







缓冲技术某种程度上而言也是符合银弹理论,增加了一层抽象层–缓冲区,用于解决上下游机器介质速度不匹配导致的程序速度缓慢的问题。
缓冲器是一个存储器,它可以是硬件级的,即独立于内存外设置的专门硬件缓冲器(内存页表起始地址寄存器),也可以是软件级的,即由软件在内存中开辟一块缓冲区域(buffer,cache)。硬件要花钱,所以一般用在关键的地方。
1. 引入缓冲技术的原因
1.Cache缓存,减少读块设备的次数。当进程需要在相应的块存储设备中读取数据时,可以通过操作系统批量地从块设备中预读取一段数据存放在缓冲器(一般是在内存中专门划分出来的区域),当再次对此块设备进行文件读取时,可以先从缓冲器内优先搜索,若没有命中,则转向块设备中进行读取。数据复用,当命中率(所读数据在缓冲器内的次数与读操作的总次数的比值)较高时,会明显提高读操作的速度;(fread文件时,操作系统会为该文件配置专属缓冲)
2.减少对CPU的中断次数:这是硬件缓冲器的作用。举个例子,比如在通信系统中,发送端发送来的数据,接收端只提供了一个Byte寄存器来缓冲接受,这意味着如果发送端发来一个Byte,接受端必须响应中断立即处理,不然缓冲寄存器中的数据会被下一次接受覆盖,而如果接受端提供8Byte的寄存器来缓冲接受,则显然可以将中断的频率降低至1/8。注:软缓冲并不能减少中断次数。
3.作为无法直接通信的设备间的中转:比如将光盘上的数据存到磁盘上,可以现在内存中开辟一块缓冲区,先将光盘上的数据移动到缓冲区中,然后再将缓冲区中的内容批量传输到磁盘上。
4.解决进程要求的数据尺寸和块设备提供的物理数据流单位不匹配的情况。如fread只需要读取下一个字符,而磁盘一般是以扇区为单位进行单次数据交换的(1个扇区512 B)。这种供需尺寸不匹配的情况,显然会极大地降低效率,fread代码作为case1的特例的同时,也可以很好地说明这种情况。
5.让CPU和IO设备可以并行工作,加快进程的推荐速度。假设某进程的功能是每次读取一张卡片,然后对此卡片上的信息进行处理,循环进行。如果在卡片阅读器和进程存储区之间直接传输数据,则在从新卡片进行数据读取时,进程的处理端只能idle。所以如果在卡片阅读器和进程存储区之间设置一个缓冲区,则输入时先将卡片信息输入到缓冲区,然后将其复制到进程存储区,这时进程处理端可以进行工作,而缓冲区也可以转而读取下一张卡片,两者协同进行,如果两者速度匹配,则可以进程加速。
2. 软缓冲技术汇总
硬件缓冲一般是用来配备在关键场景下,可以暂且不考虑,主要将目标转向软件缓冲的技术实现上。软缓冲则又可以根据使用场合不同分为:单缓冲、双缓冲、循环缓冲和缓冲池
1、单缓冲
在单缓冲方式中,当用户进程发出I/O请求时,操作系统在内存中为其分配一个缓冲区。数据输入的过程是,当一个用户进程要求输入数据时,操作系统控制输入设备将数据送往缓冲区存放,再送往用户进程的数据存储区。单缓冲由于只有一个缓冲区,所以任何时刻只能支持单向单工操作,要么执行的是读取数据要么执行的是往设备中写数据,而当进程从缓冲区中读数据时,输入设备是不能从块设备搬运数据进入缓冲区的,否则会造成数据紊乱。即任意时刻,下图的四个箭头只能点亮一个。

