







 本文介绍了堆排序的基本概念,包括堆数据结构的特性,如何维护最大堆和最小堆,以及堆排序算法的详细步骤。堆排序是一种原地排序算法,时间复杂度为O(nlogn),适用于处理大量数据的排序。文章还提供了堆排序的C语言实现代码,以验证算法的正确性。
本文介绍了堆排序的基本概念,包括堆数据结构的特性,如何维护最大堆和最小堆,以及堆排序算法的详细步骤。堆排序是一种原地排序算法,时间复杂度为O(nlogn),适用于处理大量数据的排序。文章还提供了堆排序的C语言实现代码,以验证算法的正确性。
堆排序是排序中一种比较重要的算法,和快速排序一样,其复杂度也是O(nlogn);同时也是一种原地排序算法:在任何时候,数组中只有常数个元素存储在输入数组以外。堆这种数据结构是处理海量数据比较常见的结构,海量数据的TOP K问题一般可以通过分治法+hash+堆这种数据结构解决。值得注意的是,这里将的“堆”准确的说是二叉堆,逻辑上是一棵类似完全二叉树的数据结构。与内存管理中提到的“堆”是两个不同的概念,后者堆内存类似链表的数据结构。下面首先介绍堆数据结构特性,然后将如何建立最大堆或最小堆,最后再讲解堆排序原理及其实现。
二叉堆数据结构在物理存储上一般表示为一种数组对象,该数组中的数据按照其逻辑结构树的广度优先算法(队列优先)来存储对应的值。树中的每个结点与数组中存放该结点值的那个元素对应。树的每一层都是填满的,最后一层可能除外(最后一层从一个结点的左子树开始填)。表示堆的数组A是一个具有两个属性的对象: length[A]是数组中元素个数, heap-size[A]是存放在A中的堆的元素个数,就是说,虽然A[0...length[A]-1]中都可以包含有效值,但A[heap-size[A] - 1]之后的元素都不属于相应的堆,此处heap-size[A] <= length[A]。接下来树的根均从A[0]开始,这里与C语言数组索引下标保持一致,索引从0开始计算。给定某个结点的下标i,其父结点PARENT(i),左儿子LEFT(i)和右儿子RIGHT(i)的下标可以简单计算出来:
#define PARENT(i) i/2
#define LEFT(i) 2*i + 1
#define RIGHT(i) 2*i + 2
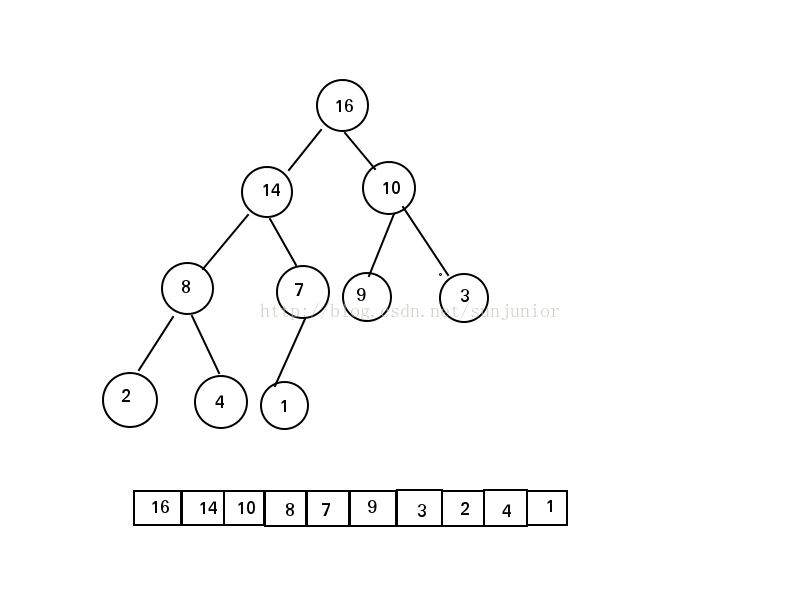
一个最大堆(大根堆)可以被看做一棵二叉树和一个数组。如上图所示,逻辑结构为二叉树,物理存储一般为数组。圆圈内的数字表示树中每个结点存储的值,结点上方的数字表示对应的数组下标。数组上下的连线表示父子关系,且父结点总在子结点的左边。图中这棵树的高度为3,存储值为8的左右孩子分别为2与4。
堆分为大根堆与小根堆。在这两种堆中,结点内数值要满足堆特性,其细节则视堆的种类而定。在最大堆中,最大堆特性指的是除了根结点之外的每个结点i,其父结点不小于其左右孩子结点。最小堆则相反,最小堆特性是指除了根以外的每个结点i,其父结点不大于其左右孩子结点。因此在最大堆中,根元素为最大值,而最小堆中,根元素为最小值。
堆可以看做一颗树,结点在堆中的高度定义为从本结点到叶子的最长简单下降路径上边的数目;定义堆的高度为树根的高度。具有n个元素的堆是基于一棵完全二叉树的,因而其高度为O(lgn)。我们将看到,堆结构上的一些基本操作的运行时间至多与树的高度成正比,为O(lgn)。
如何保持堆的特性?
MAX-HEAPIFY是对最大堆进行操作的重要的子程序。其输入为一个数组A和下标i,当MAX-HEAPIFY被调用时,我们假定以LFEF(i)和RIGHT(i)为根的两棵二叉树都是最大堆,但这时A[i]可能小于其子女,这样就违反了最大堆性质。MAX-HEAPIFY让A[i]在最大堆中“下降”,使以i为根的子树成为最大堆。
MAX-HEAPIFY(A, i)
1 l &
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









