







1.下载Hive安装包apache-hive-1.2.1-bin.tar.gz
2.解压安装包,并移动到要安装的路径下
sudo tar -zxvf apache-hive-1.2.1-bin.tar.gz
sudo mv -r hive1.2.1 /usr/local/
3.配置hive环境变量
vi /etc/profile 添加环境变量值
export HIVE_HOME=/home/likehua/hive/hive-0.12.0
export PATH = $HIVE_HOME/bin:$PATH
source /etc/profile 使修改的环境变量立即生效
4.进入解压后的hive目录,进入conf
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
hive的配置:
配置hive-env.sh文件:
(1)添加hadoop_home路径:将export HADOOP_HOME前面的‘#’号去掉,
并让它指向您所安装Hadoop的目录 (就是切换到这个目录下有hadoop的conf,lib,bin 等文件夹的目录),(mine:HADOOP_HOME=/usr/local/hadoop)
其实在安装hive时需要指定HADOOP_HOME的原理基本上与在安装Hadoop时需要指定JAVA_HOME的原理是相类似的。Hadoop需要Java作支撑,而hive
需要hadoop作为支撑。
(2)将export HIVE_CONF_DIR=/usr/local/hive1.2.1/conf,并且把‘#’号去掉
(3)将export HIVE_AUX_JARS_PATH=/usr/local/hive1.2.1/lib,并且把‘#’号去掉
保存,用source /hive-env.sh(生效文件)
在修改之前,要相应的创建目录,以便与配置文件中的路径相对应,否则在运行hive时会报错的。
mkdir -p /usr/local/hive1.2.1/warehouse
mkdir -p /usr/local/hive1.2.1/tmp
mkdir -p /usr/local/hive1.2.1/log
进入hive安装目录下的conf文件夹下,配置hive-site.xml文件
其中有三处需要修改:
搜索“/hive.metastore.warehouse.dir”
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/local/hive1.2.1/warehouse</value>
</property>
这个是设定数据目录
-------------------------------------
<property>
<name>hive.exec.scratchdir</name>
<value>/usr/local/hive1.2.1/tmp</value>
</property>
这个是设定临时文件目录
--------------------------------------
注://这个在笔者的文件中没有,可以自己添加
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive1.2.1/log</value>
</property>
这个是用于存放hive相关日志的目录,修改的这些目录都是上一步中创建的文件夹目录
其余的不用修改。
到此,hive-site.xml文件修改完成。
然后在conf文件夹下,cp hive-log4j.properties.template hive-log4j.proprties
打开hive-log4j.proprties文件,sudo gedit hive-log4j.proprties
寻找hive.log.dir=
这个是当hive运行时,相应的日志文档存储到什么地方
(mine:hive.log.dir=/usr/local/hive1.2.1/log/${user.name})
hive.log.file=hive.log
这个是hive日志文件的名字是什么
默认的就可以,只要您能认出是日志就好
只有一个比较重要的需要修改一下,否则会报错。
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
如果没有修改的话会出现:
WARNING: org.apache.hadoop.metrics.EventCounter is deprecated.
please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
(只要按照警告提示修改即可)。
至此,hive-log4j.proprties文件修改完成。
这是在derby模式下的hive的配置,完成。
在hive目录下的bin目录下,执行hive可以开启hive。
hadoop@schpc:/usr/local/hive1.2.1$ bin/hive
结果显示(如下错误):
16/05/17 10:48:15 WARN conf.HiveConf: HiveConf of name hive.exec.scratdir does not exist
Logging initialized using configuration in file:/usr/local/hive1.2.1/conf/hive-log4j.properties
Exception in thread "main" java.lang.RuntimeException: java.lang.IllegalArgumentException: java.NET.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.IllegalArgumentException: java.Net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at org.apache.hadoop.fs.Path.initialize(Path.java:206)
at org.apache.hadoop.fs.Path.<init>(Path.java:172)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:563)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:508)
... 8 more
Caused by: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at java.net.URI.checkPath(URI.java:1823)
at java.net.URI.<init>(URI.java:745)
at org.apache.hadoop.fs.Path.initialize(Path.java:203)
... 11 more
错误原因, ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D at org.apache.hadoop.fs.Path.initialize(Path.java:206)路径问题,只要把此处的相对路径改成
绝对路径就可以了。百度system:java.io.tmpdir,网页上显示Linux下面的路径为/tmp/,因此把hive-site.xml文件里面的两个system:java.io.tmpdir分别更改为/tmp/
hive配置相关错误解决方法。http://blog.csdn.net/jim110/article/details/44907745
再次运行bin/hive,运行成功。
hadoop@schpc:/usr/local/hive1.2.1$ bin/hive
16/05/17 11:02:05 WARN conf.HiveConf: HiveConf of name hive.exec.scratdir does not exist
Logging initialized using configuration in file:/usr/local/hive1.2.1/conf/hive-log4j.properties
hive>
在hive中建表后,使用show tables;命令结果显示如下错误:

