







今天学习了可以实现进程间通信的管道,其实说白了它也就是一个文件,只是它的功能比较特殊。
那么一个管道文件的最大容量是多少呢?
自己写了一个程序测了一下:
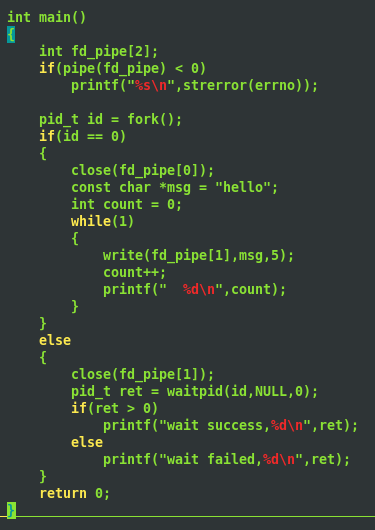
每次写五个字节,最后结果如下:

一共写了13104次,13104*5=65520B 约为64KB
我装的系统是64位的centos,它的大小会不会也与平台有关呢?
去查了一下,在window下,它的最大容量是256MB.
还有一个问题,就是管道的内部结构到底是怎样的呢?为什它可以实现进程间的通信呢?
这是我在网上截的图
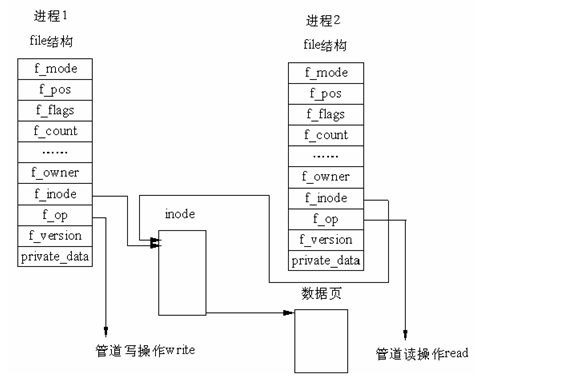
可以看到管道的实现借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。















 1651
1651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









