







以前看过堆排序的相关内容,也编写过堆排序的代码,但此次coding时还是不能一气呵成,CSDN的知名博主:结构之法,算法之道在写快速排序的相关文章时认为这是对算法的来龙去脉不了解,但我不这么认为,我认为之所以不能熟练的最根本原因是不经常使用,当然这样一个排序算法也不可能经常编写。那么除此之外的另一个原因我认为是没有深刻的总结。而本文就是我对自己编写过堆排序之后的想法总结。
首先还是不能免俗,既然是堆排序,那么什么是堆?
堆的定义为:n个元素序列{k1,k2,***,kn}当且仅当满足如下关系时,称之为堆。
最小堆:ki <= k2i && ki <= k2i+1
最大堆:ki >= k2i && ki >= k2i+1
堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要大于其孩子,最小堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求。
什么是堆排序呢?
如果将堆顶的最小值(最大值)输出后,将剩余的 n-1 个元素重新建成一个堆,则得到 n 个元素的次小值,如此反复便能得到一个有序序列,这个过程称之为为堆排序。
因此堆排序需要解决两个问题:
第一:如何又一个无需序列建成一个堆?
第二:如何在取走堆顶元素后,调整剩余元素重新建成一个堆?
以下是我编写的堆排序的代码(代码中函数和变量的命名还不是很规范,以后修改。以后会严格按照Java中的命名规范,因为我发现Java写出的代码可读性很强)。
void adjust_heap(int *input, int root, int size)
{
int swap=0;
int left=2*root+1;
int right=2*root+2;
int largest=root;
while(root<size)
{
if((left<size) || (right<size))
{
if((left<size) && (input[largest]<input[left]))
{
largest=left;
}
if((right<size) && (input[largest]<input[right]))
{
largest=right;
}
}
if(largest!=root)
{
swap=input[largest];
input[largest]=input[root];
input[root]=swap;
left=2*largest+1;
right=2*largest+2;
root=largest;
}
else
{
break;
}
}
}
void build_maxheap(int *input,int size)
{
int i=0;
int lastend_root=size/2-1;
for(i=lastend_root;i>=0;i--)
{
adjust_heap(input,i,size);
}
}
void heap_sort(int *input,int size)
{
int swap=0;
build_maxheap(input,size);
while(size>1)
{
swap=input[0];
input[0]=input[size-1];
input[size-1]=swap;
size--;
adjust_heap(input,0,size);
}
}
算法的步骤:
1 首先从第一个非叶子节点开始,比较当前节点和其孩子节点,将最大的元素放在当前节点(当前节点为倒数第三层及上层的节点,调整时会破坏下层的已经调整好的堆, 需要递归调整)。
2 将当前元素前面所有的元素都进行1的过程,这样就生成了最大堆。
3 将堆顶元素和最后一个元素交换,列表长度减1。
4 剩余元素重新调整建堆。
5 继续3和4,直到所有元素都完成排序。即为升序排列。
coding时感觉很纠结或是值的注意的点如下:
第一:首先是建堆,在建堆时碰到的一个问题就是编号问题,到底是从“1”开始编号还是从“0”开始编号呢?
如果从“1”开始编号,那么size/2就是正确的编号,很好理解。但是最终是跟数组结合就会很麻烦。
如果从“0”开始编号,那么size/2-1才是正确的编号,便于后续和数组结合,但是和以前学习树时的习惯:i节点的左右孩子分别是 2*i 和 2*i+1 不符合,猛的下不习惯,因为从“0”开始编号的话其左右孩子的分别是:2*i+1和 2*i+2。
综合考虑之后还是从按照从“0”编号的方式后续编码更方便和习惯。
第二:还是在建堆时,建堆的过程同时也是调整堆的过程。
第三:就是一个小技巧,建堆完成后将堆顶元素和最后一个元素交换位置,同时将数组size减1。如果你想实现从小到大的排序,那么你就建立最大堆,反之,建立最小堆。
第四:adjust_heap函数中是记录下父节点,左孩子,右孩子中最大值的位置,然后判断最大值的位置和父节点的位置不相同时再交换位置,这样就只交换一次位置即可,如果直接交换位置,不仅代码复杂,而且极可能需要两次位置的交换(自己犯的错误)。
第五:建堆是一个自底向上的过程,但建堆时自底向上的每一步都需要调整堆(adjust_heap),而调整堆(adjust_heap)是一个自上向下的过程(递归的过程)。
堆排序是一种选择排序,每次都选择堆中最大的元素进行排序。只不过堆排序选择元素的方法更为先进,时间复杂度更低,效率更高。建堆的图例说明如下:
(图片来自http://www.cnblogs.com/zabery/archive/2011/07/26/2117103.html)
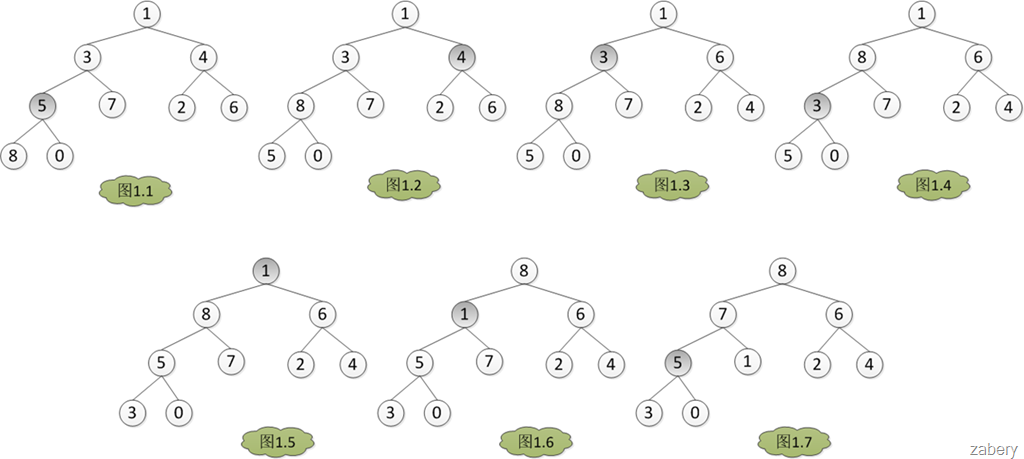
堆排序的平均时间复杂度为:O(nlogn)。排序时发生“比较”和“交换”的排序算法的极限也就是这个复杂度了。














 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









