









Golang学习:类型
一、变量
Go语言静态类型,在运行期间是不能改变变量的类型的。下面会介绍变量的使用。
1.使用关键字var定义变量,如果后面未接初始化值会自动初始化为零值,也可以省略变量的类型由编译器自动推断。
var n int
var f float32 = 1.6
var s = "abc"2.在函数内部,可以使用更加简略的”:=”来进行定义变量。注意这里指的是定义变量,并不是修改,因此注意实在函数内部使用。
func main(){
a := 123
}3.可以一次定义多个变量。可以将它们写进var()中或使用多变量赋值。使用var对相同类型的变量定义时可以只写一次。
var c int, d int
var p, q int
var (
a int
b float32
)
func main() {
n, s := 0x1234, "Hello, World!"
println(x, s, n)
}4.使用’-‘当作变量名,用于忽略值占位。
func test() (int, string) {
return 1, "abc"
}
func main() {
_, s := test()
println(s)
}注意:
- 局部变量定义而未使用的话,编译的时候会报错,而全局变量并不会报错。
var s string // s 是全局变量不会报错。
func main() {
i := 0 // Error: i declared and not used。(可使⽤用 "_ = i" 规避)
}- 注意重新赋值与定义新同名变量的区别,在同一代码块使用‘:=’是重新赋值,而不再同一代码块则为定义。
s := "abc"
println(&s)
s, y := "hello", 20 // 重新赋值: 与前 s 在同⼀一层次的代码块中,且有新的变量被定义。
println(&s, y) // 通常函数多返回值 err 会被重复使⽤用。
{
s, z := 1000, 30 // 定义新同名变量: 不在同⼀一层次代码块。
println(&s, z)
}二、常量
变量的值必须编译器可确定数字、字符串、布尔值。它是用’const’作为关键字的,声明时用法和’var’非常相似。但是注意不能出现只声明而不赋值的情况。
const x, y int = 1, 2 // 多常量初始化
const s = "Hello, World!" // 类型推断
const ( // 常量组
a, b = 10, 100
c bool = false
)
func main() {
const x = "xxx" // 未使⽤用局部常量不会引发编译错误。
}- 在常量组,如不类型或初始化值,它与前一个常量相同
const (
a = 123
b // b = 123
)- 常量值可以是 len、cap、unsafe.Sizeof 等编译期可确定结果的函数返回值
const (
a = "abc"
b = len(a)
