node02 ~]$ hive
退出hive
hive> exit;
3. hive服务启动脚本
进入home目录下的bin目录
[hadoop@node02 ~]$ cd bin/
[hadoop@node02 ~]$ vim hvservice.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input No Args!"
echo "请输入 $(basename $0) start/stop/restart/status"
exit;
fi
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 3
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2 服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo "Input Args Error!"
echo "请输入 $(basename $0) start/stop/restart/status"
;;
esac
修改权限
[hadoop@node02 bin]$ chmod 777 hvservice.sh
脚本使用方法:
hvservice.sh start或stop或restart(重启)或status(查看状态)
启动后需要等待一段时间才可以查看状态
踩过的坑
1.Hadoop-2.x和Hadoop-3.x的命令格式不一样。
2.ResourceManager不要和NameNode、SecondaryNameNode装在一起,因为三者都需要占用大量的资源。
3.对于Hadoop里面的配置信息,不同的版本有不同的修改要求,要根据自己虚拟机的具体配置来改写hdfs-site.xml、yarn-site.xml、core-site.xml、mapred-site.xml的信息,不然开启Hadoop时,会出现不同程度的错误,如:NameNode没有开启或者整个yarn都没有开启。
4.分发文件命令最好不用 scp,用rsync -av 比较好,有条件可以参考尚硅谷的视频,编写一个xsync脚本,这样就不需要重复使用scp命令。