经网上搜索查询得知:貌似hive.log的路径中不能出现":"。然后我把system后面的冒号改成了.号,结果耗时不行。
然后,恍然大悟hive/conf下面的配置文件hive-site.xml和hive-log4j.properties都提到了hive中的日志log的存放路径以及名字。四不四两个文件中的设置
不一致造成的呢,查询了一下果真两个文件中的配置目录不一致。所以我把两者的目录都改成了/tmp/hive/<user.name>(hive-log4j.properties中),/tmp/hive/${user.name}
(hive-site.xml中)保存,重启hive,然后再次执行show tables,ok得到如下结果:
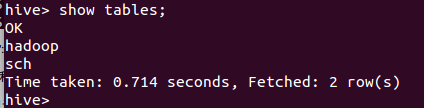
以上是使用derby模式下的hive已经能够成功运行,这说明在系统中关于hive配置文件中的参数是正确的,即hive-env.sh和
hive-site.xml这两个文件中的配置是正确的。
接下来要配置的是以MySQL作为存储元数据库的hive的安装(此中模式下是将hive的metadata存储在mysql中,mysql的运行环境支撑双向同步和集群工作环境,这样的话
,至少两台数据库服务器上汇备份hive的元数据),要使用hadoop来创建相应的文件夹路径,
并设置权限:
bin/hadoop fs -mkdir /user/hadoop/hive/warehouse
bin/hadoop fs -mkdir /user/hadoop/hive/tmp
bin/hadoop fs -mkdir /user/hadoop/hive/log
bin/hadoop fs -chmod g+w /user/hadoop/hive/warehouse
bin/hadoop fs -chmod g+w /user/hadoop/hive/tmp
bin/hadoop fs -chmod g+w /user/hadoop/hive/log
继续配置hive-site.xml
[1]
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://localhost:9000/user/hadoop/hive/warehouse</value>
(这里就与前面的hadoop fs -mkdir -p /user/hadoop/hive/warehouse相对应)
</property>
其中localhost指的是笔者的NameNode的hostname;
[2]
<name>hive.exec.scratchdir</name>
<value>hdfs://localhost:9000/user/hadoop/hive/scratchdir</value>
</property>
[3]
//这个没有变化与derby配置时相同
<property>
<name>hive.querylog.location</name>
<value>/usr/hive/log</value>
</property>
-------------------------------------
[4]
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNoExist=true</value>
</property>
javax.jdo.option.ConnectionURL
这个参数使用来设置元数据连接字串
注意红字部分在hive-site.xml中是有的,不用自己添加。
我自己的错误:没有在文件中找到这个属性,然后就自己添加了结果导致开启hive一直报错。最后找到了文件中的该属性选项然后修改,才启动成功。
Unableto open a test connection to the given database. JDBC url =jdbc:derby:;databaseName=/usr/local/hive121/metastore_db;create=true,username = hive. Terminating connection pool (set lazyInit to true ifyou expect to start your database after your app). OriginalException: ------
java.sql.SQLException:Failed to create database '/usr/local/hive121/metastore_db', see thenext exception for details.
atorg.apache.derby.impl.jdbc.SQLE
-------------------------------------
[5]
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
javax.jdo.option.ConnectionDriverName
关于在hive中用java来开发与mysql进行交互时,需要用到一个关于mysql的connector,这个可以将java语言描述的对database进行的操作转化为mysql可以理解的语句。
connector是一个用java语言描述的jar文件,而这个connector可以在官方网站上下载,经验正是connector与mysql的版本号不一致也可以运行。
connector要copy到/usr/local/hive1.2.1/lib目录下
[6]
<property>
<name>javax.jdo.option.ConnectorUserName</name>
<value>hive</value>
</property>
这个javax.jdo.option.ConnectionUserName
是用来设置hive存放元数据的数据库(这里是mysql数据库)的用户名称的。
[7]
--------------------------------------
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
这个javax.jdo.option.ConnetionPassword是用来设置,
用户登录数据库(上面的数据库)的时候需要输入的密码的.
[8]
<property>
<name>hive.aux.jars.path</name>
<value>file:///usr/local/hive/lib/hive-Hbase-handler-0.13.1.jar,file:///usr/local/hive/lib/protobuf-java-2.5.0.jar,file:///us
r/local/hive/lib/hbase-client-0.96.0-hadoop2.jar,file:///usr/local/hive/lib/hbase-common-0.96.0-hadoop2.jar,file:///usr/local
/hive/lib/zookeeper-3.4.5.jar,file:///usr/local/hive/lib/guava-11.0.2.jar</value>
</property>
/相应的jar包要从hbase的lib文件夹下复制到hive的lib文件夹下。
[9]
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
</property>
</configuration>
---------------------------------------- 到此原理介绍完毕
要使用Hadoop来创建相应的文件路径,
并且要为它们设定权限:
hdfs dfs -mkdir -p /usr/hive/warehouse
hdfs dfs -mkdir -p /usr/hive/tmp
hdfs dfs -mkdir -p /usr/hive/log
hdfs dfs -chmod g+w /usr/hive/warehouse
hdfs dfs -chmod g+w /usr/hive/tmp
hdfs dfs -chmod g+w /usr/hive/log
[root@db96 ~]# hadoop fs -mkdir /tmp
[root@db96 ~]# hadoop fs -ls /hive
[root@db96 ~]# hadoop fs -chmod -R g+w /hive/
[root@db96 ~]# hadoop fs -chmod -R g+w /tmp














 2291
2291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









