







0 前言:
1)Hadoop集群搭建参照前一篇博文Hadoop集群安装配置教程
2)集群有三个节点:Master、Slave1、Slave2,其中Master只作namenode,其余两个从节点做datanode
1 搭建过程中常用Hadoop指令:
1)启动Hadoop指令:
start-all.sh
mr-jobhistory-daemon.sh start historyserver启动成功过程log输出:
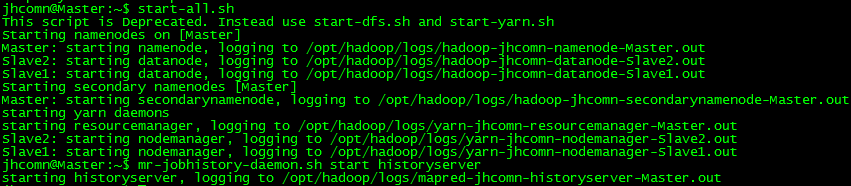
2)查看DataNode是否正常启动命令:
hdfs dfsadmin -reportshell输出:
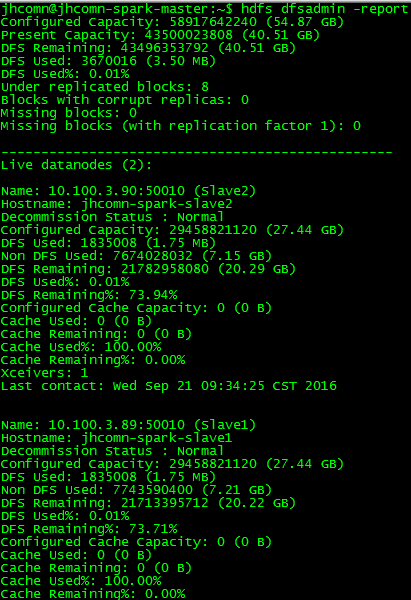
注:也可以通过web页面(http://master:50070)查看具体状态
3)创建HDFS上的用户输入输出目录:
hdfs dfs -mkdir /user/hadoop/input
hdfs dfs -mkdir /user/hadoop/output4)将文件作为输入文件复制到分布式文件系统中:
以hadoop中配置文件作为输入数据源
hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml /user/hadoop/input注:复制后可通过web页面查看DataNode的Block pool used是否有变化
5)MapReduce作业:
以wordCount为例
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-example-2.7.3.jar wordcount /user/hadoop/input /user/hadoop/output注意:在此之前,必须手动新建output目录,目录不能重复!
hdfs dfs -mkdir /user/hadoop/output6)停止Hadoop指令:
mr-jobhistory-daemon.sh stop historyserver
stop-all.sh2 配置集群以及执行mapreduce中遇到的问题及解决方案分享:
1)SSH无密码登陆子节点失败:
原因:主节点和子节点编码格式不一致
解决:统一编码格式,具体如何实现SSH无密码登陆,参照上一篇博文
2)Hadoop安装包共享问题:
解决:Windows和Linux之间文件传输可使用secureCRT软件,在linux上安装”lrzsz”即可,使用命令rz,即可实现windows上传到linux;sz则反之,具体网上有资料~
3)是否需要手动配置三次?
答案:不需要!
怎么做:先配置安装主节点的hadoop,然后压缩打包成xxx.tar.gz文件,通过指令copy到从节点上:
scp xxx.tar.gz 用户名@Slave1:~/这份文件即会出现在从节点的用户根目录下,解压配置hadoop环境变量即可
4)最蛋疼的问题!!!:执行mapreduce时,hadoop卡在Running job上,即hadoop stuck at running job
题外话:这个问题卡了我快两天的时间!各种google,参考了国内外各大神的帖子博文,最后还是得看hadoop的输出日志才对症下药,finish掉这个问题
问题现象:
网上盗的图,自己那个没记录下来。。。现象是一致的!
