







写在前面
作为一个单体应用开发人员对于理解分布式应用和微服务的理论还可以。但是部署分布式环境来说还是一个挑战。最近在学习hadoop,正也把学习的东西分享出来,希望帮助感兴趣的人。
前面一章写了centos7搭建hadoop集群
再跟着做本章实验前建议初学者先去实验上一章的内容。有任何问题欢迎反馈,我也好做出修改。
ha(高可用)hadoop2.7.3集群,主要是为了消除spof(单点故障),解决方案有很多,但是思想相同。(如:Linux HA, VMware FT, shared NAS+NFS, BookKeeper, QJM/Quorum Journal Manager, BackupNode等),大家可以搜索响应的方案。下面我主要实现的QJM/Quorum Journal Manager方案
先期准备
| 主机 | 系统 | ip地址 | 软件 | 进程 |
|---|---|---|---|---|
| node1 | centos7 | 192.168.206.129 | jdk8+,hadoop | NameNode、DFSZKFailoverController(zkfc)、ResourceManager |
| node2 | centos7 | 192.168.206.130 | jdk8+,hadoop | NameNode、DFSZKFailoverController(zkfc)、ResourceManager |
| node3 | centos7 | 192.168.206.131 | jdk8+,hadoop,zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| node4 | centos7 | 192.168.206.132 | jdk8+,hadoop,zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| node5 | centos7 | 192.168.206.133 | jdk8+,hadoop,zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
参照上面的列表创建5台虚拟机(吐槽一下你的内存不够可不行,至少每个虚拟机1G内存),创建hadoop用户,修改每个虚拟机的静态IP、主机名、主机名与IP的映射,关闭防火墙和selinux不熟悉的参照我的centos7搭建hadoop集群
剩下的就是安装,环境变量设置,启动了,请有些耐心。
我的理解
hadoop的设计是主从分布式原理,主(namenod 简称nn)只有一个不负责记录实际数据,只记录元数据(文件描述信息),从(datanode 简称 dn)有多个用来记录实际数据。从(dn)写入数据并备份(默认3)成功后把块信息汇报个主(nn)并维持一个心跳。
所以从我的理解角度来看,数据不会出现spof。而影响整个集群是否能正常工作的地方就是主(nn),如果nn故障整个集群就瘫痪了也就是所谓的spof.
如何避免nn的spof,我的理解就是备份nn,并在其中一个nn故障时快速切换到可用的nn
要解决的问题:热备份,快速启动,防止脑裂,我所说的大家不了解的话可以网上查查。我简单说下
1. 热备份:就是要保证备份数据必须实时,不能丢失,和元数据一样
2. 快速启动:客户端感觉不出来,(因为nn启动时很慢的,根据记录的元数据多少有关)
3. 防止脑裂:hadoop集群任何时刻必须保证只有一个领导者(主nn),也就是一山不能容二虎,除非一公一母。母也就是备份 standby namenode ( snn )
QJM/Quorum Journal Manager方案:
action:表示在服务的
standby:表示不再服务,热备份中的
JN:JournalNode 存储服务中nn的状态,用来共享
zkfc:DFSZKFailoverController 健康监测 ,会话管理 ,master选举,防止脑裂
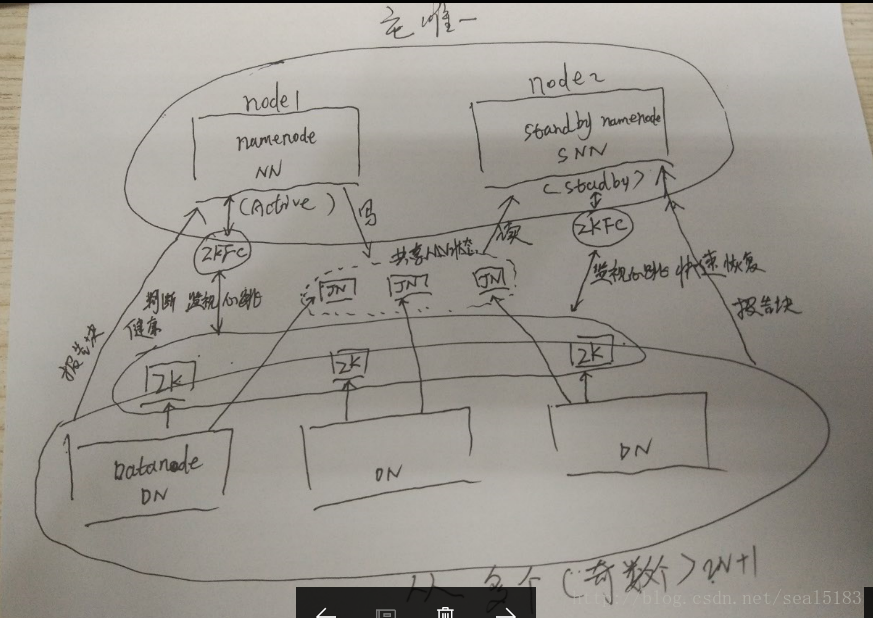
上面的东西看不明白的咱们可以讨论的
开始安装
jdk8安装
zookeeper安装在node3,node4,node5上
下载zookeeper-3.4.9.tar
如果你和我一样就解压在hadoop主题目录下
tar -xzvf zookeeper-3.4.9.tar.gz
hadoop安装在所有node上
不会安装jdk和hadoop的请看上一章
配置环境变量
# Java Environment Variables
export JAVA_HOME=/usr/java/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
# Hadoop Environment Variables
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# Zookeeper Environment Variables
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.9
export PATH=$PATH:$ZOOKEEPER_HOME/bin
zookeeper配置,node3,node4,node5
存放在zookeeper安装目录的conf目录下起名zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper 在你的主机中建立相应的目录
dataDir=/home/hadoop/zookeeper-3.4.9/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=node3:2888:3888
server.2=node4:2888:3888
server.3=node5:2888:3888在node3,node4,node5的/home/hadoop/zookeeper-3.4.9/data下创建一个myid的文件里面写一个数字 要和上面配置中的信息一直如
server.1=node3:2888:3888 表示要在node3的myid文件中写一个1的数字
server.2=node4:2888:3888表示要在node4的myid文件中写一个2的数字
server.3=node5:2888:3888表示要在node5的myid文件中写一个3的数字
hadoop ha配置,在每个node上
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>node1,node2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.node1</name>
<value>node1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.node1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.node2</name>
<value>node2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.node2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop-2.7.3/journaldata</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>slaves
node3
node4
node5启动步骤
- 先启动zookeeper服务,分别在node3,node4,node5上执行
zkServer.sh start - 启动journalnode,分别在node3,node4,node5上执行
hadoop-daemon.sh start journalnode注意只有第一次需要这么启动,之后启动hdfs会包含journalnode - 格式化HDFS,在node1上执行
hdfs namenode -format注意:格式化之后需要把tmp目录拷给node2(不然node2的namenode起不来) - 格式化ZKFC,在node1上执行
hdfs zkfc -formatZK - 启动HDFS,在node1上执行,
start-dfs.sh - 启动YARN,在node1上执行,
start-yarn.sh - node2的resourcemanager需要手动单独启动:
yarn-daemon.sh start resourcemanager
在每个节点上执行jps 如果看到内容和我上面表中的进程对应,成功,不对应以失败。欢迎讨论!!!














 7726
7726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