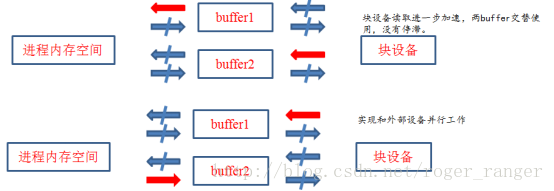
2、双缓冲
提供两个缓冲区,所以可以同时点亮两个箭头,联合操作的可能有多种
3.循环缓冲
链表。循环缓冲技术是在内存中分配大小相等的存储区作为缓冲区,并将这些缓冲区连接起来,每个缓冲区都有一个指向下一个缓冲区的指针,链表形成一个环。并为这个循环链表配备两个全局参数IN和OUT,分别用来指向第一个空缓冲区和第一个满缓冲区。
4.缓冲池:Linux系统采用的方式
1到3都是进程专属缓冲,考虑到当前操作系统的分时并行特性,每个时刻只有一个进程的缓冲体系是在工作,而其他进程的缓冲体系此时没有工作,但是因为专属分配的情况,所以空间依旧被占据着,这便会导致内存占用过大,缓冲体系利用率不高。所以应该考虑采用公用缓冲池结构,可为多个并发进程提供缓冲服务。
a.缓冲池的组成
缓冲池由3种类型的缓冲区构成:空闲缓冲区、装满输入数据的缓冲区和装满输出数据的缓冲区。为了方便管理,将相同类型的缓冲区组成一个队列,于是可分别构成3个队列:空缓冲区队列emq;装满输入数据的缓冲区队列inq;装满输出数据的缓冲区队列outq。由于这些缓冲区是公用的,因此要由操作系统进行统一管理。
b.缓冲池的工作方式
公用缓冲池的缓冲区工作方式4种:收容输入、提取输入、收容输出、提取输出
收容输入:当进程需要输入数据时,从空闲缓冲区队列emq中获取一个空缓冲区,把它作为收容工作缓冲区,然后将数据输入其中,输入完毕,将它挂在inq队列的末尾。
提取输入:当计算进程需要输入数据进行计算时,系统从inq队列的队首取得一个缓冲区,作为提取输入工作缓冲区,计算进程从中提取数据,当进程提取完该缓冲区中的数据后,再将它挂在空缓冲区队列emq的末尾。
收容输出:当计算进程需要输出数据时,系统从空缓冲队列emq的队首取得一个空闲缓冲区,将它作为收容输出工作缓冲区,装满数据后,将它挂在outq队列的末尾。
提取输出:当要进行输出操作时,从输出缓冲区队列outq的队首取得一个缓冲区,作为提取输出工作缓冲区,当数据输出完毕,将该缓冲区挂在空缓冲区队列emq的末尾。
3. Linux系统的磁盘高速缓存
Linux系统在文件系统和磁盘驱动程序之间引入一层抽象层—高速缓存管理层,用于解决内存和磁盘速度不匹配的情况。磁盘缓冲管理试图尽可能多的把有用数据保存在缓冲区中,当进程程序需要读数据时,先从高速缓存中匹配,若命中,则直接从缓存中提取数据而不必启动磁盘IO,如果没有命中,则再启动磁盘驱动先将数据送往高速缓存中,进程再从高速缓存中读数据。当进程往磁盘写数据时,则采用“延迟写”策略,进程现网高速缓冲中写,如果缓冲区满了或延迟写时间到了,则缓冲管理程序会启动磁盘驱动批量写入。
Linux系统提供的缓冲池,是由多进程共享,由操作系统进行统一管理。为了提高使用效率,必须采取适当的管理策略。缓冲区size = 磁盘块size。当进程要从一个磁盘读取数据时,先检查要读取的磁盘块是否包含在某缓冲区中,如果不在,则从空闲缓冲区队列中分配给它一个空闲缓冲区,当进程要将数据写入磁盘时,先检查要写入的磁盘块是否在该设备对应的缓冲区队列中,如果不在则为这个磁盘块分配一个空闲缓冲区。
小小的思维亮点
当缓冲区的信息被读入进行的内存空间后,或者进程已经将数据写进入了缓冲区(延迟写),按理说,该缓冲区已经可以释放了,并进入空闲缓冲队列中等待新任务分配,所以可将缓冲区的flag中的BUSY位置0,送入空闲缓冲区队尾,但这并不意味着立即让此缓冲区退出设备缓冲区队列,而是仍保留在队列中,这样做的原因是此处使用完毕送往空闲缓冲队列的缓冲区保存的信息可能被再次访问,若是直接释放成空缓冲区则显然比较浪费,完全可以等到空闲队列中该缓冲区被新分配了任务时,再根据保留的缓冲区头信息找到该缓冲区在设备缓冲区中位置,将其从队列中删除,并装载新的数据。即存在伪删除的操作fakeDelete()。而当空闲队列pop出的缓冲区的flag位为1的缓冲区,则应该先调度磁盘驱动程序将该延迟写缓冲区内容写到目标磁盘块中,然后再装载新内容。















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









