








本文博客为原创,未经本人允许,不得扒下来传到百度文库及相关平台。
目录
Scrapy介绍
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的python应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。Scrapy 目前最新的版本,内容涉及安装,使用,开发,API 调试等全部知识点,帮助读者学习使用 Scrapy 框架开发网络爬虫。
关于Scrapy的安装,请看我前面写的一篇博客:http://blog.csdn.net/qy20115549/article/details/52528896
Scrapy建立新工程
在开始爬取之前,您必须创建一个新的 Scrapy 项目。 进入您打算存储代码的目录中【工作目录】,运行下列命令,如下是我创建的一个爬取豆瓣的工程douban【存储路径为:G:\python】:
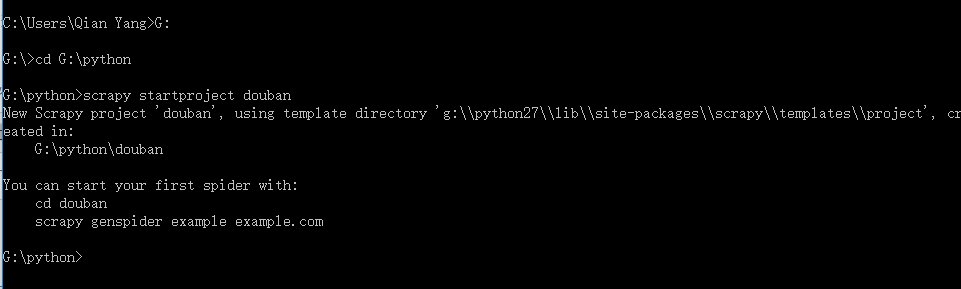
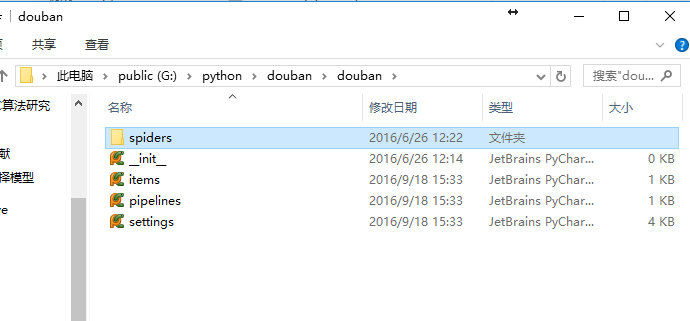
下图为其自动生成的目录结构:
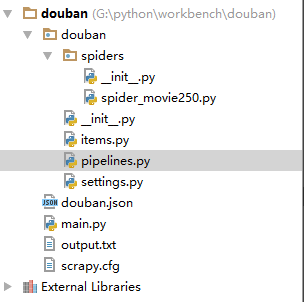
用Pycharm打开工程并编辑
如下图所示为Pycharm打开的结果,可以很清晰的看到其爬虫框架的目录结构:
items的编写
首先,文件中有items.py,这个里面这要是用来封装爬虫所要爬的字段,如爬豆瓣电影,需要爬电影的ID,url,电影名称等。
__author__ = ' HeFei University of Technology Qian Yang email:1563178220@qq.com'
# -*- coding:utf-8 -*-
import scrapy
class MovieItem(scrapy.Item):
rank = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
rate = scrapy.Field()
quote = scrapy.Field()Spider的编写
Spider 是用户编写用于从单个网站(或者一些网站)爬取数据的类。其包含了一个用于下载的初始 URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
__author__ = ' HeFei University of Technology Qian Yang email:1563178220@qq.com'
# -*- coding:utf-8 -*-
import scrapy
from douban.items import MovieItem
class Movie250Spider(scrapy.Spider):
# 定义爬虫的名称,主要main方法使用
name = 'doubanmovie'
allowed_domains = ["douban.com"]
start_urls = [
"http://movie.douban.com/top250/"
]
# 解析数据
def parse(self, response):
items = []
for info in response.xpath('//div[@class="item"]'):
item = MovieItem()
item['rank'] = info.xpath('div[@class="pic"]/em/text()').extract()
item['title'] = info.xpath('div[@class="pic"]/a/img/@alt').extract()
item['link'] = info.xpath('div[@class="pic"]/a/@href').extract()
item['rate'] = info.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract()
item['quote'] = info.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span/text()').extract()
items.append(item)
yield item
