







结果
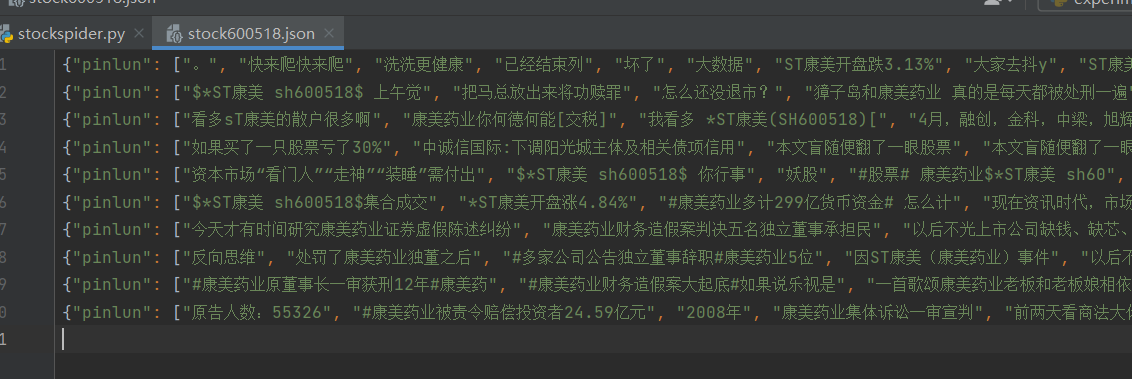
items
import scrapy
class MyprojectItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
#Field类仅是内置字典类(dict)的一个别名,并没有提供额外的方法和属性。被用来基于类属性的方法来支持item生命语法。
pinlun=scrapy.Field()#在items中定义数据类型;指出Pinlun是一个类似于字典的类,有键值对的形式
pinluntime=scrapy.Field()#定义评论时间
蜘蛛程序
import scrapy
#from Myproject.items import MyprojectItem#报错,改为下面
from ..items import MyprojectItem#在一个package中,同级使用 . 在父级使用 ..
#电脑不知道 你说的是哪个 文件 毕竟这两个文件名是一样的
class StockspiderSpider(scrapy.Spider):
name = 'stockspider'
allowed_domains = ["sina.com.cn"]
#start_urls = ["http://guba.sina.com.cn/?s=bar&name=sh600518&type=0&page=2"]#提交请求给引擎,引擎发给排队器,然后转给下载器
start = 1 # 设置一个变量, 规律 每增加1就是往下翻一页
url = 'http://guba.sina.com.cn/?s=bar&name=sh600518&type=0&page='
start_urls = [url + str(start)]
def parse(self, response):#下载器返回了相应文件,然后开始处理响应文件
#print(response.body)
stockitem=MyprojectItem()
stockitem['pinlun']= response.xpath('//*[@id="blk_list_02"]/table/tbody/tr[*]/td[3]/a/text()').extract()
stockitem['pinluntime']= response.xpath('//*[@id="blk_list_02"]/table/tbody/tr[*]/td[5]/text()').extract()
stockitem['name'] = response.xpath('//*[@id="blk_list_02"]/table/tbody/tr[*]/td[4]/div/a/text()').extract()
yield stockitem#数据交给管道文件储存
# 下载4页
if self.start < 10:
self.start += 1
url = self.url + str(self.start)
yield scrapy.Request(url, callback=self.parse) #使用迭代的方式循环调用request
pipelines
import json#导入Json库
class MyprojectPipeline:
def __init__(self):
self.filename=open("stock600518.json","w")#初始化对象的属性
def process_item(self, item, spider):
text = json.dumps(dict(item), ensure_ascii=False)+"\n"
# bytes to str
bs = str(text.encode("utf-8"), encoding="utf8")
self.filename.write(bs)#写入文本
return item#item必须return
def close_spider(self, spider):#可选
self.filename.close()
settings设置随机延迟50-100ms
DOWNLOAD_DELAY = 0.05
custom_settings = {
"RANDOM_DELAY": 0.1,
"DOWNLOADER_MIDDLEWARES": {
"middlewares.random_delay_middleware.RandomDelayMiddleware": 999,
}
}
DOWNLOAD_DELAY与custom_settings都用于设置爬虫时的延迟。
但前一个设置的是固定的,后一个设置的是随机的。
对于后者如果设置RANDOM_DELAY=3,就代表随机延迟0-3秒。
二者结合起来总的延迟将有所改变。
DOWNLOAD_DELAY + 0 < total_delay < DOWNLOAD_DELAY + RANDOM_DELAY
所以这里这样设置,它的延迟就为50ms-100ms之间。
介绍
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。 [3]
尽管Scrapy原本是设计用来屏幕抓取(更精确的说,是网络抓取),但它也可以用来访问API来提取数据。
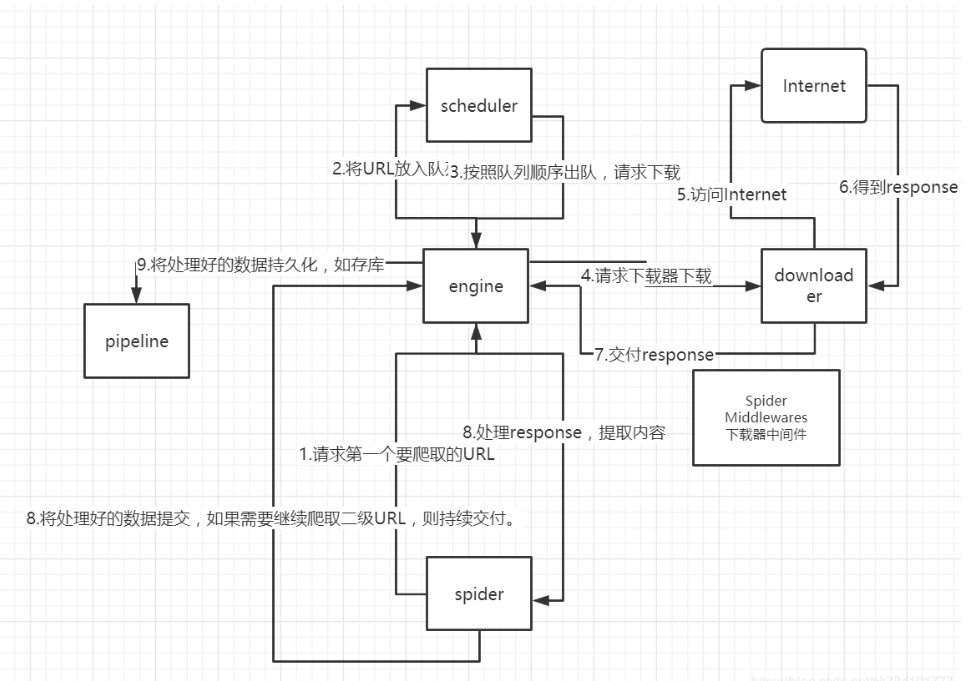
(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
(2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
(3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程















 4269
4269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









