









已经过时
PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" ./bin/pyspark
即可
参考:http://blog.jobbole.com/86232/
测试sparkpython
在sparkhome下run-tests测试
在Spark中使用IPython Notebook
当搜索有用的Spark小技巧时,我发现了一些文章提到在PySpark中配置IPython notebook。IPython notebook对数据科学家来说是个交互地呈现科学和理论工作的必备工具,它集成了文本和Python代码。对很多数据科学家,IPython notebook是他们的Python入门,并且使用非常广泛,所以我想值得在本文中提及。
这里的大部分说明都来改编自IPython notebook: 在PySpark中设置IPython。但是,我们将聚焦在本机以单机模式将IPtyon shell连接到PySpark,而不是在EC2集群。如果你想在一个集群上使用PySpark/IPython,查看并评论下文的说明吧!
1.为Spark创建一个iPython notebook配置
~$ ipython profile create spark
[ProfileCreate] Generating default config file: u'$HOME/.ipython/profile_spark/ipython_config.py'
[ProfileCreate] Generating default config file: u'$HOME/.ipython/profile_spark/ipython_notebook_config.py'
[ProfileCreate] Generating default config file: u'$HOME/.ipython/profile_spark/ipython_nbconvert_config.py'
记住配置文件的位置,替换下文各步骤相应的路径:
创建文件$HOME/.ipython/profile_spark/startup/00-pyspark-setup.py,并添加如下代码:
import os
import sys
# Configure the environment
if 'SPARK_HOME' not in os.environ:
os.environ['SPARK_HOME'] = '/srv/spark'
# Create a variable for our root path
SPARK_HOME = os.environ['SPARK_HOME']
# Add the PySpark/py4j to the Python Path
sys.path.insert(0, os.path.join(SPARK_HOME, "python", "build"))
sys.path.insert(0, os.path.join(SPARK_HOME, "python"))3.使用我们刚刚创建的配置来启动IPython notebook。
~$ ipython notebook --profile spark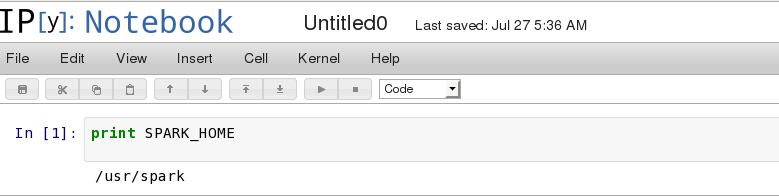
4.在notebook中,你应该能看到我们刚刚创建的变量。
print SPARK_HOME5.在IPython notebook最上面,确保你添加了Spark context。
from pyspark import SparkContext
sc = SparkContext( 'local', 'pyspark')报错!!
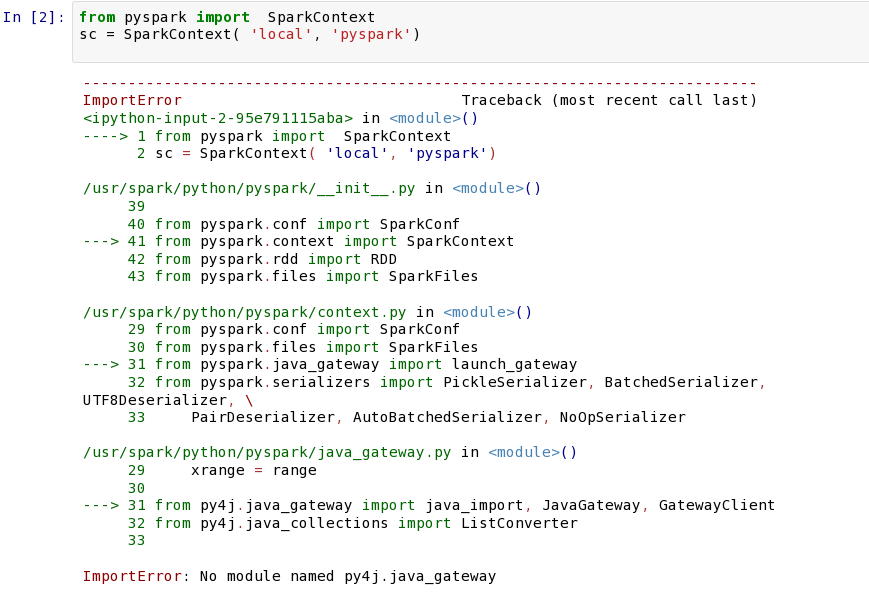
安装:(要安装easyinstallhttp://blog.csdn.net/sadfasdgaaaasdfa/article/details/47070583)
[root@localhost ~]# easy_install py4j还需要设置环境变量
参考自:http://stackoverflow.com/questions/27610367/pyspark-importerror-cannot-import-name-accumulators
PYTHONPATH=/usr/spark/python/lib/py4j-0.8.2.1-src.zip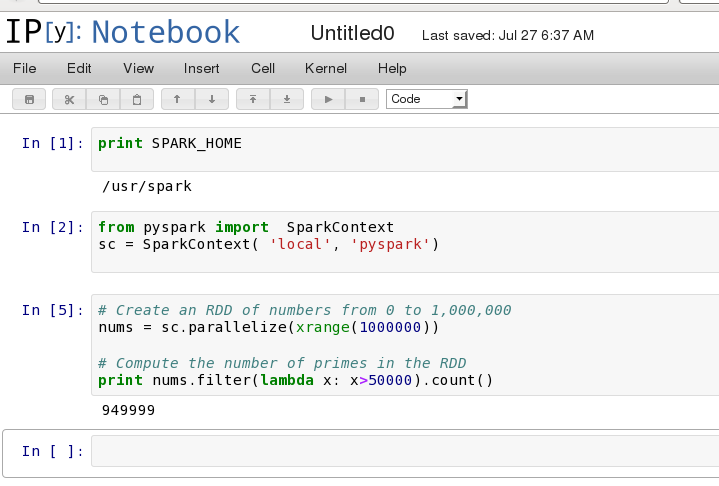
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









