







1. Tensorflow GPU支持
Tensorflow 支持GPU进行运算,目前官方版本只支持NVIDIA的GPU,可以在tensorflow的官方上看到。Tensorflow 对GPU的运算的支持最小力度就是OP,也就是我们常说的算子,下图提供了Tensorflow的一些常见算子,而每个算子在Tensorflow上都会提供GPU的算法:关于OP的具体实现,在本篇博客中就不叙述了。
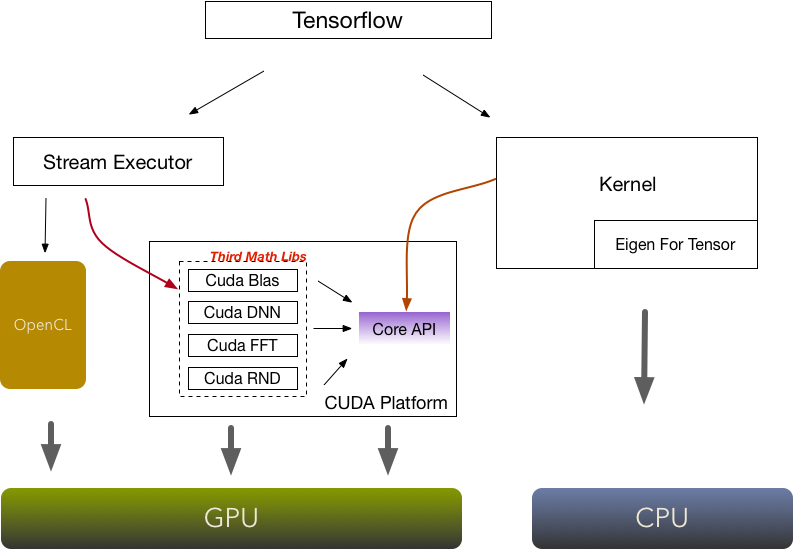
2. Tensorflow GPU调用架构
 、
、
从上图我们可以看到,Tensorflow提供两种方式调用NVIDIA的方式,而NVIDIA的GPU调用方式主要依靠的CUDA的并行计算框架
2.1 Stream Executor
StreamExecutor 是一个子项目,是一个google开源的数学并行运算库,是基于CUDA API、OpenCL API管理各种GPU设备的统一API,这种统一的GPU封装适用于需要与GPU设备通信的库,而在Tensorflow上只提供了对CUDA的支持
StreamExecutor的主要功能:
- 抽象化底层平台,对开发者不需要考虑底层的GPU的平台
- 流式的管理模式
- 封装了主机和GPU之间的数据移动
在StreamExecutor里封装了几个常见的基本的核心运算:
- BLAS: 基本线性代数
- DNN: 深层神经网络
- FFT: 快速傅里叶变换
- RNG: 随机数生成
2.1.1 Stream 接口

- 算子直接通过Stream的API的调用,在Tensorflow里Stream executor 只支持4个核心算法
- 每个算法都提供Support的类,进行多态的支持,比如CUDA, OpenCL
- 通过Support,官方tensorflow 只提供了CUDA支持,如果要支持OpenCL,可以参考开源(点击打开链接)
- 对CUDA的支持使用了基于CUDA平台的第三方开发库,没有直接使用CUDA编程
2.2 直接调用CUDA
Tensorflow 同时本身也可以直接调用CUDA,毕竟Stream的目前接口只是支持了Blas, DNN, FFT, RND这些基本接口
1. 进行复杂运算,需要连续调用Stream的接口,这里也带来了频繁的从主内存到GPU内存之间复制的开销
2. Stream 并没有封装一些简单的一元运算,只是封装了CUDA的提供的第三方运算库,一元运算(加减乘除,log, exp)这些如果想在GPU运算,需要基于CUDA的运算框架进行自己写代码
在Tensorflow上写CUDA代码没什么两样, 下面是一个lstm的样例
1. 定义你的global
template <typename T, bool use_peephole>
__global__ void lstm_gates(const T* icfo, const T* b, const T* cs_prev,
const T* wci, const T* wcf, const T* wco, T* o, T* h,
T* ci, T* cs, T* co, T* i, T* f, const T forget_bias,
const T cell_clip, const int batch_size,
const int cell_size) {
const int batch_id = blockIdx.x * blockDim.x + threadIdx.x;
const int act_id = blockIdx.y * blockDim.y + threadIdx.y;
.......
} dim3 block_dim_2d(std::min(batch_size, 8), 32);
dim3 grid_dim_2d(Eigen::divup(batch_size, static_cast<int>(block_dim_2d.x)),
Eigen::divup(cell_size, static_cast<int>(block_dim_2d.y)));
if (use_peephole) {
lstm_gates<T, true><<<grid_dim_2d, block_dim_2d, 0, cu_stream>>>(
icfo.data(), b.data(), cs_prev.data(), wci.data(), wcf.data(),
wco.data(), o.data(), h.data(), ci.data(), cs.data(), co.data(),
i.data(), f.data(), forget_bias, cell_clip, batch_size, cell_size);
} else {
lstm_gates<T, false><<<grid_dim_2d, block_dim_2d, 0, cu_stream>>>(
icfo.data(), b.data(), cs_prev.data(), wci.data(), wcf.data(),
wco.data(), o.data(), h.data(), ci.data(), cs.data(), co.data(),
i.data(), f.data(), forget_bias, cell_clip, batch_size, cell_size);
}3. 定义你的OP,在你的OP里调用CUDA的代码,并注册到Tensorflow Kernel中,注意你的Device需要设置成DEVICE_GPU,tensorflow会依据客户端传递的device的参数来决定是否需调用GPU还是CPU的算法,CUDA的文件以.cu.cc为结尾
REGISTER_KERNEL_BUILDER(
Name("arithmetic").Device(DEVICE_GPU).TypeConstraint<Eigen::half>("T"),
arithmeticOP<Eigen::half>);














 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









