







摘要
在实际集群上搭建 Hadoop 2.6.4 分布式集群环境。
集群准备
有五台机器,通过已经更改机器名称为master,slaver1,slaver2,slaver3,slaver4,并设置了面密码ssh登录。可以参考这里
| 机器名称 | ip |
|---|---|
| master | 192.168.122.1 |
| slaver1 | 192.168.122.2 |
| slaver2 | 192.168.122.3 |
| slaver3 | 192.168.122.4 |
| slaver4 | 192.168.122.5 |
安装JDK
Centos7 默认是openJDK
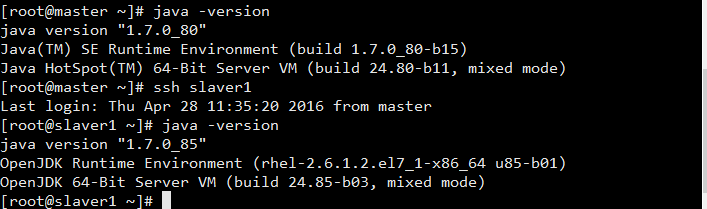
卸载CentOS 7 下的openJDK,安装Sun JDK1.7
查看openJDK安装路径
rpm -qa | grep java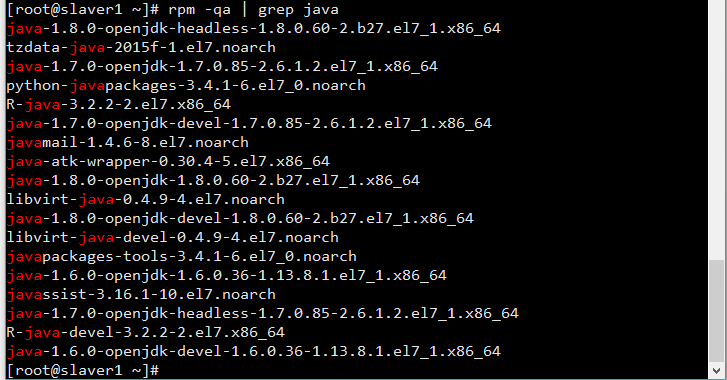
卸载openJDK
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.85-2.6.1.2.el7_1.x86_64
rpm -e --nodeps java-1.8.0-openjdk-devel-1.8.0.60-2.b27.el7_1.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.36-1.13.8.1.el7_1.x86_64
rpm -e --nodeps java-1.6.0-openjdk-devel-1.6.0.36-1.13.8.1.el7_1.x86_64
安装Sun JDK1.7
从官网下载 jdk-7u80-linux-x64.rpm,上传到 master

安装 Sun JDK1.7
rpm -ivh jdk-7u80-linux-x64.rpm 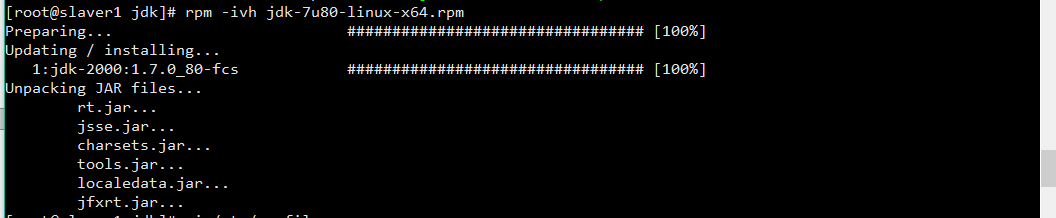
修改环境变量
在 /etc/profile里添加
export JAVA_HOME=/usr/java/jdk1.7.0_80
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin

source 生效

检验安装

安装 Hadoop 2.6.4
下载 ,解压
从官网下载 Hadoop 2.6.4 , 并解压在 master 上
解压路径自己选择,我这里是解压在
/root/workspace/software/hadoop-2.6.4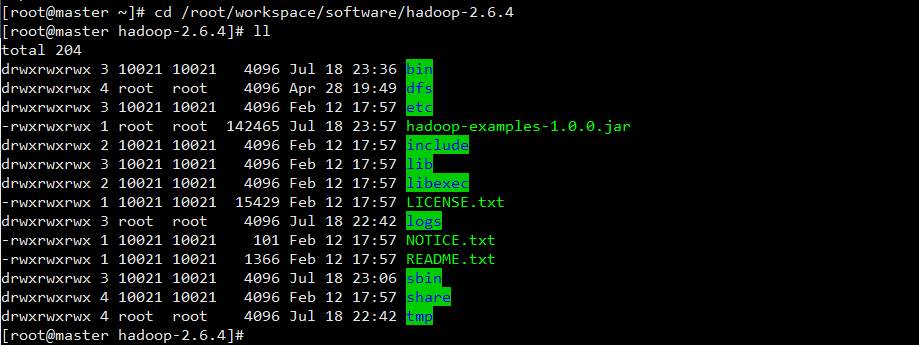
添加环境变量
在 /etc/profile里添加
export HADOOP_HOME=/root/workspace/software/hadoop-2.6.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin修改 Hadoop 配置文件
hadoop-env.sh
在 hadoop 解压路径下面,/etc/hadoop/hadoop-env.sh 增加下面两行
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_PREFIX=/root/workspace/software/hadoop-2.6.4core-site.xml
在 hadoop 解压路径下面,/etc/hadoop/core-site.xml增加下面内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/workspace/software/hadoop-2.6.4/tmp</value>
</property>
</configuration>
hdfs-site.xml
在 hadoop 解压路径下面,/etc/hadoop/hdfs-site.xml 增加下面内容
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>这里设置成3,表示数据有3个副本。
mapred-site.xml
在 hadoop 解压路径下面,/etc/hadoop/mapred-site.xml 增加下面内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-env.sh
在 hadoop 解压路径下面,/etc/hadoop/yarn-env.sh 增加下面,增加 JAVA-HOME 配置
export JAVA_HOME=/usr/java/jdk1.7.0_80yarn-site.xml
在 hadoop 解压路径下面,/etc/hadoop/yarn-site.xml 增加下面内容
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>Yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>Yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<description>The address of the RM web application.</description>
<name>Yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<description>The address of the resource tracker interface.</description>
<name>Yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
</configuration>
这里添加的一些端口号,方便从远程通过浏览器查看集群情况,推荐按照这样添加。
slaves
在 hadoop 解压路径下面,/etc/hadoop/slaves 增加下面内容
master
slaver1
slaver2
slaver3
slaver4
部署 slaver1-slaver4
按照上面流程,把 slaver1-slaver4 上的环境变量添加好,然后直接
scp -r /hadoop2.6.4 root@slaverX:/root/workspace/software/X 是 1- 4,分别复制到 slaver1 - slaver4 下面
启动 hadoop 集群
格式化文件系统
hdfs namenode -format启动 NameNode 和 DateNode
/root/workspace/software/hadoop-2.6.4/sbin , 运行
start-dfs.sh使用 jps 命令查看 master 上的Java进程
[root@master hadoop]# jps
27130 DataNode
27927 NameNode
12379 Jps
27422 SecondaryNameNode
[root@master hadoop]#jps 命令分别查看 slaver1 - slaver4 上的 Java 进程
[root@slaver1 hadoop]# jps
6130 DataNode
1264 Jps查看 NameNode 和 NameNode 信息
浏览器输入
IP:50070/dfshealth.html#tab-datanodeIP 是你集群的IP
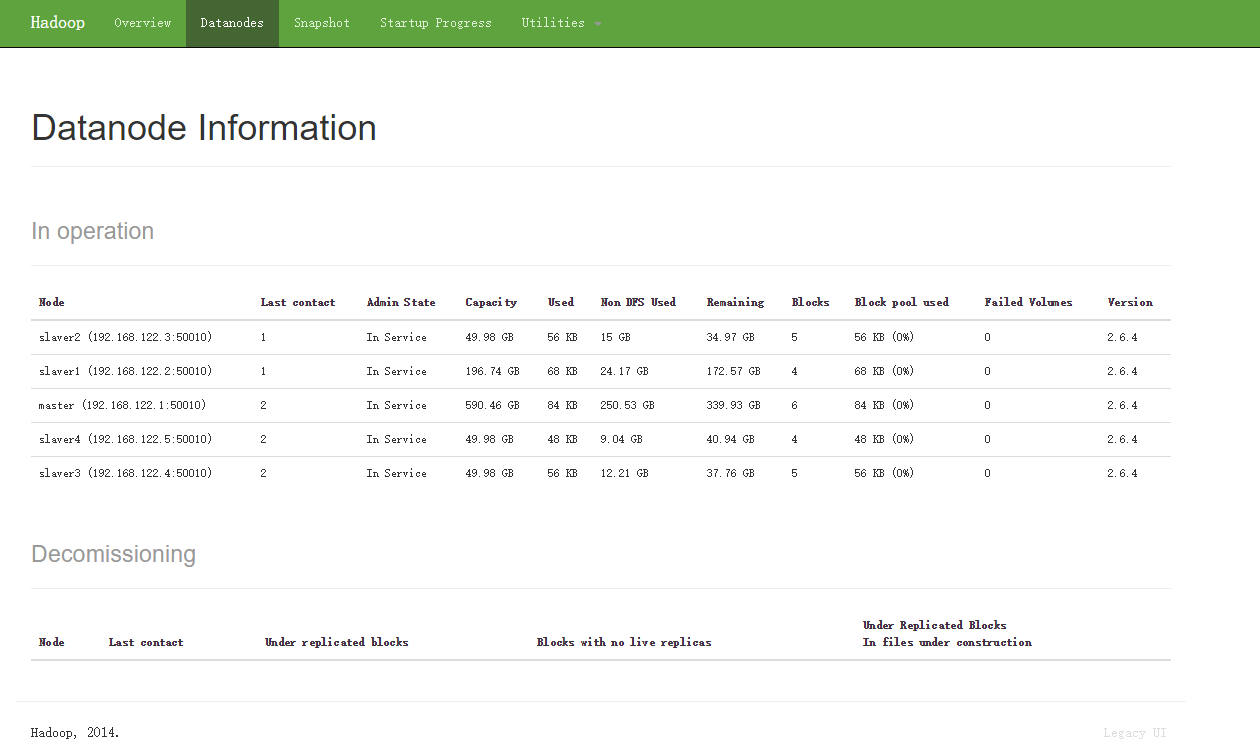
启动 ResourceManager 和 NodeManager
运行 start-yarn.sh , jps查看进程如下:
[root@master hadoop]# jps
27130 DataNode
28777 ResourceManager
27927 NameNode
12379 Jps
28916 NodeManager
27422 SecondaryNameNode切换到 slaver1-slaver4,jps查看进程
[root@slaver1 hadoop]# jps
27130 DataNode
12379 Jps
28916 NodeManager成功了
Hadoop 集群就已经启动了。















 9533
9533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