hadoop@ubuntu:~$ $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0.jar wordcount /myprg outputfile1
14/04/30 13:20:40 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
14/04/30 13:20:51 INFO input.FileInputFormat: Total input paths to process : 1
14/04/30 13:20:53 INFO mapreduce.JobSubmitter: number of splits:1
14/04/30 13:21:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1398885280814_0004
14/04/30 13:21:07 INFO impl.YarnClientImpl: Submitted application application_1398885280814_0004
14/04/30 13:21:09 INFO mapreduce.Job: The url to track the job: http://ubuntu:8088/proxy/application_1398885280814_0004/
14/04/30 13:21:09 INFO mapreduce.Job: Running job: job_1398885280814_0004然后打开(http://master:8088)查看Applications,发现刚提交的job一直卡在Accepted状态,并没有Running,等待许久也如此!
我碰到的原因有二:
一、内存不足引起
需要更改yarn-site.xml和mapred-site.xml的内存配置,我参考了国外的博文(http://zh.hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/)
具体修改如下:
1)yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>40960</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>2)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx3072m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx6144m</value>
</property>
</configuration>然而,我是这么做了,可是问题依旧!
二、节点/etc/hostname配置摆乌龙
于是乎,我查看了hadoop的输出日志,我查看了“yarn-用户名-resourcemanager-主机名.log”,里面的内容相当多………………
然后,我发现了问题!
2016-09-20 15:31:59,339 ERROR org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerApplicationAttempt: Error trying to assign container token and NM token to an allocated container container_1474355964293_0002_01_000001
java.lang.IllegalArgumentException: java.net.UnknownHostException: 子节点hostname
at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:377)
at org.apache.hadoop.yarn.server.utils.BuilderUtils.newContainerToken(BuilderUtils.java:258)
at org.apache.hadoop.yarn.server.resourcemanager.security.RMContainerTokenSecretManager.createContainerToken(RMContainerTokenSecretManager.java:220)
at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerApplicationAttempt.pullNewlyAllocatedContainersAndNMTokens(SchedulerApplicationAttempt.java:455)
at org.apache.hadoop.yarn.server.resourcemanager.scheduler.common.fica.FiCaSchedulerApp.getAllocation(FiCaSchedulerApp.java:269)
at org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler.allocate(CapacityScheduler.java:988)
at org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl$AMContainerAllocatedTransition.transition(RMAppAttemptImpl.java:988)
at org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl$AMContainerAllocatedTransition.transition(RMAppAttemptImpl.java:981)
at org.apache.hadoop.yarn.state.StateMachineFactory$MultipleInternalArc.doTransition(StateMachineFactory.java:385)
at org.apache.hadoop.yarn.state.StateMachineFactory.doTransition(StateMachineFactory.java:302)
at org.apache.hadoop.yarn.state.StateMachineFactory.access$300(StateMachineFactory.java:46)
at org.apache.hadoop.yarn.state.StateMachineFactory$InternalStateMachine.doTransition(StateMachineFactory.java:448)
at org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl.handle(RMAppAttemptImpl.java:806)
at org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl.handle(RMAppAttemptImpl.java:107)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$ApplicationAttemptEventDispatcher.handle(ResourceManager.java:803)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$ApplicationAttemptEventDispatcher.handle(ResourceManager.java:784)
at org.apache.hadoop.yarn.event.AsyncDispatcher.dispatch(AsyncDispatcher.java:184)
at org.apache.hadoop.yarn.event.AsyncDispatcher$1.run(AsyncDispatcher.java:110)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.net.UnknownHostException: 子节点hostname这下问题就清楚了,如何解决?很简单,配置每个节点的/etc/hostname(在ubuntu中),将Master、Slave1、Slave2分别配置在各自对应主机的/etc/hostname文件第一行,如:
Slave1
NETWORKING=yes
HOSTNAME=Slave1然后三个主机全部重启!
