








Mysql EXPLAIN
1. EXPLAIN关键词的作用
EXPLAIN 关键字可以查看表的结构、查看SELECT语句的执行过程
EXPLAIN TABLE同DESCRIBE TABLE或SHOW COLUMNS FROM TABLE查看表的字段定义信息。EXPLAIN SELECT select_query可查看SELECT语句的执行过程。
2. EXPLAIN输出参数说明
2.1 参数列表
| 参数名 | 参数含义 |
|---|---|
| id | SELECT 的标识 |
| select_type | select的类型 |
| table | 查询的数据表 |
| partitions | 匹配的分区 |
| type | join类型 |
| possible_keys | 可能的索引 |
| key | SELECT中使用到的索引 |
| key_len | 使用的索引的长度 |
| ref | 字段和索引的对应比较 |
| rows | 语句检索的记录行数 |
| filtered | 被条件过滤的数据百分比 |
| Extra | 附加信息 |
2.2 参数详细说明
id
SELECT在查询中的标识符。如果查询的数据是UNION的结果,这个值可能是NULL。在这种情况下,参数table显示的值类似<unionM,N>, M/N代表的是涉及的SELECT标识符。select_type
select_type值 含义 SIMPLE simple SELECT(没有使用UNION或者子查询) PRIMARY 最外层的查询 UNION 在UNION语句中第二个或者后边的SELECT语句 DEPENDENT UNION 在UNION语句中第二个或者后边的SELECT语句,并且依赖了外层的查询 UNION RESULT UNION的结果集 SUBQUERY 子查询中的第一个SELECT语句 DEPENDENT SUBQUERY 子查询中的第一个SELECT语句,并且依赖了外层的查询 DERIVED 有SELECT语句派生的表(在FROM子句中使用的SELECT语句) UNCACHEABLE SUBQUERY 不可缓存的查询 UNCACHEABLE UNION 不可缓存的UNION table
数据行输入设计的表的名称,还可能会出现一下两种情况:<unionM,N>union语句输出的数据,M和N是涉及的select语句的id<derivedN>数据是由派生的表输出的,N是select语句id。
partitions
查询中命中的数据分片(分区), 以后补充吧,没有使用partitions的经验type
连接类型(原文:The join type)。以下是详细说明,排列顺序从好到差:system
表只有一行数据,是const的一种特殊情况,一般不常见。const
表最多有一个匹配行,const用于比较primary key 或者unique索引。因为只匹配一行数据,所以很快记住一定是用到primary key 或者unique,并且只检索出两条数据的 情况下才会是const。比较常见。
原文:The table has at most one matching row, which is read at the start of the query. Because there is only one row, values from the column in this row can be regarded as constants by the rest of the optimizer. const tables are very fast because they are read only once.
这种类型的语句会被用做const表:
SELECT * FROM tbl_name WHERE primary_key=1; SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2;eq_ref
对于从上一个表读取出来的每行数据,在关联表中有一行数据可以进行关联。除了system和const外eq_ref是最好的join类型。索引的所有部分部分是PRIMARY KEY或UNIQUE NOT NULL就会使用这种连接类型。
翻译的不好还是看原文吧:One row is read from this table for each combination of rows from the previous tables. Other than the system and const types, this is the best possible join type. It is used when all parts of an index are used by the join and the index is a PRIMARY KEY or UNIQUE NOT NULL index.
示例语句:
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
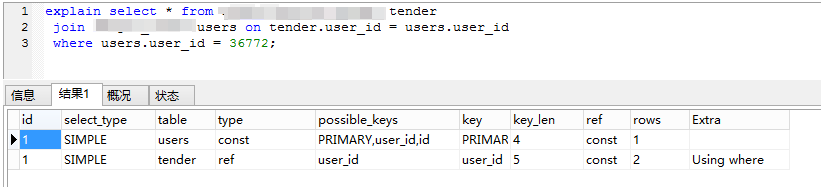
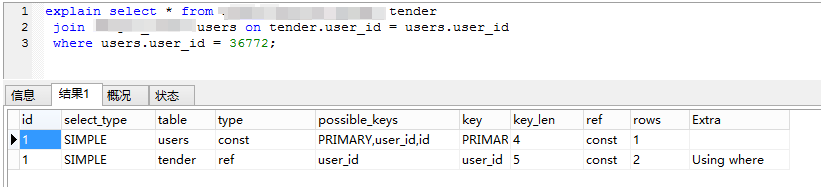
图中的示例中两个表的关联字段都是primarykey
上图的示例是使用UNIQUE索引。需要注意的是UNIQUE字段必须是NOT NULLref
对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。比较常见。
以上是抄袭,还是继续看原文吧 T^T:All rows with matching index values are read from this table for each combination of rows from the previous tables. ref is used if the join uses only a leftmost prefix of the key or if the key is not a PRIMARY KEY or UNIQUE index (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.
sql示例(官网示例):
SELECT * FROM ref_table WHERE key_column=expr; SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;fulltext
The join is performed using a FULLTEXT index.ref_or_null
类似ref,特殊处理了含有NULL值的数据行。经常用于分析子查询。
官方示例:SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;index_merge
该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。unique_subquery
在IN子查询的情况下替换ref优化器,索引字段为SUNIQUE类型如下情况:value IN (SELECT primary_key FROM single_table WHERE some_expr)index_subquery
类似unique_subquery,区别在于IN子查询可以是非唯一索引字段。range
使用过一个索引进行范围选定时使用。
当使用=,<>,>,>=,<,<=,IS NULL, <=>, BETWEEN,IN操作符与常熟比较时会使用range类型。
index
该联接类型与ALL相同,除了只有索引树被扫描。ALL
全表扫描。通常如果在连接中第一个表优化器(type)标记为const时,还不太坏。在其他情况下比较糟糕。
通常情况下ALL可以通过添加索引来优化。
Extra
这里总结一下平时常见或者比较简单的,以后碰到其他情况再补充。const row not found
类似select * rom tabletable是空的。Distinct
MySQL发现第1个匹配行后,停止为当前的行组合搜索更多的行。Full scan on NULL key
This occurs for subquery optimization as a fallback strategy when the optimizer cannot use an index-lookup access method.Impossible HAVING
HAVING条件一直为假,并且不能筛选数据。
请检查SQL语句条件限定和字段选择是否正确,或者HAVING条件是否必须。Impossible WHERE
同Impossible HAVING,针对的是where子句。Using index
语句检索了idex tree没有读取真正的数据行。查询的数据是索引列会使用此策略。
同时出现Using where表示使用该索引进行了数据的筛选。没有出现Using where表示可能只使用索引读取数据,并没有进行筛选。Using temporary
查询中需要创建一个临时表保存结果。通常发生在含有GROUP BY和ORDER BY的查询语句中。Using where
除需要进行全表检索的情况下,如果Extra中没有出现Using where并且type是ALL或index时表示你的可能编写错误了。




















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