# 翻页
next_page = response.xpath('//span[@class="next"]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
#爬每一页
yield scrapy.Request(url, self.parse)存储pipelines
以下写了两个存储方式,第一种是以Json的形式进行存储,第二种是将数据存储到mysql数据库。
__author__ = ' HeFei University of Technology Qian Yang email:1563178220@qq.com'
# -*- coding: utf-8 -*-
import json
import codecs
#以Json的形式存储
class JsonWithEncodingCnblogsPipeline(object):
def __init__(self):
self.file = codecs.open('douban.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
#将数据存储到mysql数据库
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class MySQLStorePipeline(object):
#数据库参数
def __init__(self):
dbargs = dict(
host = '127.0.0.1',
db = 'test',
user = 'root',
passwd = '112233',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = True
)
self.dbpool = adbapi.ConnectionPool('MySQLdb',**dbargs)
'''
The default pipeline invoke function
'''
def process_item(self, item,spider):
res = self.dbpool.runInteraction(self.insert_into_table,item)
return item
#插入的表,此表需要事先建好
def insert_into_table(self,conn,item):
conn.execute('insert into douban(rank, title, rate,qute,link) values(%s,%s,%s,%s,%s)', (
item['rank'][0],
item['title'][0],
# item['star'][0],
item['rate'][0],
item['quote'][0],
item['link'][0])
)settings的编写
settings主要放配置方面的文件,如下为我setting。
#USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
# start MySQL database configure setting
MYSQL_HOST = 'localhost'
MYSQL_DBNAME = 'test'
MYSQL_USER = 'root'
MYSQL_PASSWD = '11223'
# end of MySQL database configure setting
ITEM_PIPELINES = {
'douban.pipelines.JsonWithEncodingCnblogsPipeline': 300,
'douban.pipelines.MySQLStorePipeline': 300,
}main方法
__author__ = ' HeFei University of Technology Qian Yang email:1563178220@qq.com'
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanmovie".split())运行main方法
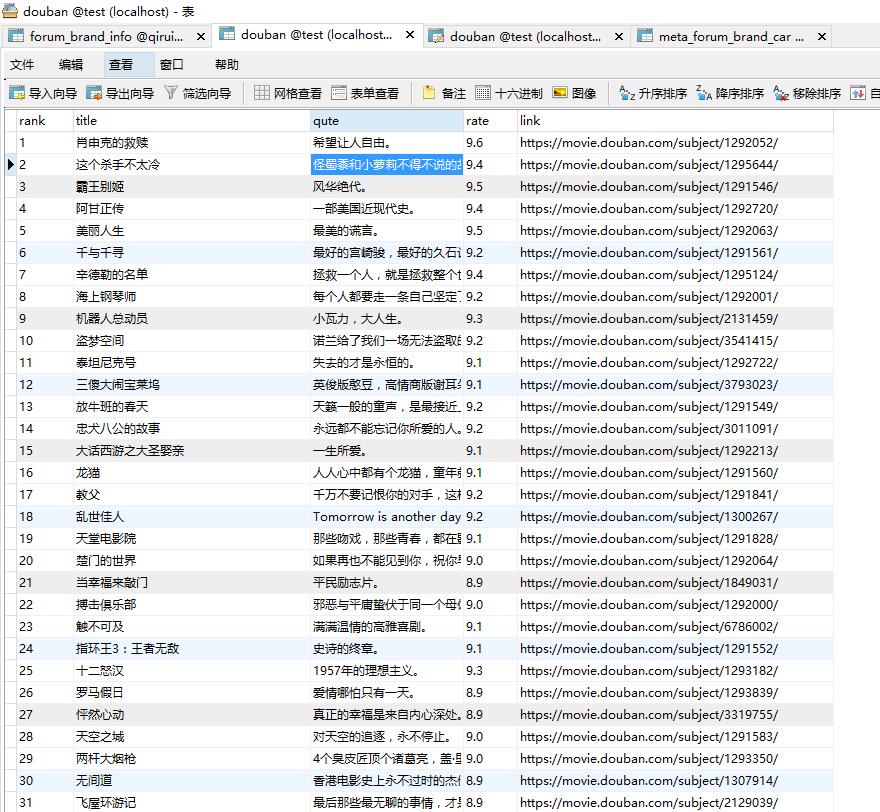
如下为其运行结果。
















 2966
2966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