c = unsafe.Sizeof(b) // 查看变量所占字节数
)- 注意溢出
const (
a byte = 100 // int to byte
b int = 1e20 // float64 to int, overflows
)枚举
- 关键字 iota 定义常量中从 0 开始计数的自增枚举值
const (
Sunday = iota // 0
Monday // 1,通常省略后续行表达式。
Tuesday // 2
Wednesday // 3
Thursday // 4
Friday // 5
Saturday // 6
)
const (
_ = iota // iota = 0
KB int64 = 1 << (10 * iota) // iota = 1
MB // 与 KB 表达式相同,但 iota = 2
GB
TB
)注意MB是和KB有相同的表达式,但是iota在加一,下面的依次类推。输出的结果:
KB: 1024
MB: 1048576
GB: 1073741824
TB: 1099511627776- 在同一常量组中,可以提供多个 iota,它们各自增长。
const (
A, B = iota, iota << 10 // 0, 0 << 10
C, D // 1, 1 << 10
)- 如果 iota ⾃自增被打断,须显式恢复。注意打断过程中枚举仍然在计数。
const (
A = iota // 0
B // 1
C = "c" // c
D // c,与上⼀⾏相同。
E = iota // 4,显式恢复。注意计数包含了 C、D 两行。
F // 5
)- 可通过自定义类型来实现枚举类型限制。注意下面实例Error的地方。不可以用一个变量,只可以用定义类型常量或type等值常量编译器会对其进行转换。
type Color int
const (
Black Color = iota
Red
Blue
)
func test(c Color) {}
func main() {
c := Black
test(c)
x := 1
test(x) // Error: cannot use x (type int) as type Color in function argument
test(1) // 常量会被编译器自动转换。
}三、基本类型
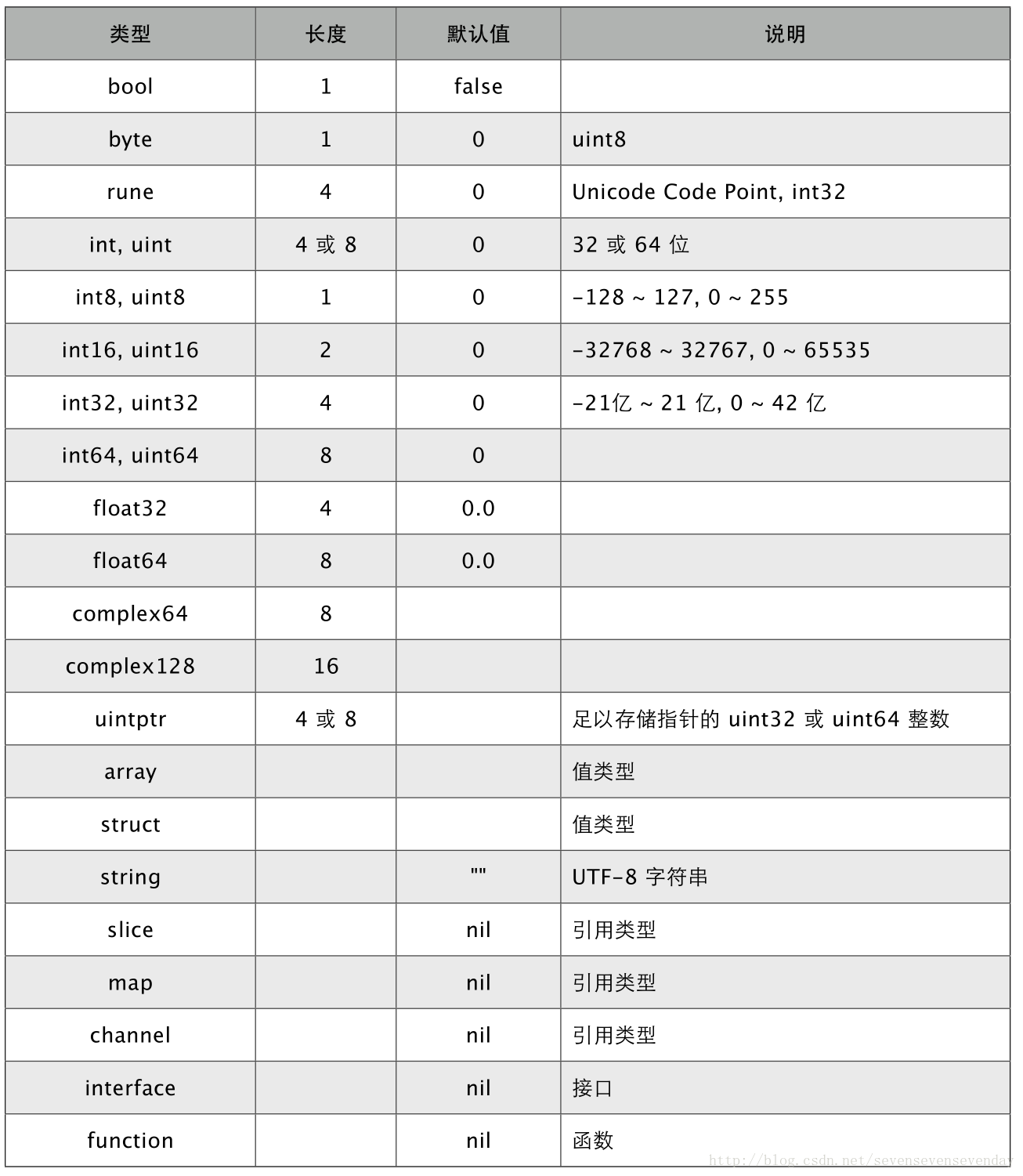
1. 整数
Go语言的整数类型一共有10个。
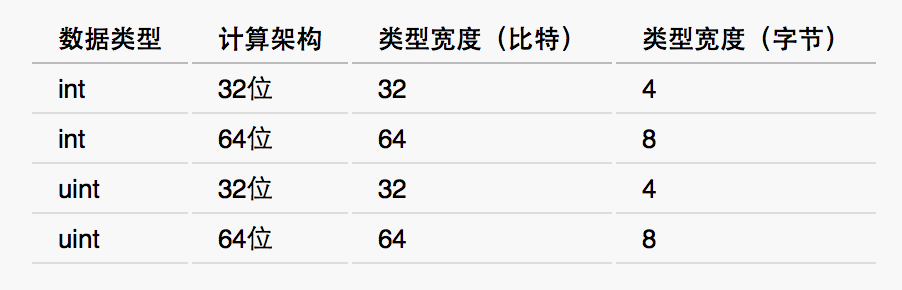
其中计算架构相关的整数类型有两个,即:有符号的整数类型int和无符号的整数类型uint。有符号的整数类型会使用最高位的比特(bit)表示整数的正负。显然,这会对它能表示的整数的范围有一定的损耗(使其缩小)。而无符号的整数类型会使用所有的比特位来表示数值。如此类型的值均为正数。这也是用“无符号的”来形容它们的原因。在不同的计算架构的计算机之上,它们体现的宽度是不同的。宽度即指存储一个某类型的值所需要的空间。空间的单位可以是比特,也可以是字节(byte)。请看下表。
