







分区表
在Hive Select查询中,一般会扫描整个表内容,会消耗很多时间做没必要的工作。
分区表指的是在创建表时,指定partition的分区空间。
分区语法
create table tablename
name string
)
partitioned by(key type,…)
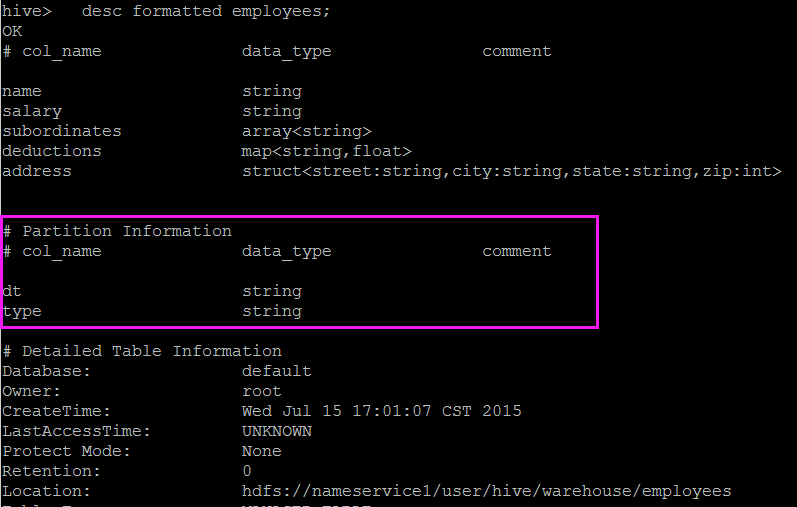
create table if not exists employees(
name string,
salary string,
subordinates array<string>,
deductions map<string,float>,
address struct<street:string,city:string,state:string,zip:int>
)
partitioned by (dt string,type string)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile
;
分区表操作
增加分区
Alter table employees add if not exists partition(country='xxx'[,state='yyyy'])Alter table employees add if not exists partition(dt='20140715',type='test');
删除分区
Alter table employees drop if exists partition(country='xxx'[,state='yyyy’)Hive分桶
对于每一个表(table)或者分区,Hive可以进一步组织成桶,也就是说捅是更为细粒度的数据范困划分。
Hive是针对某一列进行分捅。
Hive采用对列值哈希,然后除以捅的个数求余的方式决定该条记录存放在哪个桶当中。
好处
获得更高的查询处理效率。
使取样(sampling)更高效
分桶语法
create table bucketed_user(
id string ,
name string
)
clustered by (id) sorted by (name) into 4 buckets
row format delimited fields terminated by '\t'
stored as textfile;设置
set hive.enforce.bucketing = true;插入数据
insert overwrite table bucketed_user select addr ,name from testtable;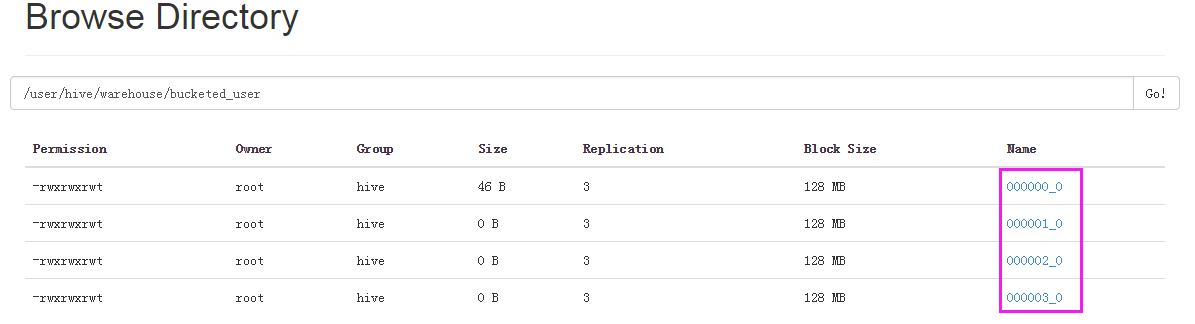
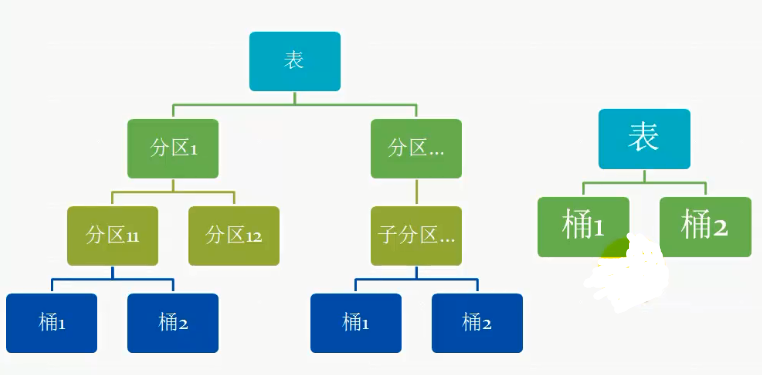
Hive分区与分桶比较
















 6221
6221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











