







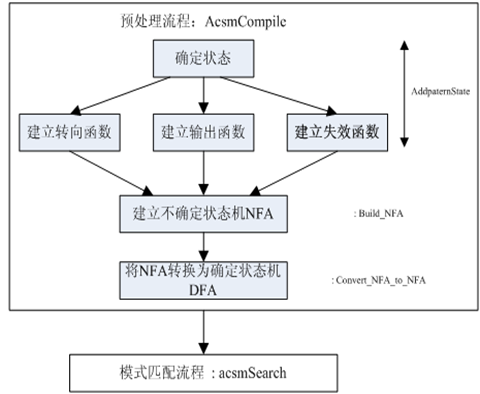
简介
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。要搞懂AC自动机,先得有模式树(字典树)Trie和KMP模式匹配算法的基础知识。AC自动机算法分为3步:构造一棵Trie树,构造失败指针和模式匹配过程。
多模匹配
AC自动机(Aho-Corasick Automaton)是多模匹配算法的一种。所谓多模匹配,是指在字符串匹配中,模式串有多个。前面所介绍的KMP、BM为单模匹配,即模式串只有一个。假设主串
T[1⋯m]
,模式串有
k
个
而KMP并没有利用到模式串之间的重复字符结构信息,每一次的匹配都需要将主串从头至尾扫描一遍。因此,贝尔实验室的Aho与Corasick于1975年结合KMP与有限状态机(finite state machines)的思想,提出AC自动机算法[1]。
AC算法
思想
自动机按照文本字符顺序,接受字符,并发生状态转移。这些状态缓存了“按照字符转移成功(但不是模式串的结尾)”、“按照字符转移成功(是模式串的结尾)”、“按照字符转移失败”三种情况下的跳转与输出情况,因而降低了复杂度。
基本构造
AC算法中有三个核心函数,分别是:
- success; 成功转移到另一个状态(也称goto表或success表)
- failure; 不可顺着字符串跳转的话,则跳转到一个特定的节点(也称failure表),从根节点到这个特定的节点的路径恰好是失败前的文本的一部分。
- emits; 命中一个模式串(也称output表)
举例
以经典的ushers为例,模式串是he/ she/ his /hers,文本为“ushers”。构建的自动机如图:
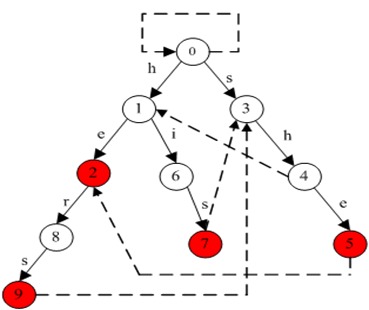
其实上图省略了到根节点的fail边,完整的自动机如下图:
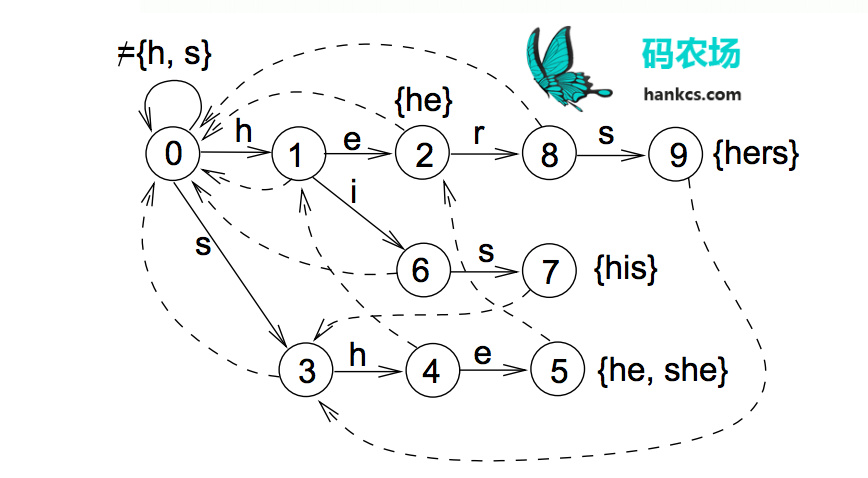
匹配过程
自动机从根节点0出发
- 首先尝试按success表转移(图中实线)。按照文本的指示转移,也就是接收一个u。此时success表中并没有相应路线,转移失败。
- 失败了则按照failure表回去(图中虚线)。按照文本指示,这次接收一个s,转移到状态3。
- 成功了继续按success表转移,直到失败跳转步骤2,或者遇到output表中标明的“可输出状态”(图中红色状态)。此时输出匹配到的模式串,然后将此状态视作普通的状态继续转移。
算法高效之处在于,当自动机接受了“ushe”之后,再接受一个r会导致无法按照success表转移,此时自动机会聪明地按照failure表转移到2号状态,并经过几次转移后输出“hers”。来到2号状态的路不止一条,从根节点一路往下,“h→e”也可以到达。而这个“he”恰好是“ushe”的结尾,状态机就仿佛是压根就没失败过(没有接受r),也没有接受过中间的字符“us”,直接就从初始状态按照“he”的路径走过来一样(到达同一节点,状态完全相同)。