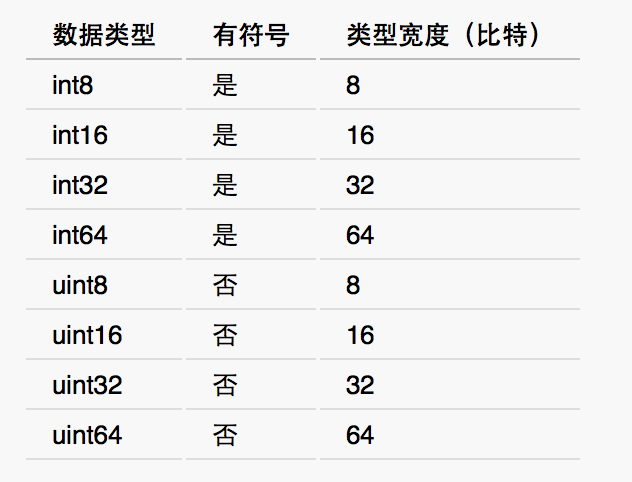
除了这两个计算架构相关的整数类型之外,还有8个可以显式表达自身宽度的整数类型。如下表所示。
2. 浮点数
浮点数类型有两个,即float32和float64。你可能已经想到,存储这两个类型的值的空间分别需要4个字节和8个字节。浮点数类型的值一般由整数部分、小数点“.”和小数部分组成。其中,整数部分和小数部分均由10进制表示法表示。不过还有另一种表示方法。那就是在其中加入指数部分。指数部分由“E”或“e”以及一个带正负号的10进制数组成。比如,3.7E-2表示浮点数0.037。又比如,3.7E+1表示浮点数37。有时候,浮点数类型值的表示也可以被简化。比如,37.0可以被简化为37。又比如,0.037可以被简化为.037。
有一点需要注意,在Go语言里,浮点数的相关部分只能由10进制表示法表示,而不能由8进制表示法或16进制表示法表示。比如,03.7表示的一定是浮点数3.7。
3. 复数类型
复数类型同样有两个,即complex64和complex128。存储这两个类型的值的空间分别需要8个字节和16个字节。实际上,complex64类型的值会由两个float32类型的值分别表示复数的实数部分和虚数部分。而complex128类型的值会由两个float64类型的值分别表示复数的实数部分和虚数部分。
复数类型的值一般由浮点数表示的实数部分、加号“+”、浮点数表示的虚数部分,以及小写字母“i”组成。比如,3.7E+1 + 5.98E-2i。正因为复数类型的值由两个浮点数类型值组成,所以其表示法的规则自然需遵从浮点数类型的值表示法的相关规则。
4. byte与rune
byte与rune类型有一个共性,即:它们都属于别名类型。byte是uint8的别名类型,而rune则是int32的别名类型。byte类型的值需用8个比特位表示,其表示法与uint8类型无异。因此我们就不再这里赘述了。我们下面重点说说rune类型。
+一个rune类型的值即可表示一个Unicode字符。Unicode是一个可以表示世界范围内的绝大部分字符的编码规范。关于它的详细信息,可以参看其官网(http://unicode.org/)上的文档,或在Google上搜索。用于代表Unicode字符的编码值也被称为Unicode代码点。一个Unicode代码点通常由“U+”和一个以十六进制表示法表示的整数表示。例如,英文字母“A”的Unicode代码点为“U+0041”。rune类型的值需要由单引号“’”包裹。
补充:Go 八进制、十六进制,以及科学计数法。标准库 math 定义了各种数字类型的取值范围。
a, b, c, d := 071, 0x1F, 1e9, math.MinInt16
输出结果:
a: 57
b: 31
c: 1e+09
