







str(),epr()和''运算在特性和功能方面相似,事实上repr()和''做的是完全一样的事情(函数和操作符做同样一件事,是因为在有的场合函数会比操作符更合适),它们返回的是一个对象的“官方”字符串表示。
>>> s = 'Hello, world.'
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
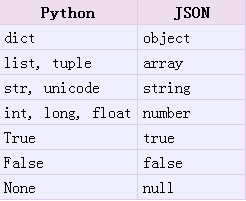
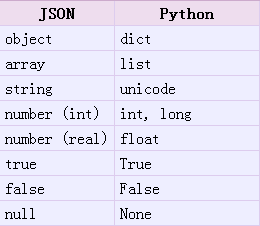
python对json的相关操作
对简单数据类型的encoding 和 decoding:
encoding:把一个Python对象编码转换成Json字符串
decoding:把Json格式字符串解码转换成Python对象
使用简单的json.dumps方法对简单数据类型进行编码
>>> obj = [[1,2,3],123,123.123,'abc',{'key1':(1,2,encoding3),'key2':(4,5,6)}]
>>> encodedjson = json.dumps(obj) #encoding:json.dumps()
>>> print repr(obj)
[[1, 2, 3], 123, 123.123, 'abc', {'key2': (4, 5, 6), 'key1': (1, 2, 3)}]
>>> print encodedjson
[[1, 2, 3], 123, 123.123, "abc", {"key2": [4, 5, 6], "key1": [1, 2, 3]}]
>>> print encodedjson[0]
[
>>> print encodedjson[1]
[
>>> print encodedjson[2]
1
>>> print encodedjson[3]
,
>>> print obj[0]
[1, 2, 3]
>>> print obj[0][1]
2
>>> decodejson = json.loads(encodedjson) #decoding :json.loads()
>>> print type(decodejson)
<type 'list'>
>>> print decodejson[4]['key1']
[1, 2, 3]
>>> print decodejson
[[1, 2, 3], 123, 123.123, u'abc', {u'key2': [4, 5, 6], u'key1': [1, 2, 3]}]
loads方法返回了原始的对象,但是仍然发生了一些数据类型的转化。比如,上例中‘abc’转化为了unicode类型。
json.dumps方法提供了很多好用的参数可供选择,比较常用的有sort_keys(对dict对象进行排序,我们知道默认dict是无序存放的),separators,indent等参数。
sort_keys:对dict对象进行排序,我们知道默认dict是无序存放的
>>> data1 = {'b':789, 'c':456, 'a':123}
>>> d1 = json.dumps(data1, sort_keys=True)
>>> print d1
{"a": 123, "b": 789, "c": 456}
indent:缩进的意思,它可以使得数据存储的格式变得更加优雅。
>>> d1 = json.dumps(data1, sort_keys=True, indent=4)
>>> print d1
{
"a": 123,
"b": 789,
"c": 456
}
separator:作用是去掉,,:后面的空格,在我们传输数据的过程中,越精简越好,冗余的东西全部去掉,因此就可以加上separators参数
。
data = [ { 'a':'A', 'b':(2, 4), 'c':3.0 } ]
print 'DATA:', repr(data)
print 'repr(data) :', len(repr(data))
print 'dumps(data) :', len(json.dumps(data))
print 'dumps(data, indent=2) :', len(json.dumps(data, indent=2))
print 'dumps(data, separators):', len(json.dumps(data, separators=(',',':')))
输出:
DATA: [{'a': 'A', 'c': 3.0, 'b': (2, 4)}]
repr(data) : 35 #data的长度不同
dumps(data) : 35
dumps(data, indent=2) : 76
dumps(data, separators): 29
skipkeys:在encoding过程中,dict对象的key只可以是string对象,如果是其他类型,那么在编码过程中就会抛出ValueError的异常。
skipkeys可以跳过那些非string对象当作key的处理
data= [ { 'a':'A', 'b':(2, 4), 'c':3.0, ('d',):'D tuple' } ]
try:
print json.dumps(data)
except (TypeError, ValueError) as err:
print 'ERROR:', err
print
print json.dumps(data, skipkeys=True)
输出:
ERROR: keys must be a string
[{"a": "A", "c": 3.0, "b": [2, 4]}]















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