心路历程
花了三天时间,前前后后搭建了5、6次,yarn始终启动不起来,根据csdn上面的文章来修改Hadoop的配置信息,结果出了更多的错误,连NameNode和SecondaryNameNode都没了。没办法,查看了日志文件,还是没找出来问题在哪,最后都是直接删掉整个Hadoop文件,重新配置Hadoop环境。(绷不住了~~)
经过不懈努力终于搭建成功啦(~哈哈哈哈)
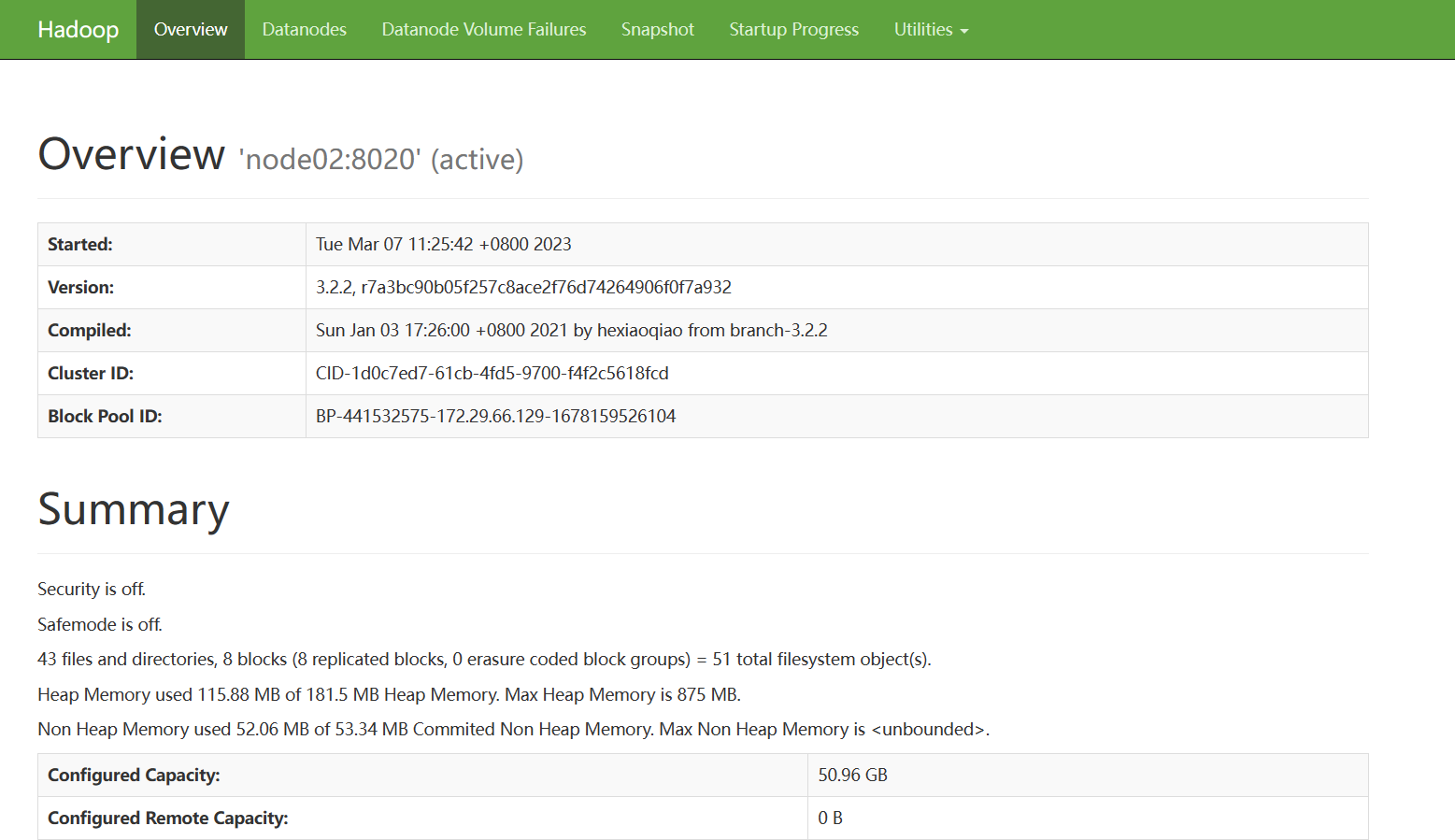
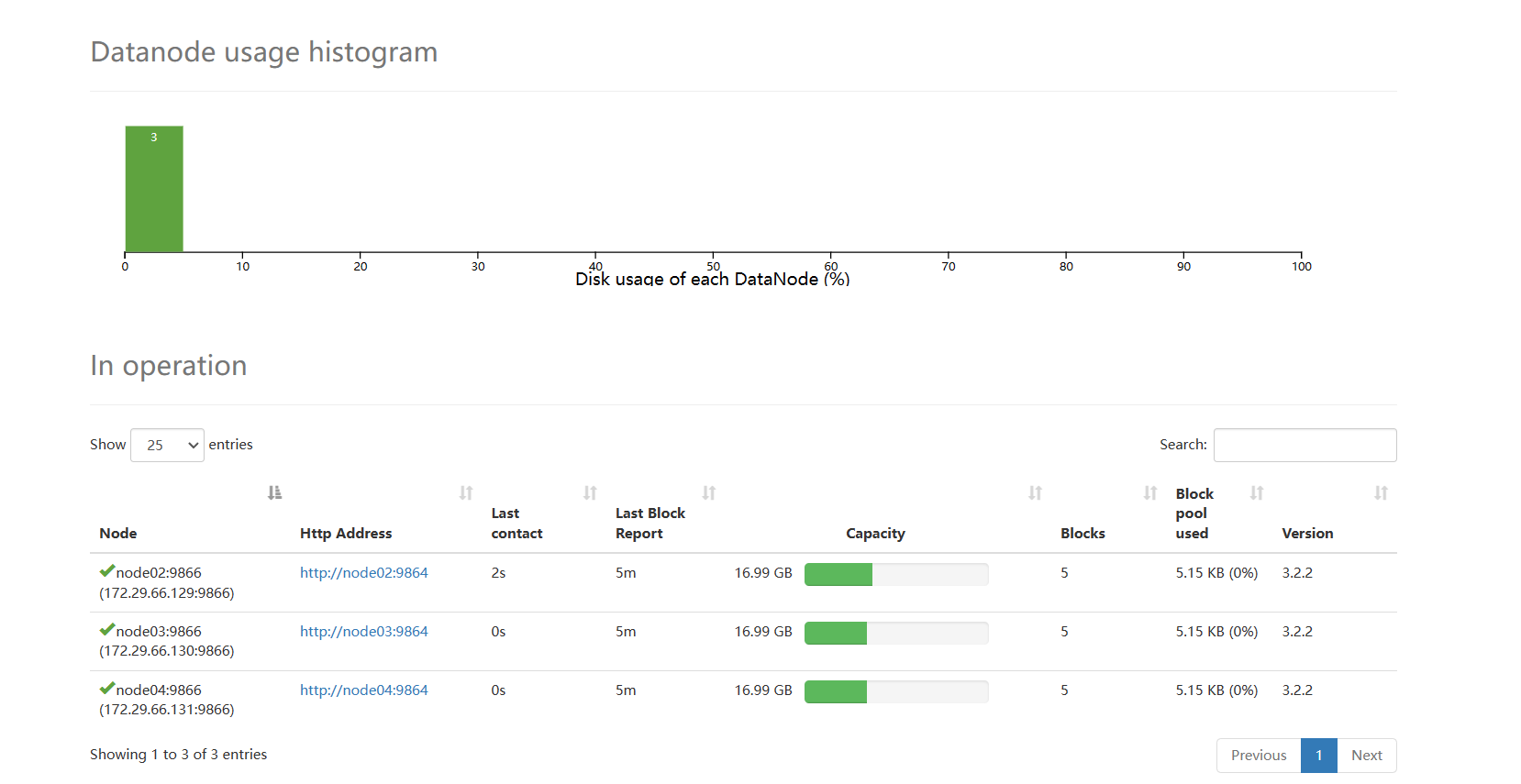
Hadoop-Web页面:node02:9870