d: -32768Go 空指针的值为nil 在C/C++ 是 NULL
四、引用类型
引用类型包括 slice、map、channel。他们又复杂的内部结构,除了申请内存外还要初始化相关属性。
内置函数 new 计算类型大小,为其分配零值内存,返回指针。而 make 会被编译器翻译成具体的创建函数,由其分配内存和初始化成员结构,返回对象而非指针。
a := []int{0, 0, 0} // 提供初始化表达式。
a[1] = 10
b := make([]int, 3) // makeslice
b[1] = 10
c := new([]int)
c[1] = 10 // Error: invalid operation: c[1] (index of type *[]int)五、类型转换
- 不支持隐式类型转换,即便是从窄向宽转换也不行。
var b byte = 100
// var n int = b // Error: cannot use b (type byte) as type int in assignment
var n int = int(b) // 显式转换- 使用括号避免优先级错误。
*Point(p) // 相当于 *(Point(p))
(*Point)(p)
<-chan int(c) // 相当于 <-(chan int(c))
(<-chan int)(c)- 同样不能其他类型当bool 值使用。
a := 100
if a { // Error: non-bool a (type int) used as if condition
println("true")
}六、字符串
字符串是不可变值类型,内部⽤用指针指向 UTF-8 字节数组。
- 默认值是空字符串 “”。
- 用索引号访问某字节,如 s[i]。
- 不能用序号获取字节元素指针,&s[i] 非法。
- 不可变类型,无法修改字节数组。
runtime.h
struct String
{
byte* str;
intgo len;
};- 使用索引号访问字符(byte)。
s := "abc"
println(s[0] == '\x61', s[1] == 'b', s[2] == 0x63)输出结果:
true true true- 使用“`”定义不做转义处理的原是字符串,支持跨行。
s := `a
b\r\n\x00
c`
println(s)输出:
a
b\r\n\x00
c- 连接跨行字符串时,“+”必须在上一行的行末,否则导致编译错误。
s := "Hello, " +
"World!"
s2 := "Hello, "
+ "World!" // Error: invalid operation: + untyped string- 支持用两个索引号返回子串。子串依然指向原字节数组,仅修改了指针和长度属性。
s := "Hello, World!"
s1 := s[:5] // Hello
s2 := s[7:] // World!
