






1.单链表的整表创建
顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。而单链表和顺序存储结构就不一样,他不像顺序存储结构那么集中,他可以很分散,是一种动态结构。对于每个链表来说,它所占用空间的大小和位置是不需要预先分配划定的,可以根据系统的情况和实际的需求即时生成。
所以,创建单链表的过程就是一个动态生成链表的过程。即从“空表”的初始状态起,一次建立各元素结点,并逐个插入链表。
单链表整表创建的算法思路:
(1)声明一节点p和计数器变量i;
(2)初始化一空链表L;
(3)让L的头结点的指针指向NULL,即建立一个带头结点的单链表;
(4)循环:生成一新结点赋值给P; 随机生成一数字赋值给p的数据域p->data; 将p插入到头结点与前一个新节点之间(头插法)。
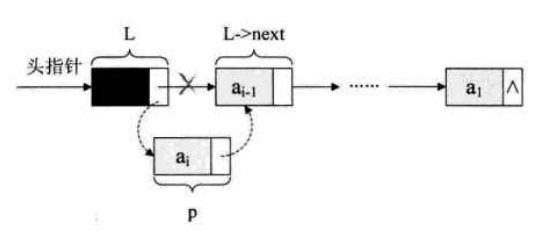
头插法实现代码算法:
事实上,我们也可以不这样做。为什么不把新节点都放在最后呢?这种应该说才是排队的正常思维,及先来后到。这种方法又称为“尾插法”。

实现代码算法如下:
void CteateListTail( LinkList* L, int n)
{
LinkList p,r;
int i;
srand( time(0) );
*L = (LinkList) malloc ( sizeof(Node) );
r = *L;
for (i=0; i<n; i++)
{
p = (Node*)malloc( sizeof (Node) );
p->data = rand()%100+1;
r->next = p;
r = p; //保证r代表最后的结点
}
r->next = NULL;
}
2.单链表的整表删除
当我们不打算使用这个单链表时,我们需要把它销毁,其实也就是在内存中将他释放掉,以便于留出空间给其他程序或软件使用。
单链表整表删除的算法思路如下:
(1)声明一结点p和q;
(2)将第一个结点赋值给p;
(3)循环:将下一个结点赋值给q,释放p,将q赋值给p。
实现代码算法如下:
3.单链表结构与顺序存储结构优缺点
| | 单链表结构 | 顺序存储结构 |
| 存储分配方式 | 采用链式存储结构,用一组任意的存储单元存放线性表元素 | 用一段连续的存储单元一次存储线性表的数据元素 |
| 时间性能 | 查找:O(n) | 查找:O(1) |
| 空间性能 | 不需要分配存储空间,只要有就可以分配,元素个数也不受限制 | 需要预分配存储空间,分配大了,浪费,分配小了,易发生上溢 |
经验性的结论:
4.循环链表
对于单链表,由于每个结点只存储向后的指针,到了尾标志就停止了向后的操作。这样,当中某一节点就无法找到它的前驱结点,难以查阅前方数据。
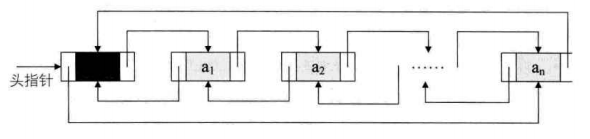
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个链表形成一个环,这种头尾项链的单链表称为单循环链表,简称循环链表。

其实,循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p->next = NULL??,现在则是判断p->next是不是等于头结点,若不等于,则循环未结束。
在单链表中,我们有了头结点时,我们可以用O(1)的时间访问第一个结点,但是对于要访问的最后一个结点,却要用O(n)时间,因为我们需要将单链表全部扫描一遍。
有没有可能用O(1)的时间由链表指针访问到最后一个结点呢?当然可以,不过我们需要改造一下这个循环链表,不用头指针,而是用指向终端结点的尾指针来表示循环链表。

此时,查找开始结点和终端结点就很方便了。如果终端结点用尾指针rear指示,则查找终端节点是O(1),而开始结点,其实就是rear->next->next,其时间复杂度也为O(1)。
5.双向链表
在单链表中,有了next指针,这就使得我们要查找下一节点的时间复杂度为O(1)。可是,如果我们要查找的是上一节点的话,那最坏的时间复杂度就是O(n),因为我们每次都要从头开始遍历查找。
为了克服链表单向性这一弊端,相关研究人员设计了双向链表。双向链表是在单链表的每个节点中,在设置一个指向其前驱结点的指针域。所以,在双向链表中的结点都有两个指针域,一个是指向直接后继,一个是指向直接前驱。















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