激动人心的时候终于要到来啦!再次执行
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-example-2.7.3.jar wordcount /user/hadoop/input /user/hadoop/output执行过程及结果:
xxx@Master:~$ hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/hadoop/input /user/hadoop/output
16/09/21 12:54:57 INFO client.RMProxy: Connecting to ResourceManager at Master/10.100.3.88:8032
16/09/21 12:54:58 INFO input.FileInputFormat: Total input paths to process : 9
16/09/21 12:54:58 INFO mapreduce.JobSubmitter: number of splits:9
16/09/21 12:54:59 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1474433568841_0001
16/09/21 12:54:59 INFO impl.YarnClientImpl: Submitted application application_1474433568841_0001
16/09/21 12:54:59 INFO mapreduce.Job: The url to track the job: http://Master:8088/proxy/application_1474433568841_0001/
16/09/21 12:54:59 INFO mapreduce.Job: Running job: job_1474433568841_0001
16/09/21 12:55:11 INFO mapreduce.Job: Job job_1474433568841_0001 running in uber mode : false
16/09/21 12:55:11 INFO mapreduce.Job: map 0% reduce 0%
16/09/21 12:55:56 INFO mapreduce.Job: map 33% reduce 0%
16/09/21 12:56:02 INFO mapreduce.Job: map 89% reduce 0%
16/09/21 12:56:03 INFO mapreduce.Job: map 100% reduce 0%
16/09/21 12:56:12 INFO mapreduce.Job: map 100% reduce 100%
16/09/21 12:56:13 INFO mapreduce.Job: Job job_1474433568841_0001 completed successfully
16/09/21 12:56:14 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=22561
FILE: Number of bytes written=1233835
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=29774