s3 := s[1:5] // ello- 单引号字符常量表示 Unicode Code Point,支持\uFFFF、\U7FFFFFFF、\xFF格式。对应rune类型,UCS-4。rune是int32的别名。
func main() {
fmt.Printf("%T\n", 'a')
var c1, c2 rune = '\u6211', '们'
println(c1 == '我', string(c2) == "\xe4\xbb\xac")
}输出结果:
int32
true true- 要修改字符串可以先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func main() {
s := "abcd"
bs := []byte(s)
bs[1] = 'B'
println(string(bs))
u := "电脑"
us := []rune(u)
us[1] = '话'
fmt.Println(string(us))
}输出结果:
aBcd
电话- 用for循环遍历字符串时,也有byte和rune两种方式。
func main() {
s := "abc汉字"
for i := 0; i < len(s); i++ { // byte
fmt.Printf("%c,", s[i])
}
fmt.Println()
for _, r := range s { // rune
fmt.Printf("%c,", r)
}
}输出结果: 注 这是在32位机器下编译运行的结果
a,b,c,æ,±,‰,å,,—,
a,b,c,汉,字,七、指针
支持指针类型 T,指针的指针 **T,以及包含包前缀的 < package>.T。
- 默认值nil,没有NULL常量。
- 操作符“&”取变量地址,“*”通过指针访问目标对象。
- 不支持指针运算,不支持“->”运算,直接用“.”访问目成员。
func main() {
type data struct{ a int }
var d = data{1234}
var p *data
p = &d
fmt.Printf("%p, %v\n", p, p.a) // 直接用指针访问目标对象成员,无须转换。
}输出结果:
0x115b00cc, 1234- 不能对指针做加减法等运算。
x := 1234
p := &x
p++ /// Error: invalid operation: p += 1 (mismatched types *int and int)- 可以在unsafe.Pointer和任意类型指针间进行转换。注意引入
unsafe包
func main() {
x := 0x12345678
p := unsafe.Pointer(&x) // *int -> Pointer
n := (*[4]byte)(p) // Pointer -> *[4]byte
for i := 0; i < len(n); i++ {
fmt.Printf("%X ", n[i])
}
}输出结果:
78 56 34 12- 返回局部变量指针是安全的,编译器会根据需要将其分配在GC Heap上。
func test() *int {
x := 100
return &x // 在堆上分配 x 内存。但在内联时,也可能直接分配在目标栈。
}- 将Pointer转换成uintptr,可变相实现指针运算。
func main() {
d := struct {
s string
x int
}{"abc", 100}
p := uintptr(unsafe.Pointer(&d)) // *struct -> Pointer -> uintptr
p += unsafe.Offsetof(d.x) // uintptr + offset
p2 := unsafe.Pointer(p) // uintptr -> Pointer
px := (*int)(p2) // Pointer -> *int
*px = 200 // d.x = 200
fmt.Printf("%#v\n", d)
}输出结果:
struct { s string; x int }{s:"abc", x:200}注意:GC将uintptr当成普通整数对象,它无法阻止“关联”对象被回收。
八、自定义类型
可将类型分为命名和未命名两大类。命名类型包括bool、int、string等,而array、slice、map等和具体元素类型、长度有关,属于未命名类型。
具有相同声明的未命名类型被视为同一类型。
- 具有相同基类型的指针。
- 具有相同元素类型和长度的array。
- 具有相同元素类型的slice。
- 具有相同键值类型的map。
- 具有相同元素类型和传送方向的channel。
- 具有相同字段序列(字段名、类型、标签、顺序)的匿名struct。
- 签名相同(参数和返回值,不包括参数名称)的function。
- 方法集相同(方法名、方法签名相同,和次序无关)的interface。
var a struct { x int `a` }
var b struct { x int `ab` }
// cannot use a (type struct { x int "a" }) as type struct { x int "ab" } in assignment
b = a- 可用type在全局或函数内定义新类型。
func main() {
type bigint int64
var x bigint = 100
println(x)
}- 新类型不是原类型的别名,除了拥有相同的数据存储结构外,它们之间没有任何关系,不会持有原类型任何信息。除非目标类型是未命名类型,否则必须显式转换。
x := 1234
var b bigint = bigint(x) // 必须显式转换,除非是常量。
var b2 int64 = int64(b)
var s myslice = []int{1, 2, 3} // 未命名类型,隐式转换。
var s2 []int = s九、总结
本部分,简要介绍了Go 语言的数据类型。注意它们与我们C语言数据类型的差异,能够更好的理解和掌握它们。















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









