







题目1:对于下面程序排序算法为什么比非排序算法速度快?
import java.util.Arrays;
import java.util.Random;
public class Main
{
public static void main(String[] args)
{
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// !!! With this, the next loop runs faster
// Arrays.sort(data);
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
// Primary loop
for (int c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
}本地测试
非排序
19.674410905
sum = 155184200000排序
9.268876748
sum = 155184200000差别不是很大,原因我电脑太搓
讲解

回答中这样一句话
If you guess right every time, the train will never have to stop.
If you guess wrong too often, the train will spend a lot of time stopping, backing up, and restarting.
对于
if (data[c] >= 128)
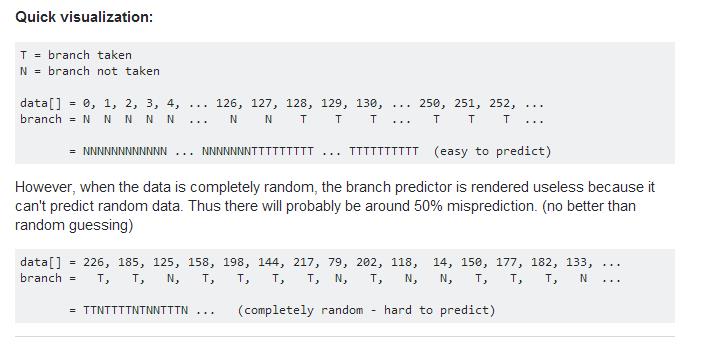
sum += data[c];当时排序的时候,小于128的都是false,不用进行计算,后面的大于128的才进行计算,而非排序的时候,不知道是否大于128都要进行判断。
或者根据上面的解释说出:排序的能够猜到后面位置判断的结果,这样后面的就不需要判断,而非排序的时候猜的错误率很好了,需要花费时间进行判断后在进行计算。
如下图形式:
另外:
对于排序数组,对于下面三种情况
情况一:
for (unsigned i = 0; i < 100000; ++i)
{
for (unsigned j = 0; j < arraySize; ++j)
{
if (data[j] >= 128)
sum += data[j];
}
}测试输出
8.637130399
sum = 155184200000情况二:
for (unsigned j = 0; j < arraySize; ++j)
{
for (unsigned i = 0; i < 100000; ++i)
{
if (data[j] >= 128)
sum += data[j];
}
}测试输出
3.884542342
sum = 155184200000情况二点二
for (unsigned j = 0; j < arraySize; ++j)
{
if (data[j] >= 128)
{
for (unsigned i = 0; i < 100000; ++i)
{
sum += data[j];
}
}
}测试输出
1.323222809
sum = 155184200000情况三:
for (unsigned j = 0; j < arraySize; ++j)
{
if (data[j] >= 128)
{
sum += data[j] * 100000;
}
}测试输出
1.53499E-4
sum = 155184200000从结果上来说三种情况输出的sum应该是一样的
时间下到上是递增的
情况三:时间复杂度
O(N)
情况二:时间复杂度
O(N∗Max)
情况二点二:时间复杂度
O(N∗max)
情况一:时间复杂度
O(Max∗N)
根据时间复杂度上看:case3应该是最小的
对于case2和case1,运行时间的差别,可以通过上面的进行讲解了N*Max,时候这样数已经确定对于判断大于128可以根据前一个判断的结果进行猜测了,显然case2.2猜测的次数相比case2更小,运行时间更小了
case1Max*N ,对于一个max,需要对数组内所以的数进行猜测(虽然上一个值对后面的猜测可以利用),但是猜测次数明显还是比较多的,故case1运行时间比较长。
根据上面结果:当在多维数据进行遍历的时候,维度比较大的在内层循环,可以提高运行效率。
注意:这里根据是否复杂度的值上是一样的,但是具体运行时间差别就很多了
本专题来源stackoverflow 标签是java的投票数比较高的问题以及回答,我只对上面的回答根据自己的理解做下总结。















 3367
3367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









