









Hadoop存储数据时需要着重考虑的一个因素就是压缩.这里不仅要满足节省存储空间的需求,也要提升数据处理性能.在处理大量数据时,消耗最大的是磁盘和网络的I/O,所以减少需要读取或者写入磁盘的数据量就能大大缩短整体处理时间.这包括数据源的压缩,它也包括数据处理过程(如MapReduce任务)中产生的中间数据的压缩.尽管压缩会增加CPU负载,但是大多数情况下,I/O上的节省仍然大于增加的CPU负载
压缩能够极大地优化处理性能,但是Hadoop支持的压缩格式并不都是可以分片的.MapReduce框架先将数据分片,然后在输入多个任务,所以不支持分片的压缩格式对于数据的高效处理极为不利.如果文件不可分片,哪就意味着需要将整个文件输入到一个单独的MapReduce任务,根本无法利用Hadoop提供的大规模并行以及数据本地化优势.因此,在选择压缩格式与文件格式时,是否支持分片是一个重要的考虑因素.
Snappy
Snappy是Google开发的一种压缩编解码器,用于实现高速压缩,适当兼顾压缩率.虽然压缩率不算突出,但是Snappy能够较好的平衡压缩速度和大小.Snappy的处理性能显著优于其他压缩格式.值得注意到是,使用Snappy压缩的文件不是可分片的,所以他要与容器格式(如SequenceFile和Avro)联合使用
LZO
与Snappy类似,LZO也具有较好的压缩速度,单压缩率略显平庸.与Snappy不同的是,使用LZO压缩的文件可分片,不过这里要求建立索引.如果纯文本文件不存储到容器格式中,那么使用LZO是一个不错的选择.有一点需要注意的是,LZO的许可协议不允许将其打包到Hadoop中进行分发,因此需要单独安装.Snappy则不同,它可以与Hadoop一起分发.
Gzip
Gzip的压缩性能非常好,平均来讲,可以达到Snappy的2.5倍.但是他的写入速度不如Snappy,平均为Snappy的一半.在读取性能上.Gzip通常与Snappy相差不.Gzip同样是不可分片的,所以应该与容器格式联合使用呢.请注意,Gzip处理数据有时回避Snappy慢,原因在于Gzip压缩文件需要的数据块较少,所以处理限购他那个数据所需的任务就更少,因此,使用Gzip时选择较小的数据块,可以达到更好的性能.
bzip2
bzip2的压缩性能很优越,但是处理性能明显比其他压缩编解码格式(如Snappy)要差.与Snappy与Gzip不同,bzip2本身为可分片式.通常来说bzip2会比Gzip慢10倍.因此bzip2在Hadoop中并不是理想的编辑阿妈格式,除非主要的需求就是减少存储空间占用量,例如在线归档时使用的Hadoop的场景
压缩算法推荐
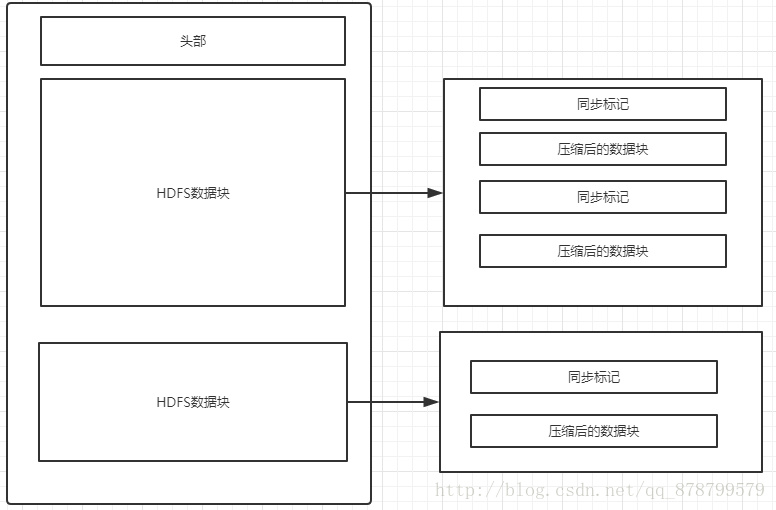
一般来说,在与容器文件格式(Avro,SequenceFile等)一起使用时,任何压缩格式都可以是分片式的,因为容器文件格式能够单独压缩记录构成的数据块,也可以进行记录级的压缩.如果在压缩整个文件时没有使用容器文件格式,那么就需要使用本身支持可分片的压缩格式,比如在数据块之间插入同步标记的Bzip2
以下是在Hadoop中进行压缩的一些建议.
- 开启MapReduce中间数据的输出压缩.这样可以减少需要读取和写入磁盘的中间数据,进而提高了性能.
- 注意数据是如何排序的.通常来讲,数据应当排序,相似的数据要放在一起,这样压缩效率更高.
- 考虑使用支持可分片的压缩算法的紧凑文件格式,如Avro.下图展示了使用不可分片压缩算法的Avro或SequenceFile支持文件分片的方法.














 4260
4260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