构造过程

看来这三个表很厉害,不过,它们是怎么计算出来的呢?
goto表
很简单,了解一点trie树知识的话就能一眼看穿,goto表就是一棵trie树。把上图的虚线去掉,实线部分就是一棵trie树了。
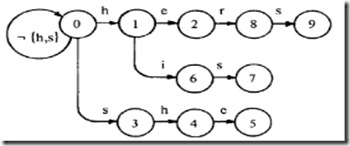
output表
output表也很简单,与trie树里面代表这个节点是否是单词结尾的结构很像。不过trie树只有叶节点才有“output”,并且一个叶节点只有一个output。下图却违背了这两点,这是为什么呢?其实下图的output会在建立failure表的时候进行一次拓充。

failure表
这个表是trie树没有的,加了这个表,AC自动机就看起来不像一棵树,而像一个图了。failure表是状态与状态的一对一关系,别看图中虚线乱糟糟的,不过你仔细看看,就会发现节点只会发出一条虚线,它们严格一对一。
这个表的构造方法是:
- 首先规定与状态0距离为1(即深度为1)的所有状态的fail值都为0。
- 然后设当前状态是S1,求fail(S1)。我们知道,S1的前一状态必定是唯一的(刚才说的一对一),设S1的前一状态是S2,S2转换到S1的条件为接受字符C,测试S3 = goto(fail(S2), C)。
- 如果成功,则fail(S1) = goto(fail(S2), C) = S3。
- 如果不成功,继续测试S4 = goto(fail(S3), C)是否成功,如此重复,直到转换到某个有效的状态Sn,令fail(S1) = Sn。

算法实现
# -*- encoding=utf-8 -*-
__all__ = ['Ahocorasick', ]
class Node(object):
def __init__(self):
self.next = {}
self.fail = None
self.isWord = False
class Ahocorasick(object):
def __init__(self):
self.__root = Node()
def addWord(self, word):
'''
@param word: add word to Tire tree
添加关键词到Tire树中
'''
tmp = self.__root
for i in range(0, len(word)):
if not tmp.next.has_key(word[i]):
tmp.next[word[i]] = Node()
tmp = tmp.next[word[i]]
tmp.isWord = True
def make(self):
'''
build the fail function
构建自动机,失效函数
'''
tmpQueue = []
tmpQueue.append(self.__root)
while(len(tmpQueue) > 0):
temp = tmpQueue.pop()
p = None
for k, v in temp.next.items():
if temp == self.__root:
temp.next[k].fail = self.__root
else:
p = temp.fail
while p is not None:
if p.next.has_key(k):
temp.next[k].fail = p.next[k]
break
p = p.fail
if p is None :
temp.next[k].fail = self.__root
tmpQueue.append(temp.next[k])
def search(self, content):
'''
@return: a list of tuple,the tuple contain the match start and end index
'''
p = self.__root
result = []
startWordIndex = 0
endWordIndex = -1
currentPosition = 0
while currentPosition < len(content):
word = content[currentPosition]
# 检索状态机,直到匹配
while p.next.has_key(word) == False and p != self.__root:
p = p.fail
if p.next.has_key(word):
if p == self.__root:
# 若当前节点是根且存在转移状态,则说明是匹配词的开头,记录词的起始位置
startWordIndex = currentPosition
# 转移状态机的状态
p = p.next[word]
else:
p = self.__root
if p.isWord:
# 若状态为词的结尾,则把词放进结果集
result.append((startWordIndex, currentPosition))
currentPosition += 1
return result
def replace(self, content):
replacepos = self.search(content)
result = content
for i in replacepos:
result = result[0:i[0]] + (i[1] - i[0] + 1) * u'*' + content[i[1] + 1:]
return result
if __name__ == '__main__':
ah = Ahocorasick()
text = raw_input("text: ")
patterns = raw_input("pattern: ")
words = patterns.split(" ")
for w in words:
ah.addWord(w)
ah.make()
results = ah.search(text)
print results
if len(results) == 0:
print "No find."
else:
print len(results)," matching results are listed below."
print "-------" + "-"*len(text) + "-------"
print text
count = 0
for site in results:
w = text[site[0]:site[1]+1]
count += 1
print " "*site[0] + w + " "*(len(text)-site[1]) + " " + str(site[0]) + " " + str(count)
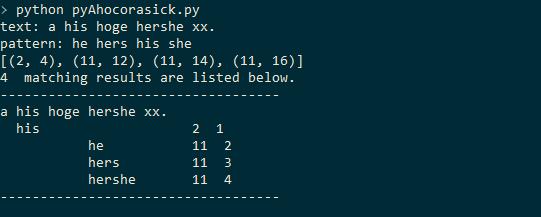
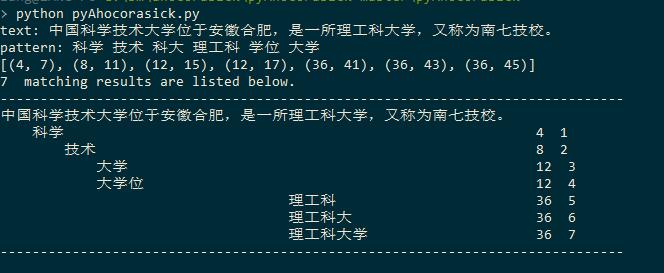
print "-------" + "-"*len(text) + "-------"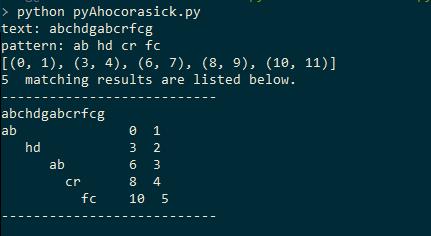















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









