









概述
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值. 也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
HASH主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值. 也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
散列表是一种用于以常数平均时间执行插入、删除、查找的算法。
散列函数
散列表每个关键字被映射到0到TableSize-1这个范围中的某个值,这个映射叫做散列函数。因为单元个数是有限的,两个关键字可能映射到同一个值,这个时候就需要通过一些方式来处理冲突。
以关键字为字符串为例,设计简单的散列函数。
通过将字符串的ASCII码值的和来计算hash值。
public static int hash1(String key, int tablesize) {
int hashVal = 0;
for (int i = 0; i < key.length(); i++) {
hashVal += key.charAt(i);
}
return hashVal % tablesize;
}这种方法有个明显缺陷,就是hash值分配不均匀。
较好的散列方法
public static int hash2(String key, int tablesize) {
int hashVal = 0;
for (int i = 0; i < key.length(); i++) {
hashVal = 37 * hashVal + key.charAt(i);
}
hashVal = hashVal % tablesize;
if (hashVal < 0) {
hashVal += tablesize;
}
return hashVal;
}分离链法解冲突
将散列到一个值的所有元素保留到一个表中。
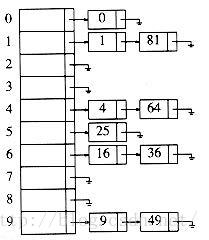
思想:将散列到同一个值的元素保留到一个链表中。
缺点:给新链表单元分配地址空间需要花费时间,会降低算法的速度。
分析:一次不成功的查找需要访问的节点数平均为;成功的查找需要遍历大约1+/2个链。
简单实现
public class SeparateChainHashTable<T> {
private static final int DEFAULT_SIZE = 100;
protected LinkedList[] lists;
public SeparateChainHashTable() {
this(DEFAULT_SIZE);
}
public SeparateChainHashTable(int size) {
lists = new LinkedList[PrimeNumber.nextPrime(size)];
for (int i = 0; i < lists.length; i++) {
lists[i] = new LinkedList<T>();
}
}
public boolean contains(T x) {
return lists[hashCode(x)].contains(x);
}
public void insert(T x) {
LinkedList<T> linkedList = lists[hashCode(x)];
if (!linkedList.contains(x)) {
linkedList.add(x);
}
}
public void remove(T x) {
LinkedList<T> linkedList = lists[hashCode(x)];
if (linkedList.contains(x)) {
linkedList.remove(x);
}
}
/**
* 计算hash值
*
* @param x
* @return
*/
private int hashCode(T x) {
int hashVal = x.hashCode();
hashVal = hashVal % lists.length;
if (hashVal > 0) {
hashVal += lists.length;
}
return hashVal;
}
}开放定址法
通常要求装填因子 < 0.5(为了1.保证线性时间界;2.保证能成功插入),否则需要rehash()思想:解决冲突的另一个办法是当冲突发生时选择另一个单元进行判断,直到出现空单元。即执行,直到找到空单元,其中,f()是解决冲突的函数。这样的表也叫探测散列表(Probing hash tables)。
特点: 此种方法使用的tableSize比分离链接法要大(因为将冲突的元素分配到其他cell中);通常来说,此类方法的装填因子要低于0.5。
实现:
1)线性探测:采取的方式,容易产生一次聚集(primary clustering),产生一些滚雪球的堆块,导致散列到区块中的任何键值都需要多次试选单元才能解决冲突。一种解决方法是采用随机冲突解决方法(怎么查找?),即使得每次探测都与前次探测无关。可以看到,如果装填因子大于0.5时,线性探测不是一个好办法。
2)平方探测:采用的方式,问题在于,一旦装填因子大于0.5,就不能保证总会找到空的单元(如果表大小不是素数,那小于0.5时也可能找不到空单元)。平方探测会引起二次聚集(secondary clustering)效应,但其影响远小于一次聚集,可使用双散列的方法消除二次聚集,但同时也带来了额外的计算开销。
3)双散列(double hashing):一种流行的方式是,第二个散列函数的选择至关重要,一种选择是,R是小于TableSize的素数。实验证明,双散列预期探测次数几乎和随机冲突探测的相同,具有较好的表现。但由于需要两个散列函数,计算很耗时(尤其在string类型的key下)。所以实际中通常采用更加简便快捷的二次探测。
分析:在探测散列表中不能执行标准的删除操作(否则依赖当前cell的后续冲突元素将无法删除),需要采用懒惰删除,即在元素上附加数据成员表征其状态(ACTIVE/EMPTY/DELETED)。
再散列(reHash)
使用平方探测的开放定址法时,如果表中元素太多,那么操作的时间会增加,而且插入操作有可能失败,此时需要对哈希表的大小进行扩张(两倍),使用一个新散列函数扫描原来的散列表,计算每个元素的新散列值。再散列通常有多种实现方式:
1)当表满到一半时;
2)遇到插入失败时;
3)当表到达一个装填因子时(途中策略)。
通常选取一个好的截止点来采用第三种方案。
可扩散列
用于内存不可一次载入的大数据量操作。类比B-树的实现:根D存在主存中,对磁盘内容进行索引。关键问题在于如何降低分支系数和如何进行树结构的分裂和扩展。具体分析不再详述。需要注意一点是,如果M(每片树叶最多能存储的元素数目)过小的话,可能会导致目录过大,此时需要做一个二级索引(变相增加了M的大小),但存在潜在的无法避免的二次磁盘访问(如果主存不足以装下二级索引)。
标准库中的三列表
标准库中包括Set和Map的散列实现,即HashSet类和HashMap类。HashSet的实现直接借助了HashMap。JDK中是使用分离链接散列实现的。
代码实现可以看github,地址https://github.com/robertjc/simplealgorithm
github代码也在不断完善中,有些地方可能有问题,还请多指教
欢迎扫描二维码,关注公众号















 2032
2032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