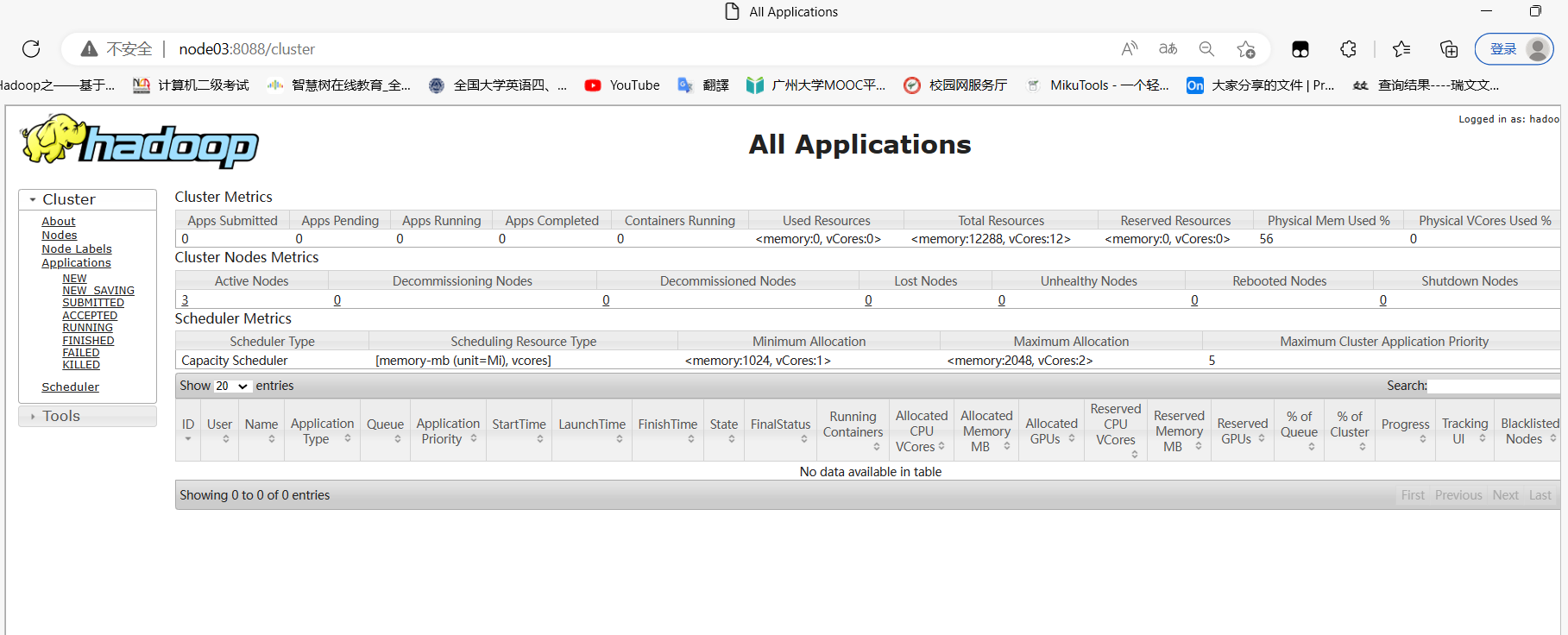
yarn-Web页面:node03:8088
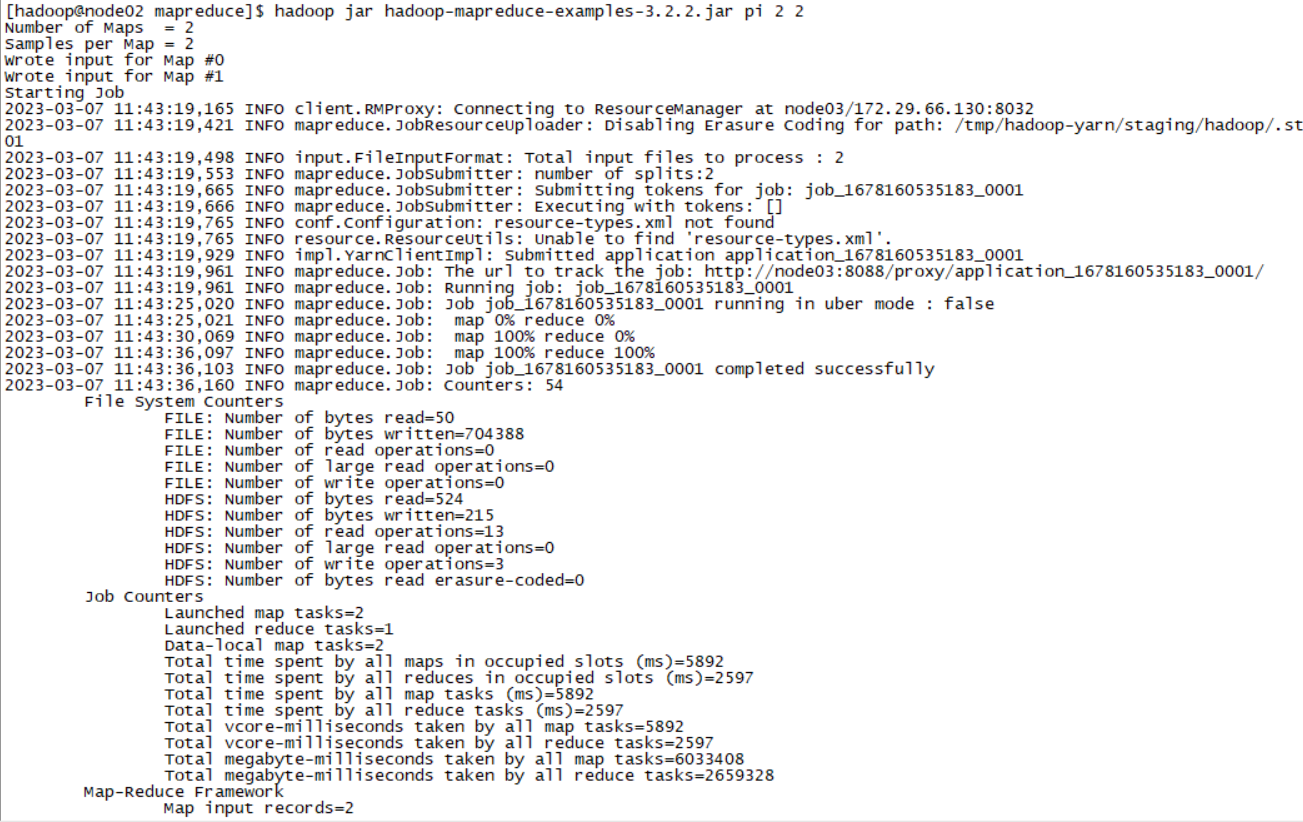
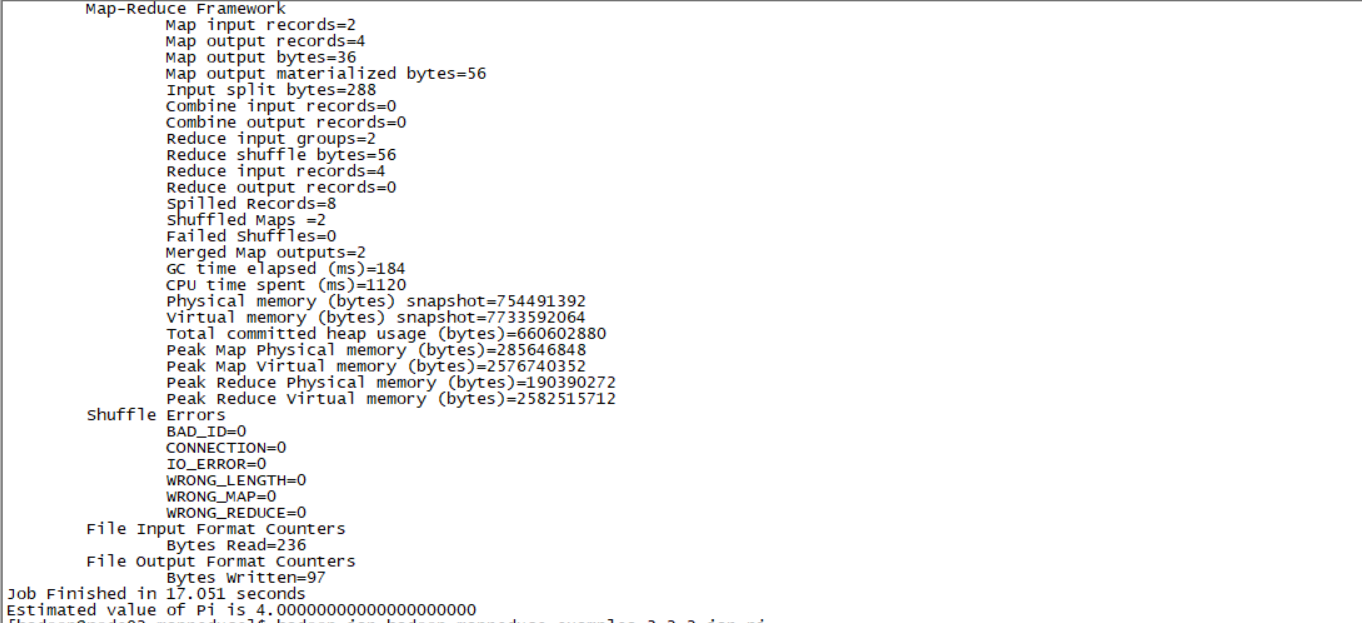
mapreduce-example运行成功
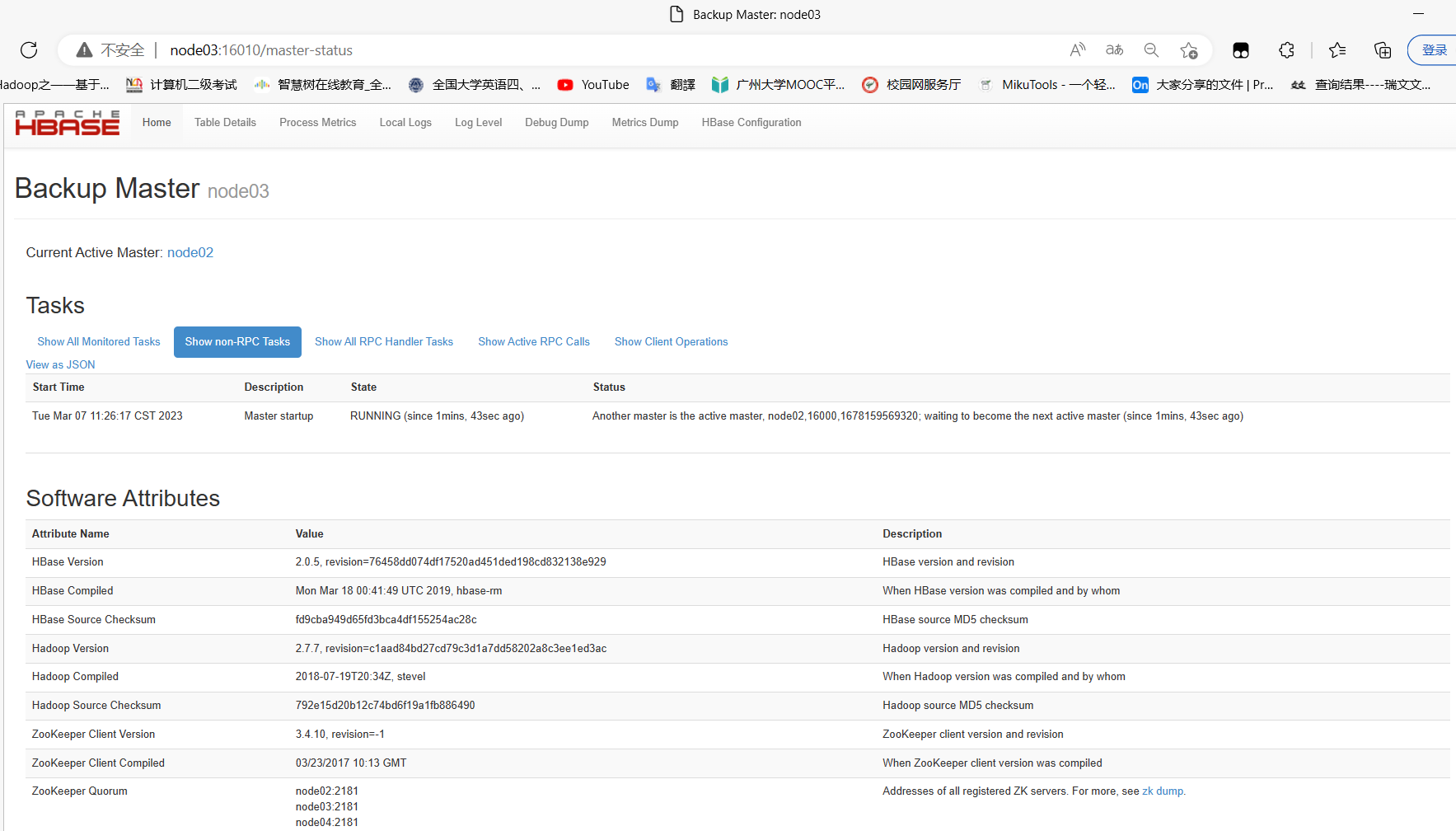
hbase-Web页面:node03:16010
Hive搭建(踩坑)
对hive进习初始化时,报错了:Exception in thread “main“ java.lang.NoSuchMethodError: com.google.common.base.