HDFS: Number of bytes written=11201
HDFS: Number of read operations=30
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=9
Launched reduce tasks=1
Data-local map tasks=9
Total time spent by all maps in occupied slots (ms)=885942
Total time spent by all reduces in occupied slots (ms)=24432
Total time spent by all map tasks (ms)=442971
Total time spent by all reduce tasks (ms)=6108
Total vcore-milliseconds taken by all map tasks=442971
Total vcore-milliseconds taken by all reduce tasks=6108
Total megabyte-milliseconds taken by all map tasks=1814409216
Total megabyte-milliseconds taken by all reduce tasks=50036736
Map-Reduce Framework
Map input records=825
Map output records=2920
Map output bytes=37672
Map output materialized bytes=22609
Input split bytes=987
Combine input records=2920
Combine output records=1281
Reduce input groups=622
Reduce shuffle bytes=22609
Reduce input records=1281
Reduce output records=622
Spilled Records=2562
Shuffled Maps =9
Failed Shuffles=0
Merged Map outputs=9
GC time elapsed (ms)=6441
CPU time spent (ms)=14050
Physical memory (bytes) snapshot=1877909504
Virtual memory (bytes) snapshot=53782507520
Total committed heap usage (bytes)=2054160384
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=28787
File Output Format Counters
Bytes Written=11201再看看web页面
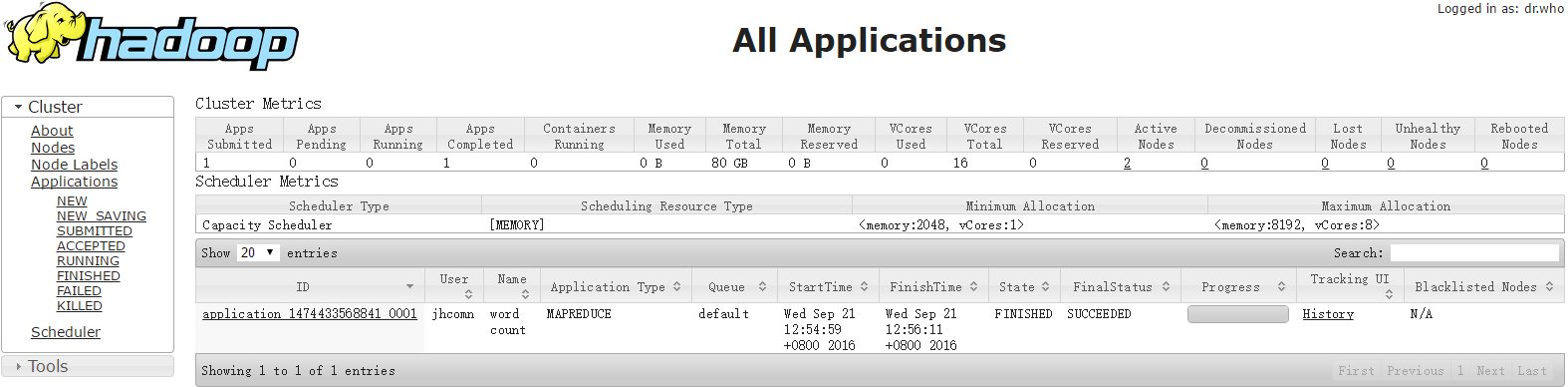
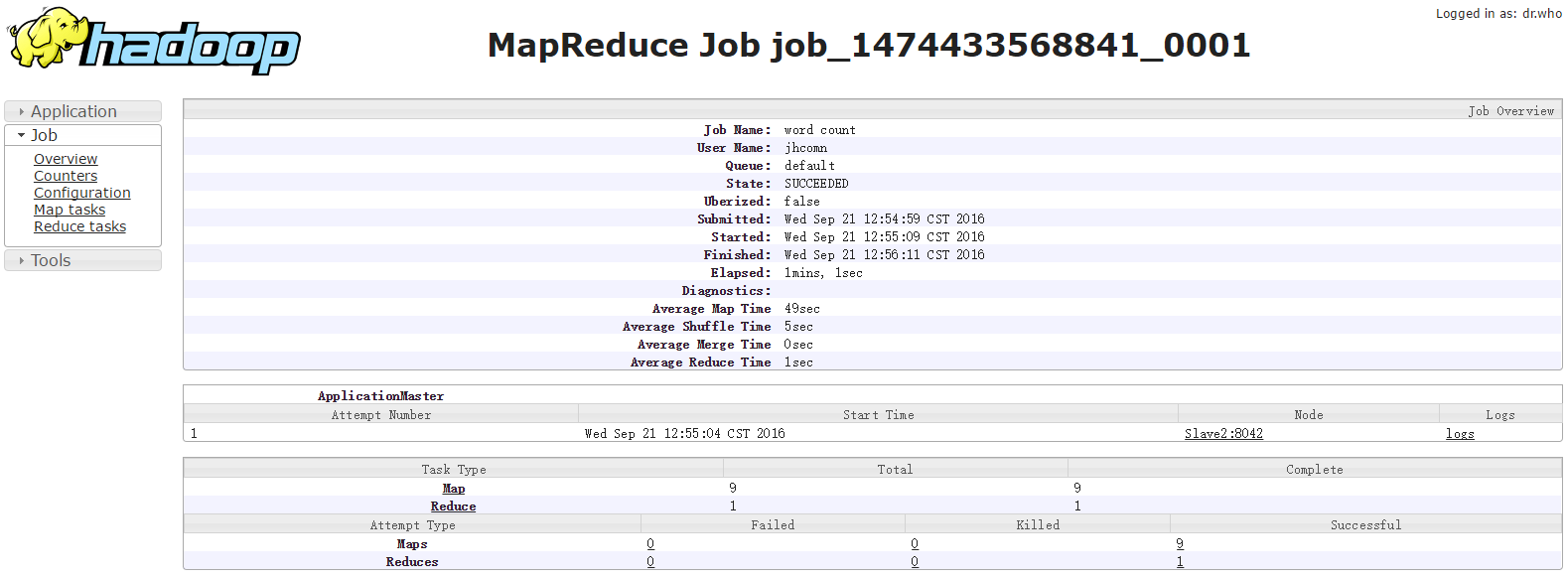
希望对大家有一点点作用~















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