原因:hadoop和hive的两个guava.jar版本不一致
解决方案:删除掉hive的guava.jar,然后复制Hadoop的guava.jar到hive的lib目录下

最终成功进入hive!!!
tart
;;
“stop”)
hive_stop
;;
“restart”)
hive_stop
sleep 3
hive_start
;;
“status”)
check_process HiveMetastore 9083 >/dev/null && echo “Metastore服务运行正常” || echo “Metastore服务运行异常”
check_process HiveServer2 10000 >/dev/null && echo “HiveServer2 服务运行正常” || echo “HiveServer2服务运行异常”
;;
*)
echo “Input Args Error!”
echo “请输入 $(basename $0) start/stop/restart/status”
;;
esac
修改权限
```shell
[hadoop@node02 bin]$ chmod 777 hvservice.sh
脚本使用方法:
hvservice.sh start或stop或restart(重启)或status(查看状态)
启动后需要等待一段时间才可以查看状态
踩过的坑
1.Hadoop-2.x和Hadoop-3.x的命令格式不一样。
2.ResourceManager不要和NameNode、SecondaryNameNode装在一起,因为三者都需要占用大量的资源。
3.对于Hadoop里面的配置信息,不同的版本有不同的修改要求,要根据自己虚拟机的具体配置来改写hdfs-site.xml、yarn-site.xml、core-site.xml、mapred-site.xml的信息,不然开启Hadoop时,会出现不同程度的错误,如:NameNode没有开启或者整个yarn都没有开启。
4.分发文件命令最好不用 scp,用rsync -av 比较好,有条件可以参考尚硅谷的视频,编写一个xsync脚本,这样就不需要重复使用scp命令。
心路历程
花了三天时间,前前后后搭建了5、6次,yarn始终启动不起来,根据csdn上面的文章来修改Hadoop的配置信息,结果出了更多的错误,连NameNode和SecondaryNameNode都没了。没办法,查看了日志文件,还是没找出来问题在哪,最后都是直接删掉整个Hadoop文件,重新配置Hadoop环境。(绷不住了~~)
经过不懈努力终于搭建成功啦(~哈哈哈哈)
Hadoop-Web页面:node02:9870
[外链图片转存中…(img-SUKQrL2s-1681640446718)]
[外链图片转存中…(img-zl6oJZwi-1681640446719)]
yarn-Web页面:node03:8088
[外链图片转存中…(img-TsgIaa3p-1681640446719)]
mapreduce-example运行成功
[外链图片转存中…(img-vZRusthZ-1681640446719)][外链图片转存中…(img-qowyGENU-1681640446720)]
hbase-Web页面:node03:16010
[外链图片转存中…(img-g0f3uWv3-1681640446720)]
Hive搭建(踩坑)
对hive进习初始化时,报错了:Exception in thread “main“ java.lang.NoSuchMethodError: com.google.common.base.
原因:hadoop和hive的两个guava.jar版本不一致
解决方案:删除掉hive的guava.jar,然后复制Hadoop的guava.jar到hive的lib目录下
[外链图片转存中…(img-UdsCRoWd-1681640446720)]
最终成功进入hive!!!
















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









